SPARK 2.2.1 SQL处理各种数据源的案例与解读
SPARK 2.2.1 SQL 处理各种数据源的案例与解读
由于集团下的各个子公司在数据集成之前,使用数据有多种格式,因此需要支持多种数据来源的处理,将各个子公司的不同数据源集成到集团统一的大数据平台下。Spark SQL支持从各种数据源加载文件构建DataFrame/DataSet,以及将DataFrame/DataSet 保存到各种数据源中。
在给出数据源实战案例之前,先对Spark SQL的数据源进行分析,下面是从源码角度,对内置的数据源、数据源的查找两个方面进行分析。
1) 数据源分析
查看源码,可以从任何一个加载数据源的接口触发,最后找到解析数据源的代码,这里数据源的源码在DataSource.scala文件中,相关代码如下所示。
DataSource.scala源代码:
1. object DataSource extendsLogging {
2.
3. /** A map to maintain backward compatibilityin case we move data sources around. */
4. private val backwardCompatibilityMap:Map[String, String] = {
5. val jdbc =classOf[JdbcRelationProvider].getCanonicalName
6. val json =classOf[JsonFileFormat].getCanonicalName
7. val parquet =classOf[ParquetFileFormat].getCanonicalName
8. val csv =classOf[CSVFileFormat].getCanonicalName
9. val libsvm ="org.apache.spark.ml.source.libsvm.LibSVMFileFormat"
10. val orc = "org.apache.spark.sql.hive.orc.OrcFileFormat"
11.
12. Map(
13. "org.apache.spark.sql.jdbc"-> jdbc,
14. "org.apache.spark.sql.jdbc.DefaultSource"-> jdbc,
15. "org.apache.spark.sql.execution.datasources.jdbc.DefaultSource"-> jdbc,
16. "org.apache.spark.sql.execution.datasources.jdbc"-> jdbc,
17. "org.apache.spark.sql.json"-> json,
18. "org.apache.spark.sql.json.DefaultSource"-> json,
19. "org.apache.spark.sql.execution.datasources.json"-> json,
20. "org.apache.spark.sql.execution.datasources.json.DefaultSource"-> json,
21. "org.apache.spark.sql.parquet"-> parquet,
22. "org.apache.spark.sql.parquet.DefaultSource"-> parquet,
23. "org.apache.spark.sql.execution.datasources.parquet"-> parquet,
24. "org.apache.spark.sql.execution.datasources.parquet.DefaultSource"-> parquet,
25. "org.apache.spark.sql.hive.orc.DefaultSource"-> orc,
26. "org.apache.spark.sql.hive.orc"-> orc,
27. "org.apache.spark.ml.source.libsvm.DefaultSource"-> libsvm,
28. "org.apache.spark.ml.source.libsvm"-> libsvm,
29. "com.databricks.spark.csv"-> csv
30. )
31. }
Spark SQL内置的数据源支持缩写方式,包含”jdbc”、”json”、”parquet”、”csv”、”libsvm”、”orc”这六种。
2) 通过数据源查找的源码,查找时可以指定数据源类名的全路径的前缀。
1. def lookupDataSource(provider: String):Class[_] = {
2. val provider1 = backwardCompatibilityMap.getOrElse(provider,provider)
3. val provider2 =s"$provider1.DefaultSource"
4. val loader =Utils.getContextOrSparkClassLoader
5. val serviceLoader =ServiceLoader.load(classOf[DataSourceRegister], loader)
6.
7. try {
8. serviceLoader.asScala.filter(_.shortName().equalsIgnoreCase(provider1)).toListmatch {
9. // the provider format did not matchany given registered aliases
10. case Nil =>
11. try {
12. Try(loader.loadClass(provider1)).orElse(Try(loader.loadClass(provider2)))match {
13. case Success(dataSource) =>
14. // Found the data source usingfully qualified path
15. dataSource
16. case Failure(error) =>
17. if(provider1.toLowerCase(Locale.ROOT) == "orc" ||
18. provider1.startsWith("org.apache.spark.sql.hive.orc")){
19. throw new AnalysisException(
20. "The ORC data sourcemust be used with Hive support enabled")
21. } else if(provider1.toLowerCase(Locale.ROOT) == "avro" ||
22. provider1 =="com.databricks.spark.avro") {
23. throw new AnalysisException(
24. s"Failed to find datasource: ${provider1.toLowerCase(Locale.ROOT)}. " +
25. "Please find an Avropackage at " +
26. "http://spark.apache.org/third-party-projects.html")
27. } else {
28. throw newClassNotFoundException(
29. s"Failed to find datasource: $provider1. Please find packages at " +
30. "http://spark.apache.org/third-party-projects.html",
31. error)
32. }
33. }
34. } catch {
35. case e: NoClassDefFoundError =>// This one won't be caught by Scala NonFatal
36. // NoClassDefFoundError's classname uses "/" rather than "." for packages
37. val className =e.getMessage.replaceAll("/", ".")
38. if(spark2RemovedClasses.contains(className)) {
39. throw new ClassNotFoundException(s"$classNamewas removed in Spark 2.0. " +
40. "Please check if yourlibrary is compatible with Spark 2.0", e)
41. } else {
42. throw e
43. }
44. }
45. case head :: Nil =>
46. // there is exactly one registeredalias
47. head.getClass
48. case sources =>
49. // There are multiple registeredaliases for the input. If there is single datasource
50. // that has"org.apache.spark" package in the prefix, we use it considering it isan
51. // internal datasource within Spark.
52. val sourceNames =sources.map(_.getClass.getName)
53. val internalSources =sources.filter(_.getClass.getName.startsWith("org.apache.spark"))
54. if (internalSources.size == 1) {
55. logWarning(s"Multiple sourcesfound for $provider1 (${sourceNames.mkString(", ")}), " +
56. s"defaulting to the internaldatasource (${internalSources.head.getClass.getName}).")
57. internalSources.head.getClass
58. } else {
59. throw newAnalysisException(s"Multiple sources found for $provider1 " +
60. s"(${sourceNames.mkString(",")}), please specify the fully qualified class name.")
61. }
62. }
63. } catch {
64. case e: ServiceConfigurationError ife.getCause.isInstanceOf[NoClassDefFoundError] =>
65. // NoClassDefFoundError's class nameuses "/" rather than "." for packages
66. val className =e.getCause.getMessage.replaceAll("/", ".")
67. if (spark2RemovedClasses.contains(className)){
68. throw newClassNotFoundException(s"Detected an incompatible DataSourceRegister." +
69. "Please remove theincompatible library from classpath or upgrade it. " +
70. s"Error:${e.getMessage}", e)
71. } else {
72. throw e
73. }
74. }
75. }
当查找数据源时,会从内置支持是六种数据源中先进行查找,查找失败时,以输入的数据源类路径加类名”. DefaultSource”构建出数据源实例。
可以通过继承特质RelationProvider来自定义数据源类来扩展Spark SQL,现有的继承类如图3-1所示。
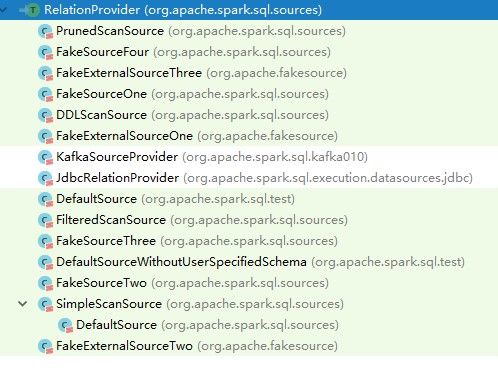
图 3 - 1 Spark SQL数据源的DefaultSource类
保存功能的案例与解读
Spark SQL提供了两种方式从各种数据源加载数据构建DataFrame/DataSet,可以使用特定的方法或通用的方法以默认的数据源,来直接加载数据源,也可以通过指定具体数据源的方法,用通用的方法来加载数据。
同时Spark SQL也提供DataFrame/DataSet的持久化操作。
本节以Spark Shell交互式方式启动Spark,讲解如何加载和持久化DataFrame/DataSet。
(一) 最简单的方式
加载、保存DataFrame/DataSet的最简单的方式是使用默认的数据源来进行所有操作。默认的数据源是内置的“parquet”数据源,可以通过修改配置属性spark.sql.sources.default将其他数据源作为默认值。
1. 使用针对特定数据源的方法
这里分别给出Spark session提供的针对特定数据源加载文件的方法,包含加载方法和保存方法。
1) 加载数据源。
数据源使用Spark 2.2.1本身自带的本地数据源文件examples/src/main/resources/people.json,people.json数据源文件包括姓名、年龄两列,内容如下:
root@master:~# cat/usr/local/spark-2.2.1-bin-hadoop2.6/examples/src/main/resources/people.json
{"name":"Michael"}
{"name":"Andy","age":30}
{"name":"Justin","age":19}
在HDFS文件系统中新建/resources目录,将文件examples/src/main/resources/people.json上传到HDFS文件系统中/resources。
root@master:~# hdfs dfs -mkdir /resources
root@master:~# hdfs dfs -ls /resources
root@master:~# hdfs dfs -put/usr/local/spark-2.2.1-bin-hadoop2.6/examples/src/main/resources/people.json /resources
root@master:~# hdfs dfs -ls /resources
Found 1 items
-rw-r--r-- 3 rootsupergroup 73 2018-02-17 14:57/resources/people.json
root@master:~#
Spark 2.2.1版本的Spark Shell 默认构建了Spark context(sc)及Spark session(spark)的实例。这里使用spark.read.json方法加载people.json文件。
root@master:~#spark-shell –master spark://192.168.189.1:7077 --executor-memory 512m --
total-executor-cores4
……
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
……
scala> val people =spark.read.json("/resources/people.json")
…….
people: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) 使用people.write.parquet方法以parquet格式保存DataFrame实例到HDFS系统/resources目录下。
scala>people.write.parquet("/resources/people.parquet")
1) 使用spark.read.parquet方法加载刚才以parquet格式保存的people.parquet文件。
scala> valpeople =spark.read.parquet("/resources/people.parquet")
people:org.apache.spark.sql.DataFrame = [age: bigint, name: string]
综上,Spark可以使用spark.read.json和spark.read.parquet,分别加载”json” 和“parquet”的数据源。
可以使用people.write.parquet方法保存数据到HDFS系统,登陆HADOOP的Web Interface界面(http://192.168.189.1:50070/explorer.html#/resources),parquet文件保存结果如图3-2所示。

图 3 - 2 hadoop文件系统在people.write.parquet后的界面
2. 使用默认数据源的方法。
1) 确认默认的数据源是否已经设置。
可以通过查询当前的默认配置,确保是默认的”parquet”数据源,输入如下:
scala> sc.getConf.get("spark.sql.sources.default","a")
res3: String = a
当前没有设置默认的数据源,此时如果使用默认数据源去加载(或者保存)的话会报错。例如,使用默认数据源加载Json文件会提示异常,提示不是Parquet文件。
scala> spark.read.load("/resources/people.json")
18/02/17 15:33:05 ERROR executor.Executor: Exception intask 0.0 in stage 7.0 (TID 7)
…..
Caused by: java.lang.RuntimeException:hdfs://master:9000/resources/people.json is not a Parquet file. expected magicnumber at tail [80, 65, 82, 49] but found [49, 57, 125, 10]
通过Spark-Shell 的-conf选项以key=value的形式来设置默认数据源参数,重新启动Spark-Shell:
root@master:~# spark-shell–master spark://192.168.189.1:7077 –conf
"spark.sql.sources.default"="json" --executor-memory 512m --total-executor-cores 4
这里使用–conf选项将配置属性"spark.sql.sources.default"设置为"json",进入交互式界面后,重新查询该属性值,对应如下:
scala>sc.getConf.get("spark.sql.sources.default","a")
res0: String = json默认数据源已经成功设置。
2) 加载数据源。
以默认的数据源 "json"加载文件:
scala> valpeople = spark.read.load("/resources/people.json")
people:org.apache.spark.sql.DataFrame = [age: bigint, name: string]
可以继续从加载后的people中选取某些列,然后保存到默认数据源上,例如:
scala> people.select("name", "age").write.parquet("/data/namesAndAges.parquet")
这里从people中选取了"name","age"两列信息,然后保存到HDFS文件系统中/data/namesAndAges.parquet目录。通过WebInterface (http://192.168.189.1:50070/explorer.html#/data)界面查看文件信息,如图3-3所示。
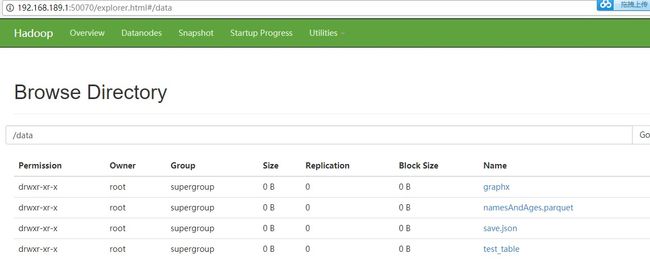
图 3 - 3 hadoop文件系统在保存后的界面
(二) 指定数据源的方式。
1) 指定数据源加载文件。
使用load方法,加载文件people.json,其对应数据源为“json”。
scala> valpeopleDF =spark.read.format("json").load("/resources/people.json")
peopleDF:org.apache.spark.sql.DataFrame = [age: bigint, name: string]
使用load方法,加载文件people.parquet,其对应数据源为“parquet”。
scala> valpeopleDF =spark.read.format("parquet").load("/resources/people.parquet")
peopleDF:org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) 指定数据源保存文件。
将加载后的people数据以Json格式保存到HDFS文件系统/data/save.json目录,保存为Json文件。
scala>peopleDF.write.json("/data/save.json")
通过Web Interface ( http://192.168.189.1:50070/explorer.html#/data/save.json)界面查看保存到HDFS系统的文件信息,如图3-4所示。
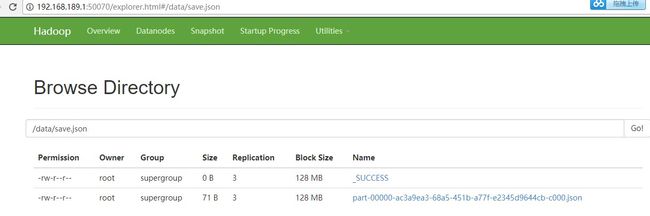
图 3 - 4 Hadoop文件系统保存以后的界面
(三) 保存模型(Save Modes)
保存操作可使用可选的保存模式(SaveMode),指定现有数据已经存在情况下的处理方式。重要的是要意识到这些保存模式不使用任何锁操作,而且也不具备原子性。因此,当尝试对同一位置进行多个写操作时,写操作是不安全的。另外,当执行一个覆盖操作时,在写新数据之前会先删除数据。
例如:使用mode("overwrite")方法进行覆盖操作:
scala>peopleDF.write.format("json").mode("overwrite").save("/data/save.json")
具体的保存模型参考表3-1的内容。
Scala/Java |
Python |
含义 |
SaveMode.ErrorIfExists(default) |
"error"(default) |
当保存一个DataFrame/DataSet到一个数据源时,如果数据已经存在,将会抛出一个异常。 |
SaveMode.Append |
"append" |
当保存一个DataFrame/DataSet到一个数据源时,如果数据/表已经存在,将会把DataFrame/DataSet的数据添加到现有的数据。 |
SaveMode.Overwrite |
"overwrite" |
Overwrite模式意味着当保存一个DataFrame/DataSet到一个数据源时,如果数据/表已经存在的话,将会用DataFrame/DataSet的数据覆盖现有的数据。 |
SaveMode.Ignore |
"ignore" |
Ignore模式意味着当保存一个DataFrame/DataSet到一个数据源时,如果数据/表已经存在的话,将不会保存DataFrame/DataSet的数据,也不会修改现有的数据。这类似与SQL中的“CREATE TABLE IF NOT EXISTS操作。 |
表 3 - 1保存模型及其含义
在实际保存操作中,需要注意各种数据源对保存模式使用的限制。Spark 2.2.1可以支持”parquet”类型数据源的'overwrite', 'append', 'ignore','error'的保存模式,使用'error'保存模式时将抛出parquet already exists的异常。
保存”parquet”类型数据源的操作:
scala>peopleDF.write.format("parquet").mode("append").save("/data/save.parquet")
scala>peopleDF.write.format("parquet").mode("overwrite").save("/data/save.parquet")
scala>peopleDF.write.format("parquet").mode("ignore").save("/data/save.parquet")
scala>peopleDF.write.format("parquet").mode("error").save("/data/save.parquet")
org.apache.spark.sql.AnalysisException:path hdfs://master:9000/data/save.parquet already exists.;
………
(四) 保存数据到持久化的表中。
1) 加载Json文件到people。
scala> valpeople = spark.read.load("/resources/people.json")
people:org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) 使用saveAsTable方法,将people保存到表people_Table中:
scala>people.write.saveAsTable("people_Table")
18/02/17 20:13:19WARN hive.HiveExternalCatalog: Couldn't find corresponding Hive SerDe for datasource provider json. Persisting data source table `default`.`people_table`into Hive metastore in Spark SQL specific format, which is NOT compatible withHive.
3) 使用spark.sql方法从表people_Table中查询数据。
scala>spark.sql("select * from people_Table where age ='30'").show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
持久化到表中和注册为临时表是不一样的,后者在应用退出后会自动销毁,而持久化到表中,是持久化到存储系统上,应用退出后不会销毁。
(五) 应用场景。
1) 可以集成各种类型的数据源,包含不同数据源之间的存储转换、格式转换等。例如:将Json文件格式转换为Parquet格式,将HDFS上的Json文件存储到Jdbc中等等。
2) 基于“One Stack to rulethem all”的思想,Spark中的各个子框架和库之间可以实现无缝的数据共享和操作,而基于Spark SQL对各种数据源的支持,同时就是为其他各个子框架,Spark Streaming、MLlib、GraphX提供了各种数据源的支持。因此,在其他子框架需要时,可以使用Spark SQL来加载或持久化数据。
2018年新春报喜!热烈祝贺王家林大咖大数据经典传奇著作《SPARK大数据商业实战三部曲》畅销书籍 清华大学出版社发行上市!
本书基于Spark 2.2.0最新版本(2017年7月11日发布),以Spark商业案例实战和Spark在生产环境下几乎所有类型的性能调优为核心,以Spark内核解密为基石,分为上篇、中篇、下篇,对企业生产环境下的Spark商业案例与性能调优抽丝剥茧地进行剖析。上篇基于Spark源码,从一个动手实战案例入手,循序渐进地全面解析了Spark 2.2新特性及Spark内核源码;中篇选取Spark开发中最具有代表的经典学习案例,深入浅出地介绍,在案例中综合应用Spark的大数据技术;下篇性能调优内容基本完全覆盖了Spark在生产环境下的所有调优技术。
本书适合所有Spark学习者和从业人员使用。对于有分布式计算框架应用经验的人员,本书也可以作为Spark高手修炼的参考书籍。同时,本书也特别适合作为高等院校的大数据教材使用。
当当网、京东、淘宝、亚马逊等网店已可购买!欢迎大家购买学习!
当当网址: http://product.dangdang.com/25230552.html