Android平台OCR工具之Tess-two使用
1.OCR简介
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;
2.Tesseract简介
Tesseract是Ray Smith于1985到1995年间在惠普布里斯托实验室开发的一个OCR引擎,曾经在1995 UNLV精确度测试中名列前茅。但1996年后基本停止了开发。2006年,Google邀请Smith加盟,重启该项目。目前项目的许可证是Apache 2.0。该项目目前支持Windows、Linux和Mac OS等主流平台。但作为一个引擎,它只提供命令行工具。
现阶段的Tesseract由Google负责维护,是最好的开源OCR Engine之一,并且支持中文。
主页地址:https://github.com/tesseract-ocr
在Tesseract的主页中,我们可以下载到Tesseract的源码及语言包,常用的语言包为
中文:chi-sim.traineddata
英文:eng.traineddata
3.Tess-two
因为Tesseract使用C++实现的,在Android中不能直接使用,需要封装JavaAPI才能在Android平台中进行调用,这里我们直接使用TessTwo项目,tess-two是TesseraToolsForAndroid的一个git分支,使用简单,切集成了leptonica,在使用之前需要先从git上下载源码进行编译。
3.1.1 项目地址
Tess-two在git上地址为:https://github.com/rmtheis/tess-two
3.1.2 编译
我编译使用的环境:
- Eclipse 4.2.1
- ADT 23.0.2
- NDK R10
- Cygwin
NDK环境的具体配置及Cygwin的安装方法可以参照这篇博客:Windows下Android NDK环境搭建
配置好NDK环境后,将从git上下载的Tess-two进行解压,放置的路径是: E:\CooGame\OCR\TessTwo源码,下边开始进行编译:
- 第一步:在Cygwin软件中使用cd命令打开Tesstwo的根目录。
- 第二步:切换到tess-two目录下的jni目录
- 第三步:输入命令进行编译
编译需要耗费挺长时间,编译完成后,会在tess-two目录下生成libs文件夹,其中包含了编译生成的.so文件,可以进行使用。
也可以直接下载我编译好的包,这里给出下载地址,我测试了一下,是没有问题的。
tess-two下载
4.tess-two使用
编译完成后,新建工程,将之前编译好的libs文件夹下的armeabi和armeabi-v7a文件夹拷贝至新建工程的libs文件夹下,将tess-two工程中src文件夹下的两个包直接拷贝至代码中或者打成jar进行使用。工程如下:
识别函数:
/**
* 识别图片中文字,需要放入异步线程中进行执行
*
* @param bitmap
* @return
* @throws IOException
*/
public String parseImageToString(String imagePath) throws IOException
{
// 检验图片地址是否正确
if (imagePath == null || imagePath.equals(""))
{
return TessErrorCode.IMAGE_PATH_IS_NULL;
}
// 获取Bitmap
BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 2;
Bitmap bitmap = BitmapFactory.decodeFile(imagePath, options);
// 图片旋转角度
int rotate = 0;
ExifInterface exif = new ExifInterface(imagePath);
// 先获取当前图像的方向,判断是否需要旋转
int imageOrientation = exif
.getAttributeInt(ExifInterface.TAG_ORIENTATION,
ExifInterface.ORIENTATION_NORMAL);
Log.i(TAG, "Current image orientation is " + imageOrientation);
switch (imageOrientation)
{
case ExifInterface.ORIENTATION_ROTATE_90:
rotate = 90;
break;
case ExifInterface.ORIENTATION_ROTATE_180:
rotate = 180;
break;
case ExifInterface.ORIENTATION_ROTATE_270:
rotate = 270;
break;
default:
break;
}
Log.i(TAG, "Current image need rotate: " + rotate);
// 获取当前图片的宽和高
int w = bitmap.getWidth();
int h = bitmap.getHeight();
// 使用Matrix对图片进行处理
Matrix mtx = new Matrix();
mtx.preRotate(rotate);
// 旋转图片
bitmap = Bitmap.createBitmap(bitmap, 0, 0, w, h, mtx, false);
bitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true);
// 开始调用Tess函数对图像进行识别
TessBaseAPI baseApi = new TessBaseAPI();
baseApi.setDebug(true);
// 使用默认语言初始化BaseApi
baseApi.init(TessConstantConfig.TESSBASE_PATH,
TessConstantConfig.DEFAULT_LANGUAGE_CHI);
baseApi.setImage(bitmap);
// 获取返回值
String recognizedText = baseApi.getUTF8Text();
baseApi.end();
return recognizedText;
}使用之前,需要先下载数据包到/mnt/sdcard/tesseract/目录下,下载地址在上边文章中已经有提到。可以根据需要识别的语言进行下载
数据包下载地址
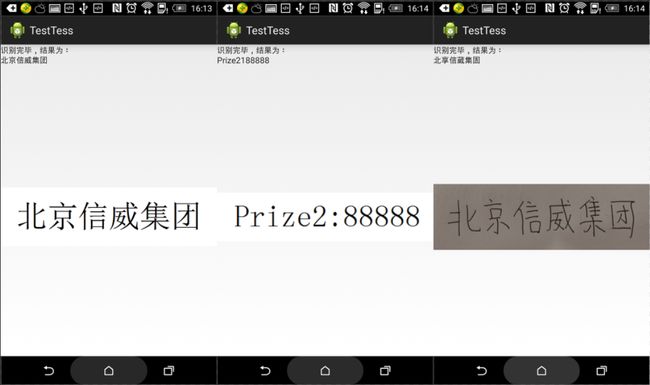
经过测试,发现tess-two的识别率不是很高,对一般电脑输入文字生成的图片,识别度较高,但对于手写问题,识别率较低,可能需要进一步进行训练。下边是我识别的结果截图:
5.总结
总结tess-two的使用方法,大致可分为以下几步:
- 下载并解压tess-two
- 编译,获得.so文件,或者直接下载我编译好的tess-two文件,可以不用下载tess-two源码
- 新建工程测试,训练
6. 代码
我是代码