【sklearn】随机森林 - 预测用户是否离网
目的
本文使用Python的sklearn类库,基于对随机森林算法的理论学习,利用工程中的数据,以此来对随机森林的理论知识进行一次实践总结。
利用过往1年的数据训练专家系统,目的是判断用户3个月内是否会离网。
训练集主要来自工程中的数据集,一共100万条样本数据,16个维度。
实现
导入依赖类库:
#!-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV # 网格搜索调参,即穷尽参数所有可能性# 从本地读取训练数据
data = pd.read_csv('./decision.csv', encoding='utf-8', sep=' ') # 以空格为分隔符,读取decision文件的内容# 数据探索
print(type(data)) # data为DataFrame类型
print(data.shape)
print(data.head(5)) # 前5行
print(data.info())
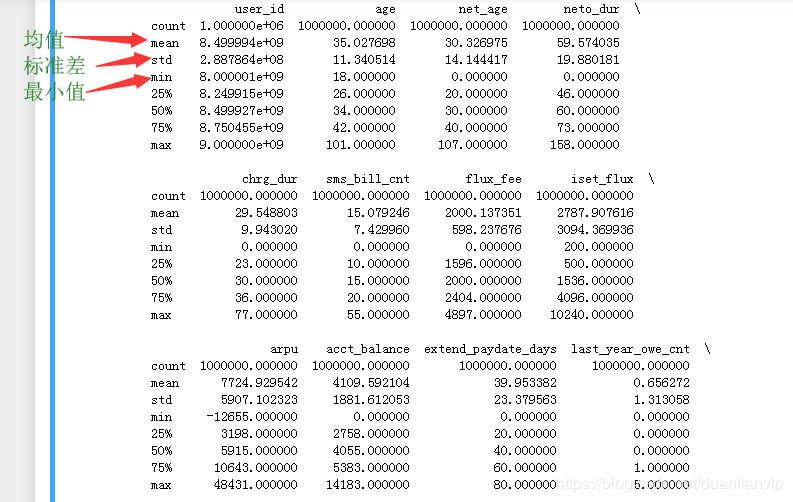
print(data.describe())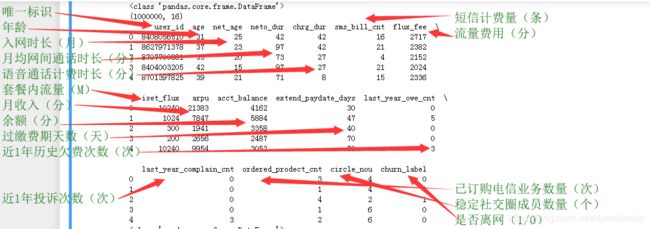
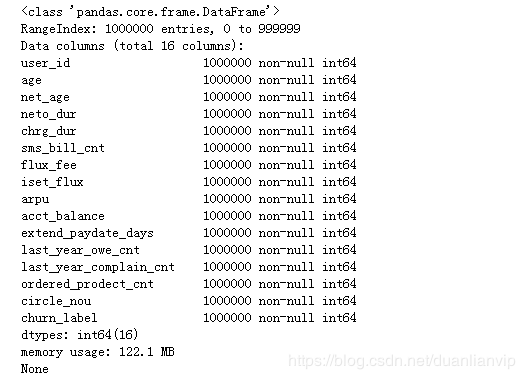
可以通过如下数据来判断数据是否存在问题,比如年龄的最大、最小值等。

# 数据构造
col_dicts = {}
cols = data.columns.values.tolist() # 读取所有列名
df = data.loc[:, cols[1:]] # 获取除去第一列(user_id)的其它所有数据
print(df.shape)
X = df.loc[:, cols[1: -1]] # 获取除去第一列(user_id)和最后一列(churn_label)的所有数据
# X = df.loc[:, cols[1: 3]]
# X.append(df.loc[:, cols[5]])
# X.append(df.loc[:, cols[8:14]])
print(X.info())结果:
(1000000, 15) # 100W行,15列
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 14 columns):
age 1000000 non-null int64 # 可以看出,数据集是完整的数据集,无缺失值
net_age 1000000 non-null int64
neto_dur 1000000 non-null int64
chrg_dur 1000000 non-null int64
sms_bill_cnt 1000000 non-null int64
flux_fee 1000000 non-null int64
iset_flux 1000000 non-null int64
arpu 1000000 non-null int64
acct_balance 1000000 non-null int64
extend_paydate_days 1000000 non-null int64
last_year_owe_cnt 1000000 non-null int64
last_year_complain_cnt 1000000 non-null int64
ordered_prodect_cnt 1000000 non-null int64
circle_nou 1000000 non-null int64
dtypes: int64(14)
memory usage: 106.8 MB
None
# 数据拆分及类别信息查看
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) # 20%测试集,80%训练集。固定随机种子(random_state),可以让每次划分训练集和验证集的时候都是完全一样的。
print(y_train.value_counts() / len(y_train))
print('---------')
print(y_test.value_counts() / len(y_test))结果:
1 0.500988
0 0.499013
Name: churn_label, dtype: float64
---------
0 0.50002
1 0.49998
Name: churn_label, dtype: float64以上结果显示正负样本比例相差不大,不存在数据倾斜。如果出现数据倾斜,可以采取如下方式进行调整:
- 负采样;
- 构建负样本
为了节省运算时间,子模型数(n_estimators)参数设置的比较小,实际中可以设置大一点。
# 构建随机森林模型
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
credit_model = RandomForestClassifier(n_estimators=10, n_jobs=4) # 10个子分类器,4个CPU线程并行
# print(credit_model.fit(X_train, y_train))
# 使用网格搜索训练参数
# n_estimators_range = 100 # 子模型数
max_depth_range = np.arange(5, 7, 1) # 最大树深度
criterion_range = ['gini', 'entropy'] # 分裂条件。gini:CART树;entropy:C4.5
# 随机选择特征集合的子集合,并用来分割节点。子集合的个数越少,方差就会减少的越快,但同时偏差就会增加的越快
'''
选择最适属性时划分的特征不能超过此值。
当为整数时,即最大特征数;当为小数时,训练集特征数*小数;
if “auto”, then max_features=sqrt(n_features).
If “sqrt”, thenmax_features=sqrt(n_features).
If “log2”, thenmax_features=log2(n_features).
If None, then max_features=n_features.
'''
max_features_range = ['auto', 'sqrt', 'log2']
param_grid = {'max_depth': max_depth_range, 'max_features': max_features_range, 'criterion': criterion_range}
# GridSearch作用在训练集上
grid = GridSearchCV(credit_model, param_grid=param_grid, scoring='accuracy', n_jobs=4, cv=5)
grid.fit(X_train, y_train)结果:
GridSearchCV(cv=5, error_score='raise-deprecating',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=10, n_jobs=4,
oob_score=False,
random_state=None, verbose=0,
warm_start=False),
iid='warn', n_jobs=4,
param_grid={'criterion': ['gini', 'entropy'],
'max_depth': array([5, 6]),
'max_features': ['auto', 'sqrt', 'log2']},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring='accuracy', verbose=0)# 得到最优参数
print(grid.best_score_)
print(grid.best_params_)
print(grid.best_estimator_)
# 训练参数调优后的模型
credit_model = RandomForestClassifier(n_estimators=10, n_jobs=4, max_depth=grid.best_params_['max_depth'], max_features=grid.best_params_['max_features'], criterion=grid.best_params_['criterion'])
# fit on the trainingt data
credit_model.fit(X_train, y_train)
# 模型预测及结果分析
credit_pred = credit_model.predict(X_test)
from sklearn import metrics
print(metrics.classification_report(y_test, credit_pred)) # y_test:真实值;credit_pred:预测值
print(metrics.confusion_matrix(y_test, credit_pred))
print(metrics.accuracy_score(y_test, credit_pred)) # 预测的准确率结果:
0.5556025
{'criterion': 'gini', 'max_depth': 5, 'max_features': 'sqrt'}
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=5, max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=4,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
precision recall f1-score support
0 0.56 0.56 0.56 100004
1 0.56 0.56 0.56 99996
accuracy 0.56 200000
macro avg 0.56 0.56 0.56 200000
weighted avg 0.56 0.56 0.56 200000
[[55626 44378]
[44432 55564]]
0.55595
总结
本文简单的构造了一个随机森林,并使用网格搜索的方式对其进行超参调优,还可以使用如下方式进行调优:
- 把连续性维度换成离散型;
- 特征层面调优;
- 超参数层面调优