YOLOv2 论文笔记
论文地址:YOLO9000: Better, Faster, Stronger
项目主页:YOLO: Real-Time Object Detection
概述
时隔一年,YOLO(You Only Look Once: Unified, Real-Time Object Detection)从v1版本进化到了v2版本,作者在darknet主页先行一步放出源代码,论文在我们等候之下终于在12月25日发布出来,本文对论文重要部分进行了翻译理解工作,不一定完全对,如有疑问,欢迎讨论。博主如果有新的理解,也会更新文章,或者新写一篇。
新的YOLO版本论文全名叫“YOLO9000: Better, Faster, Stronger”,主要有两个大方面的改进:
第一,作者使用了一系列的方法对原来的YOLO多目标检测框架进行了改进,在保持原有速度的优势之下,精度上得以提升。VOC 2007数据集测试,67FPS下mAP达到76.8%,40FPS下mAP达到78.6%,基本上可以与Faster R-CNN和SSD一战。这一部分是本文主要关心的地方。
第二,作者提出了一种目标分类与检测的联合训练方法,通过这种方法,YOLO9000可以同时在COCO和ImageNet数据集中进行训练,训练后的模型可以实现多达9000种物体的实时检测。这一方面本文暂时不涉及,待后面有时间再补充。
回顾YOLOv1
YOLOv2始终是在v1版本上作出的改进,我们先简单回顾YOLOv1的检测步骤: 
(1) 给个一个输入图像,首先将图像划分成7 * 7的网格。
(2) 对于每个网格,我们都预测2个边框。(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7 * 7 * 2 = 98个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
YOLOv1使用了end-to-end的回归方法,没有region proposal步骤,直接回归便完成了位置和类别的判定。种种原因使得YOLOv1在目标定位上不那么精准,直接导致YOLO的检测精度并不是很高。
YOLO检测原理参考推荐博客:论文阅读:You Only Look Once: Unified, Real-Time Object Detection
YOLOv2精度的改进(Better)
先来一个总览图,看看它到底用了多少技巧,以及这些技巧起了多少作用: 
CNN在训练过程中网络每层输入的分布一直在改变, 会使训练过程难度加大,但可以通过normalize每层的输入解决这个问题。新的YOLO网络在每一个卷积层后添加batch normalization,通过这一方法,mAP获得了2%的提升。batch normalization 也有助于规范化模型,可以在舍弃dropout优化后依然不会过拟合。
High Resolution Classifier
目前的目标检测方法中,基本上都会使用ImageNet预训练过的模型(classifier)来提取特征,如果用的是AlexNet网络,那么输入图片会被resize到不足256 * 256,导致分辨率不够高,给检测带来困难。为此,新的YOLO网络把分辨率直接提升到了448 * 448,这也意味之原有的网络模型必须进行某种调整以适应新的分辨率输入。
对于YOLOv2,作者首先对分类网络(自定义的darknet)进行了fine tune,分辨率改成448 * 448,在ImageNet数据集上训练10轮(10 epochs),训练后的网络就可以适应高分辨率的输入了。然后,作者对检测网络部分(也就是后半部分)也进行fine tune。这样通过提升输入的分辨率,mAP获得了4%的提升。
Convolutional With Anchor Boxes
之前的YOLO利用全连接层的数据完成边框的预测,导致丢失较多的空间信息,定位不准。作者在这一版本中借鉴了Faster R-CNN中的anchor思想,回顾一下,anchor是RNP网络中的一个关键步骤,说的是在卷积特征图上进行滑窗操作,每一个中心可以预测9种不同大小的建议框。看到YOLOv2的这一借鉴,我只能说SSD的作者是有先见之明的。 
为了引入anchor boxes来预测bounding boxes,作者在网络中果断去掉了全连接层。剩下的具体怎么操作呢?首先,作者去掉了后面的一个池化层以确保输出的卷积特征图有更高的分辨率。然后,通过缩减网络,让图片输入分辨率为416 * 416,这一步的目的是为了让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。作者观察到,大物体通常占据了图像的中间位置, 就可以只用中心的一个cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。最后,YOLOv2使用了卷积层降采样(factor 为32),使得输入卷积网络的416 * 416图片最终得到13 * 13的卷积特征图(416/32=13)。
加入了anchor boxes后,可以预料到的结果是召回率上升,准确率下降。我们来计算一下,假设每个cell预测9个建议框,那么总共会预测13 * 13 * 9 = 1521个boxes,而之前的网络仅仅预测7 * 7 * 2 = 98个boxes。具体数据为:没有anchor boxes,模型recall为81%,mAP为69.5%;加入anchor boxes,模型recall为88%,mAP为69.2%。这样看来,准确率只有小幅度的下降,而召回率则提升了7%,说明可以通过进一步的工作来加强准确率,的确有改进空间。
Dimension Clusters(维度聚类)
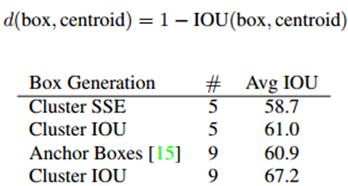
作者在使用anchor的时候遇到了两个问题,第一个是anchor boxes的宽高维度往往是精选的先验框(hand-picked priors),虽说在训练过程中网络也会学习调整boxes的宽高维度,最终得到准确的bounding boxes。但是,如果一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就更容易学到准确的预测位置。
和以前的精选boxes维度不同,作者使用了K-means聚类方法类训练bounding boxes,可以自动找到更好的boxes宽高维度。传统的K-means聚类方法使用的是欧氏距离函数,也就意味着较大的boxes会比较小的boxes产生更多的error,聚类结果可能会偏离。为此,作者采用的评判标准是IOU得分(也就是boxes之间的交集除以并集),这样的话,error就和box的尺度无关了,最终的距离函数为: 
作者通过改进的K-means对训练集中的boxes进行了聚类,判别标准是平均IOU得分,聚类结果如下图: 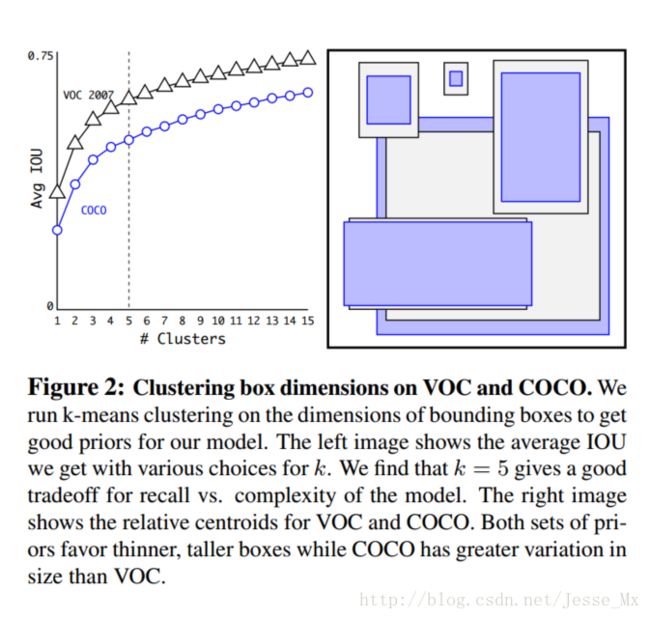
可以看到,平衡复杂度和IOU之后,最终得到k值为5,意味着作者选择了5种大小的box维度来进行定位预测,这与手动精选的box维度不同。结果中扁长的框较少,而瘦高的框更多(这符合行人的特征),这种结论如不通过聚类实验恐怕是发现不了的。
当然,作者也做了实验来对比两种策略的优劣,如下图,使用聚类方法,仅仅5种boxes的召回率就和Faster R-CNN的9种相当。说明K-means方法的引入使得生成的boxes更具有代表性,为后面的检测任务提供了便利。 
Direct location prediction(直接位置预测)
那么,作者在使用anchor boxes时发现的第二个问题就是:模型不稳定,尤其是在早期迭代的时候。大部分的不稳定现象出现在预测box的(x,y)坐标上了。在区域建议网络中,预测(x,y)以及tx,ty使用的是如下公式: 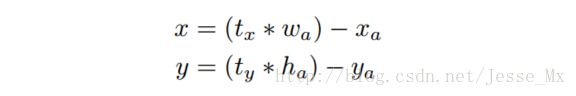
这个公式的理解为:当预测tx=1,就会把box向右边移动一定距离(具体为anchor box的宽度),预测tx=-1,就会把box向左边移动相同的距离。
这个公式没有任何限制,使得无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点结束。模型随机初始化后,需要花很长一段时间才能稳定预测敏感的物体位置。
在此,作者就没有采用预测直接的offset的方法,而使用了预测相对于grid cell的坐标位置的办法,作者又把ground truth限制在了0到1之间,利用logistic回归函数来进行这一限制。 
现在,神经网络在特征图(13 *13 )的每个cell上预测5个bounding boxes(聚类得出的值),同时每一个bounding box预测5个坐标值,分别为tx,ty,tw,th,to。如果这个cell距离图像左上角的边距为(cx,cy)以及该cell对应的box维度(bounding box prior)的长和宽分别为(pw,ph),那么预测值可以表示为: 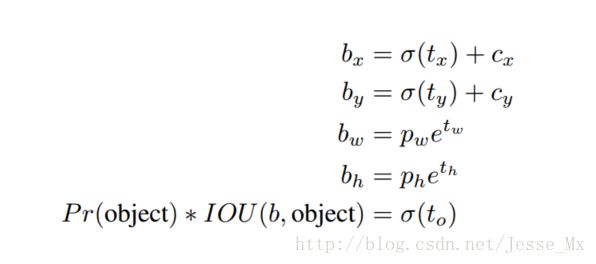
定位预测值被归一化后,参数就更容易得到学习,模型就更稳定。作者使用Dimension Clusters和Direct location prediction这两项anchor boxes改进方法,mAP获得了5%的提升。(这一部分理解不够,有机会详细说下) 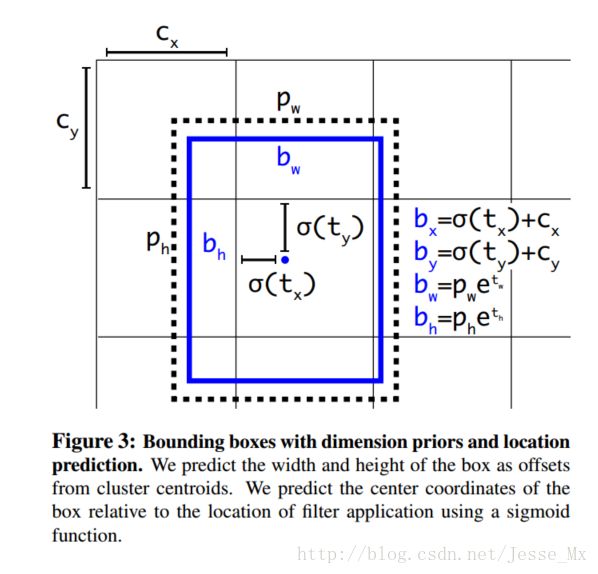
Fine-Grained Features(细粒度特征)
上述网络上的修改使YOLO最终在13 * 13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,但是用上细粒度特征的话,这可能对小尺度的物体检测有帮助。Faser R-CNN和SSD都在不同层次的特征图上产生区域建议(SSD直接就可看得出来这一点),获得了多尺度的适应性。这里使用了一种不同的方法,简单添加了一个转移层( passthrough layer),这一层要把浅层特征图(分辨率为26 * 26,是底层分辨率4倍)连接到深层特征图。 
这个转移层也就是把高低两种分辨率的特征图做了一次连结,连接方式是叠加特征到不同的通道而不是空间位置,类似于Resnet中的identity mappings(对Resnet这一机制几乎不懂,等看懂了再行补充)。这个方法把26 * 26 * 512的特征图连接到了13 * 13 * 2048的特征图,这个特征图与原来的特征相连接。YOLO的检测器使用的就是经过扩张的特征图,它可以拥有更好的细粒度特征,使得模型的性能获得了1%的提升。(这段理解的也不是很好,要看到网络结构图才能清楚)
Multi-Scale Training
原来的YOLO网络使用固定的448 * 448的图片作为输入,现在加入anchor boxes后,输入变成了416 * 416。目前的网络只用到了卷积层和池化层,那么就可以进行动态调整(意思是可检测任意大小图片)。作者希望YOLOv2具有不同尺寸图片的鲁棒性,因此在训练的时候也考虑了这一点。
不同于固定输入网络的图片尺寸的方法,作者在几次迭代后就会微调网络。没经过10次训练(10 epoch),就会随机选择新的图片尺寸。YOLO网络使用的降采样参数为32,那么就使用32的倍数进行尺度池化{320,352,…,608}。最终最小的尺寸为320 * 320,最大的尺寸为608 * 608。接着按照输入尺寸调整网络进行训练。
这种机制使得网络可以更好地预测不同尺寸的图片,意味着同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLOv2运行更快,在速度和精度上达到了平衡。
在小尺寸图片检测中,YOLOv2成绩很好,输入为228 * 228的时候,帧率达到90FPS,mAP几乎和Faster R-CNN的水准相同。使得其在低性能GPU、高帧率视频、多路视频场景中更加适用。
在大尺寸图片检测中,YOLOv2达到了先进水平,VOC2007 上mAP为78.6%,仍然高于平均水准,下图是YOLOv2和其他网络的成绩对比: 

Further Experiments
作者在VOC2012上对YOLOv2进行训练,下图是和其他方法的对比。YOLOv2精度达到了73.4%,并且速度更快。同时YOLOV2也在COCO上做了测试(IOU=0.5),也和Faster R-CNN、SSD作了成绩对比。总的来说,比上不足,比下有余。 
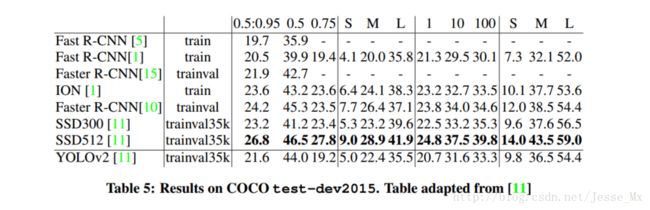
YOLOv2速度的改进(Faster)
YOLO一向是速度和精度并重,作者为了改善检测速度,也作了一些相关工作。
大多数检测网络有赖于VGG-16作为特征提取部分,VGG-16的确是一个强大而准确的分类网络,但是复杂度有些冗余。224 * 224的图片进行一次前向传播,其卷积层就需要多达306.9亿次浮点数运算。
YOLOv2使用的是基于Googlenet的定制网络,比VGG-16更快,一次前向传播仅需85.2亿次运算。可是它的精度要略低于VGG-16,单张224 * 224取前五个预测概率的对比成绩为88%和90%(低一点点也是可以接受的)。
Darknet-19
YOLOv2使用了一个新的分类网络作为特征提取部分,参考了前人的先进经验,比如类似于VGG,作者使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化(global average pooling),把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。也用了batch normalization(前面介绍过)稳定模型训练。
最终得出的基础模型就是Darknet-19,如下图,其包含19个卷积层、5个最大值池化层(maxpooling layers ),下图展示网络具体结构。Darknet-19运算次数为55.8亿次,imagenet图片分类top-1准确率72.9%,top-5准确率91.2%。 
Training for classification
作者使用Darknet-19在标准1000类的ImageNet上训练了160次,用的随机梯度下降法,starting learning rate 为0.1,polynomial rate decay为4,weight decay为0.0005 ,momentum 为0.9。训练的时候仍然使用了很多常见的数据扩充方法(data augmentation),包括random crops, rotations, and hue, saturation, and exposure shifts。 (这些训练参数是基于darknet框架,和caffe不尽相同)
初始的224 * 224训练后,作者把分辨率上调到了448 * 448,然后又训练了10次,学习率调整到了0.001。高分辨率下训练的分类网络在top-1准确率76.5%,top-5准确率93.3%。
Training for detection
分类网络训练完后,就该训练检测网络了,作者去掉了原网络最后一个卷积层,转而增加了三个3 * 3 * 1024的卷积层(可参考darknet中cfg文件),并且在每一个上述卷积层后面跟一个1 * 1的卷积层,输出维度是检测所需的数量。对于VOC数据集,预测5种boxes大小,每个box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。同时也添加了转移层(passthrough layer ),从最后那个3 * 3 * 512的卷积层连到倒数第二层,使模型有了细粒度特征。
作者的检测模型以0.001的初始学习率训练了160次,在60次和90次的时候,学习率减为原来的十分之一。其他的方面,weight decay为0.0005,momentum为0.9,依然使用了类似于Faster-RCNN和SSD的数据扩充(data augmentation)策略。
这一部分,作者使用联合训练方法,结合词向量树(wordtree)等方法,使YOLOv2的检测种类扩充到了上千种,具体内容待续。
总结和展望
作者大概说的是,之前的技术改进对检测任务很有帮助,在以后的工作中,可能会涉足弱监督方法用于图像分割。监督学习对于标记数据的要求很高,未来要考虑弱标记的技术,这将会极大扩充数据集,提升训练量。
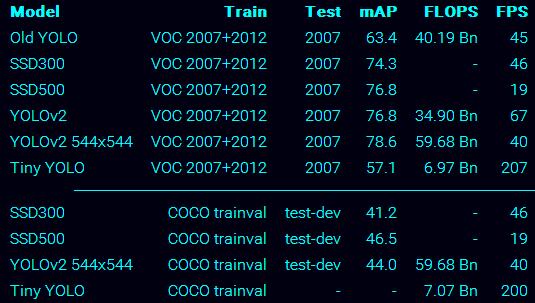
从下图可以看出,YOLOv2不管是速度还是精度都超过了SSD300,和YOLOv1相比,确实有很大的性能的提升。这名字也起的darknet,就跟黑魔法一样,是那么的奏效,不得不佩服老外的起名啊。
论文思想篇:
该论文为YOLO9000:Better, Faster, Stronger
非常值得一看的论文。
Better:
batch Normalization:在卷基层后面增加了batch Normalization,去掉了dropout层,mAP提升2%。
High ResolutionClassifier:x训练网络的时候将网络从224*224变为448*448,当然后续为了保证特征图中只有基数个定位位置,从而保证只有一个中心细胞,网络最终设置为416*416。最终实现了4%的mAP提升。
Convoutional with AnchorBoxes:作者吸收了faster RCNN中RPN的思想,去掉了yolov1中的全连接层,加入了anchor boxes,这样做的目的就是得到更高的召回率,当然召回率高了,mAP就会相应的下降,这也是人之常情。最终,yolov1只有98个边界框,yolov2达到了1000多个。mAP由69.5下降到69.2,下降了0.3,召回率由81%提升到88%,提升7%。
Dimension Clusters:这里作者提出了kmeans聚类,这里的K作者取值为5,这样会在模型复杂度和召回率之间达到一个好的折中。并且使用聚类的中心代替Anchor,最后使用欧式距离进行边界框优先权的衡量,欧式距离公式如下所示,距离越小说明优先权越高。在k为5 的条件下,Avg IOU从60.9提升到了61.0。在k为9的的条件下Avg IOU提升为67.2
Direction location prediction:
引入了anchor boxes就会产生模型不稳定的问题,该问题产生于边界框位置的预测。简单的解释,如果训练的图片中的物体一张是在左面,下一张又在右面,就会产生这样的波动,显然的这个过程是不受控制的,毕竟图片中的物体位置他在哪里就在哪里。这里作者,变换了个思路,把最终预测的相对于anchor的边界框的相关系数变为预测相对于grid cell(yolo v1的机制)的相关系数,使得输出的系数在0-1直接波动,如此就解决了波动的问题。最终,使用维度聚类和直接预测边界框中心比使用anchor boxes提升了5%的mAP。(这里我可能解释的也不是很清晰,还是有点不太好表达,希望还是多看看论文,论文才是第一手的资料)。 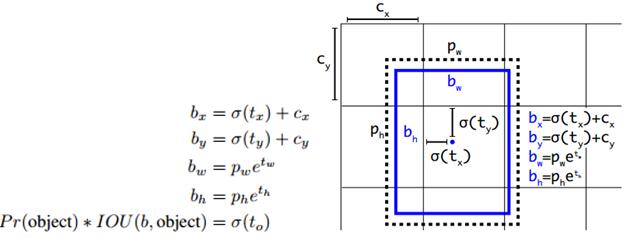
Fine-Grained Features:有别于faster rcnn和SSD采用多尺度的特征图进行预测,yolov2提出了一个全新的思路,作者引入了passthrough layer,这个层的作用就是将上一层特征图的相邻像素都切除一部分组成了另外一个通道。例如,将26*26*512的特征图变为13*13*2048的特征图(这里具体的实现过程需要看作者的源码,但是,为了解释这个变化过程,可以做这样的解释,就是将一个26*26的图的像素放到4个13*13的图中,水平每2个像素取1个,垂直也是每2个像素取一个,一共就可以得到2*2=4个,512*4=2048),使得特征图的数目提高了4倍,同时,相比于26*26的特征图,13*13的特征图更有利用小目标物的检测,
该改进使得mAP提升1%。
Multi-Scale Training:这里作者提出的训练方法也很独特,在训练过程中就每隔10batches,随机的选择另外一种尺度进行训练,这里,作者给出的训练尺度为{320,352,……,608},这个训练的方法,使得最终得到的模型可以对不同分辨率的图像都能达到好的检测效果。
Faster:
这里,vgg16虽然精度足够好,但是模型比较大,网络传输起来比较费时间,因此,作者提出了一个自己的模型,Darknet-19。而darknetv2也正式已Darknet-19作为pretrained model训练起来的。
Stronger:
这里作者的想法也很新颖,解决了2个不同数据集相互排斥(mutualy exclusive)的问题。作者提出了WordTree,使用该树形结构成功的解决了不同数据集中的排斥问题。使用该树形结构进行分层的预测分类,在某个阈值处结束或者最终达到叶子节点处结束。下面这副图将有助于WordTree这个概念的理解。 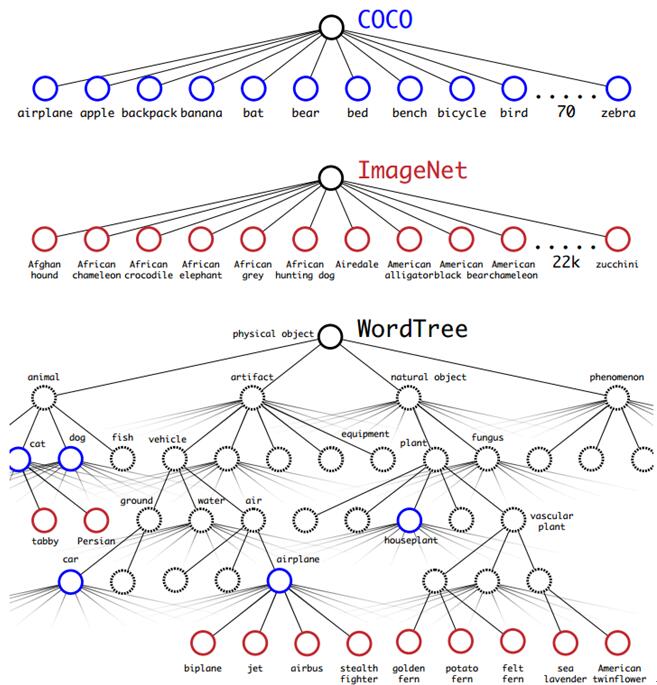
linux篇:
安装步骤:
- git clone https://github.com/pjreddie/darknet
- cd darknet
- vim Makefile
- 修改,GPU=1 OPENCV=1
- wget http://pjreddie.com/media/files/yolo.weights
- make
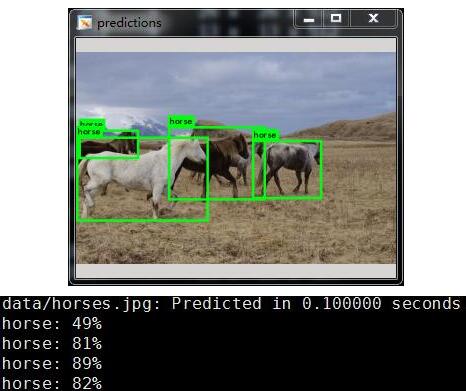
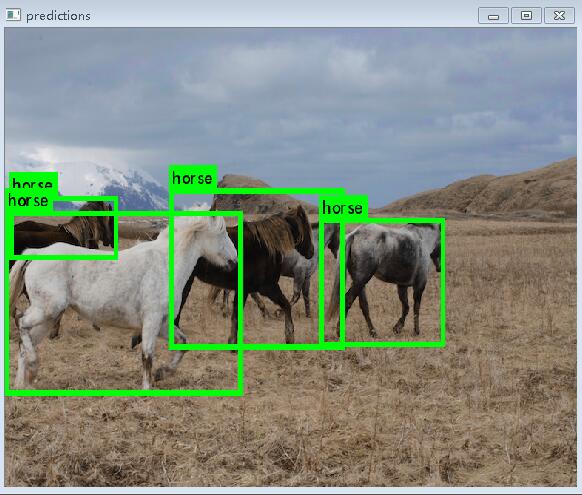
- ./darknet detect cfg/yolo.cfg yolo.weights data/horses.jpg
运行效果:
测试环境centos+titanx
程序下载链接:
https://github.com/pjreddie/darknet
http://pjreddie.com/darknet/yolo/
windows篇:
这里就不在赘述修改细节,有疑问欢迎留言。
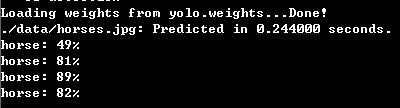
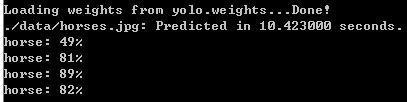
最后贴一个cpu和gpu下运行的时间和效果图
进入到darknetv2根目录,运行下面的命令,
darknet.exe detect ./cfg/yolo.cfg yolo.weights ./data/horses.jpg
结果如下,运行环境,win7+至强E3cpu+750ti大将,左面为GPU版本,右面为CPU版本,
和darknetv1相比,很大的区别就是v1原来的模型750M,2G显存的显卡根本跑不起来,现在v2的模型变小,就可以跑起来了,从速度上来看,还是有点慢,和SSD的速度相比,直接差了1半。