机器学习与深度学习系列连载: 第三部分 强化学习(十七) 深度强化学习- 稀疏奖励该怎么办? Sparse Reward
稀疏奖励该怎么办? Sparse Reward
强化学习,一切都基于奖励。
往往,在现实世界中,奖励并不是实时的,有可能是在最后才出现。人们是如何应对的,这种应对方法对机器学习有何启示?
1. 奖励重塑 Reward Shaping
我们考虑这样的一个问题,对于孩子来说,学习还是玩耍,这是一个问题。 应为玩耍缺失比学习有意思。现在学习的奖励为-1,玩耍的奖励为+1。 但是就长期奖励来说,学习能够得到好成绩,比玩耍的长期奖励要高。
但是孩子对长期奖励可能会视而不见,我们就需要重塑实时奖励,让孩子投入到学习中去。
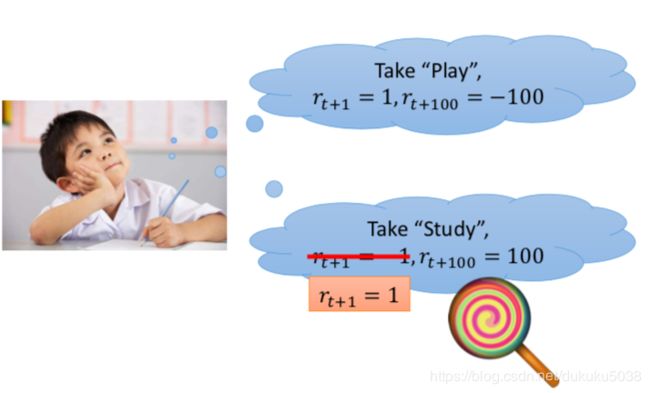
“虽然学习枯燥,但是有糖吃”就是一种奖励重塑,reward shaping。
我们再看一个Facebook的AI实验室拿到VizDoom全球竞赛(第一人称射击游戏)第一名的过程:
我们把存活时长、掉血、捡到药箱等等都会得到一个精心射击的reward,并不是只有拿到分数或者死亡才会有奖励。

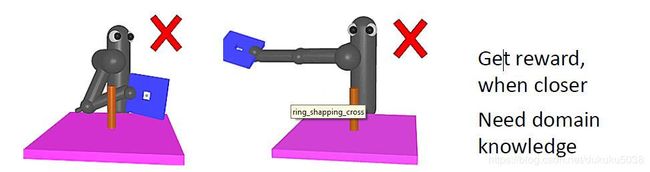
然而仅仅把奖励细化,不能彻底解决强化学习的学习困难的问题,例如机器手臂想要把板子套入立柱,他的奖励就是靠近立柱,在立柱上方,对齐,下落等等。机器人如果完全处于探索模式,学习的过程是相当漫长的。
图片来自:https://openreview.net/pdf?id=Hk3mPK5gg
2. 好奇心 Curiosity
“大道至简”,“大道互通”,人类也是没有很多的瞬时奖励的,但是咱们是如何取得一定成绩的呢?
好奇心是做好一件事的关键,甚至有书说,好奇心就代表幸福感!
我们回归到深度强化学习,在稀疏的奖励面前,如何为机器添加好奇心?
我们首先引入ICM的概念:固有好奇心模块
ICM = intrinsic curiosity module
图片来自论文 https://arxiv.org/abs/1705.05363 :
我们通过ICM模块产生好奇心,将好奇心添加到整个reward体系中(其他的模式都不变)

2.1 ICM模块
ICM模块的主要目的是将我们预测的下一个状态 S ^ t + 1 \hat{S}_{t+1} S^t+1 和真实的 S t + 1 S_{t+1} St+1,进行比较。
如果是预测的结果和真实的结果差距比较大,反而是我们鼓励的,但是总是预测无关紧要的场景,比如树叶飘动(好奇大自然的一举一动),肯定也是对结果产生不利的影响。
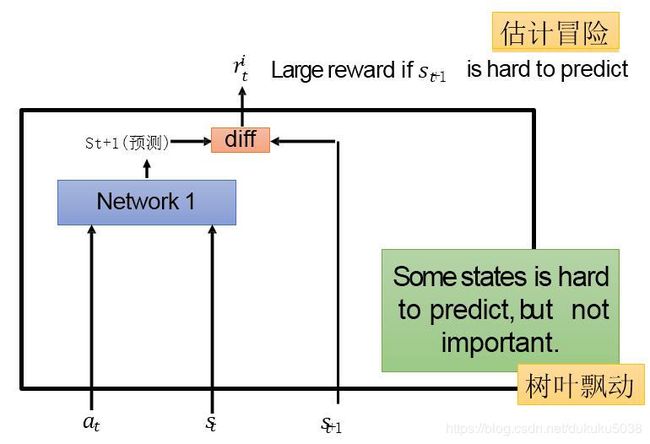
然后我们加入特征抽取器,将不必要的特征进行过滤。

3. 机器教学计划 Curriculum Learning
假想这样一个场景:教一个小朋友学数学,如果一上来就是微积分,孩子是无论如何都学不会的(即使是天才)。
我们需要先从数字开始,然后到自然数、有理数、无理数…最后过度到微积分。
和人一样,给让机器进行学习,我们作为老师,需要给它指定一个详细的教学计划。
facebook的VizDoom游戏中(我们刚才提过),就是首先让AI在低速中进行训练,然后过渡到高速。

在机器手臂套杆子过程中(我们刚才也提到),首先是让AI在套上杆子后只需要下压,就可以完成,然后过渡到如何套上杆子,然后过渡到如何靠近杆子。
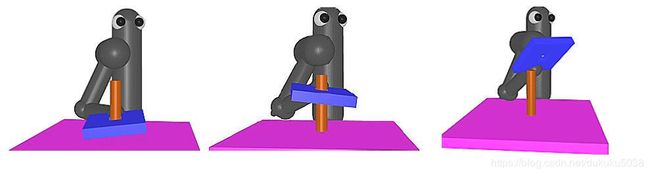
- 反向机器课程规划 Reverse Curriculum Generation
我们从最终的目标出发,先找到接近目标的位置,然后再从这些位置出发,再找到接近这些位置的点,依次寻找。

3. 结构化强化学习 Hierarchical Reinforcement Learning
我们还是举一个例子(可能不太恰当):
大学校长提出学校进步目标就是要发高水平论文。然后把这项任务分配给指导教授,教授拿到任务后,用学术能力构思了论文研究的内容和实验过程,然后让研究生去做实验拿到结果。
通过任务的层层指派,目的是让大学校长的愿景实现,指导教授的论文发表,研究生顺利毕业。

所有的环节如果实现了都是有奖励的。 这就是结构化强化学习 Hierarchical Reinforcement Learning
- 如果低一级别的agent不能实现目标,上一个级别的agent就会得到惩罚
- 如果一个agent得到了错误的结果,那说明初始的高级目标有可能也是错的
参考论文:https://arxiv.org/abs/1805.08180
读者有没有感觉到,这就是一种行政管理的手段的强化学习实现。
再举一个例子,我们在迷宫中,需要找到黄色的点。
我们有蓝色的底层agent 和红色的高层agent。
红色的agent指导蓝色的agent一步一步绕开障碍物。

论文参考:https://arxiv.org/abs/1805.08180
本专栏图片、公式很多来自David Silver主讲的UCL-Course强化学习视频公开课和台湾大学李宏毅老师的深度强化学习课程,在这里,感谢这些经典课程,向他们致敬!