麦克引擎:下载BD图片其实可以很直接,反思,有时候我们太依赖引擎了
昨天为了从百度上下载图片,折腾了一天半的scrapy,去了解各种它的框架结构,先后顺序等。到了晚上终于跑起来了,可是总觉得不太爽。
麦克引擎 SCRAPY 下载百度图片踩坑记
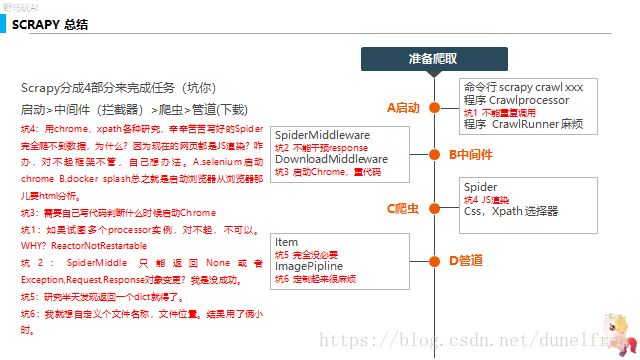
到了下午,我终于让我这个老爷车跑起来了,而且跑的磕磕巴巴的。作为一个两三年不摸技术的产品,我激动的(被坑)差点哭出来。然后我冷静了下来,我需要什么?
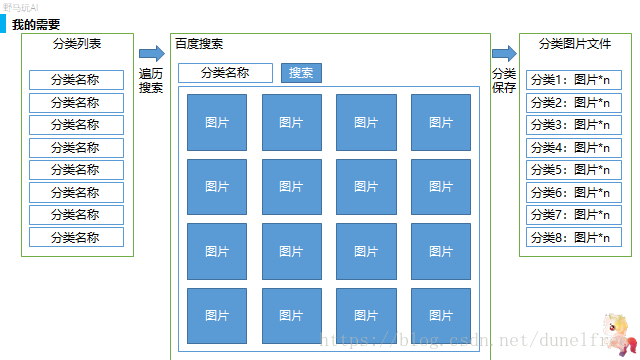
我整理了一个自己很满意的狗狗分类列表(FCI,AKC标准等,从维基百科上找到的,花了我将近一天的时间,回头我单独给大家聊聊这个分类的事儿。)
我希望通过百度搜索,对这些分类的图片进行搜索,并分类整理。实际上分类下载图片只是第一步,第二步还要对图片进行过滤,分清楚哪些是狗的图片,哪些不是。如果一张图片中有多个狗应该分别拆分等等。这部分回头我也单独说说。

灵光一现,我对自己的想法进行了重新梳理,我需要的东西很简单。用scrapy框架太复杂了,而且框架中的细节让我偏离了我的重点,所以我变得非常的气愤,暴躁,想要打人。重新分析了我的需求,我发现其实我不需要scrapy这个框架,我只需要几个功能模块,然后把它整合在一起完成我的目标就行了。
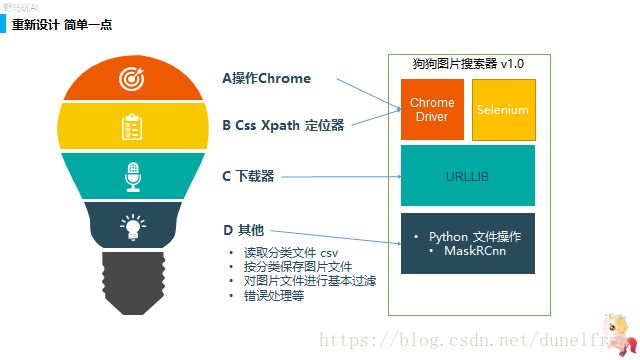
很快,大约30分钟,我把这些部分等整合起来。并且这一次我用的是Jupyter ,没有直接修改文件。
说到这儿还要说一下scrapy由于是框架所以在jupyter中跑起来太麻烦,只能编写py文件。查看一次效果太麻烦,还是jupyter好,分块分段调试,整个效率高了很多。难怪大家用了jupyter就回不去了。
我通过selenium拉起了chrome,通过selenium自带的选择器循环了列表,通过urllib(有坑,要加headers:user-agent,referer),愉快的跑起来。
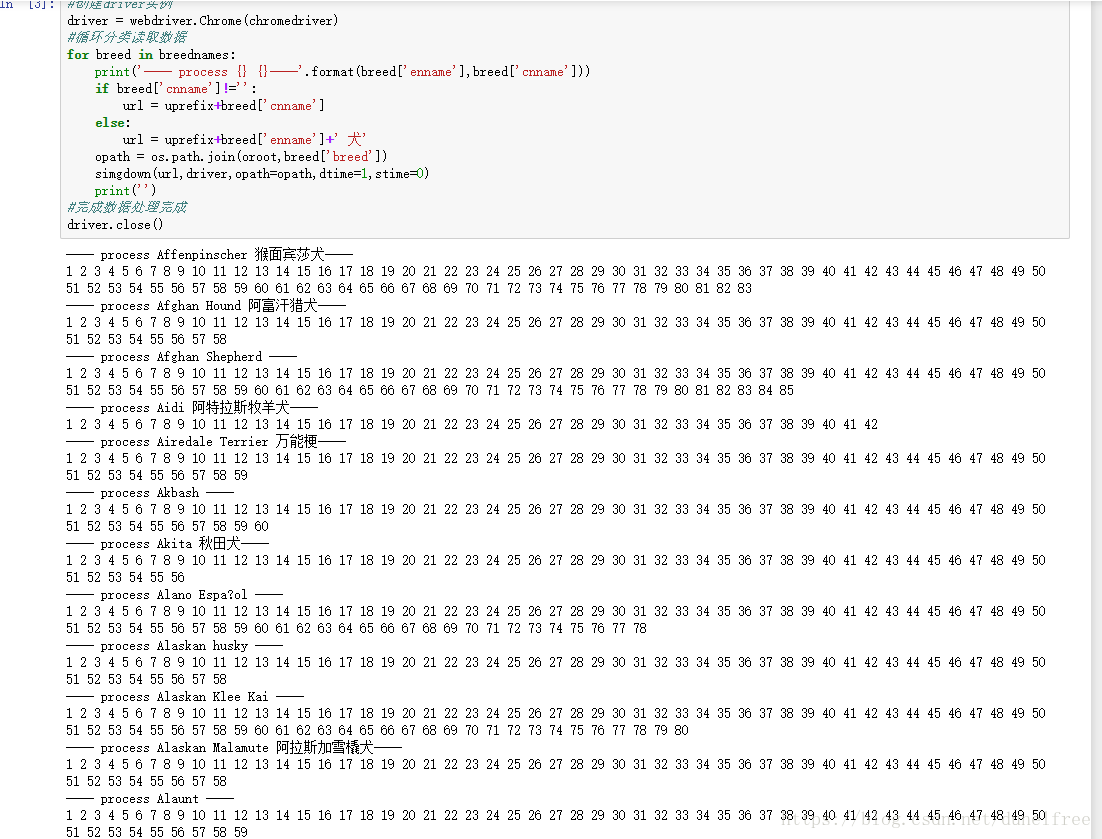
30分钟 VS 1.5天。30分钟做出来的东西还能根据需要调整搜索关键词,1.5天的scrapy由于全都扎到scrapy的细节中根本就没机会去完善相关功能,能跑起来就不错了。不过我也不能否认因为scrapy才了解到了js渲染和selenium。估计以后会经常用selenium。程序跑的很顺畅,大约50分钟就给我下载了514个分类31407个文件大约1.5G。
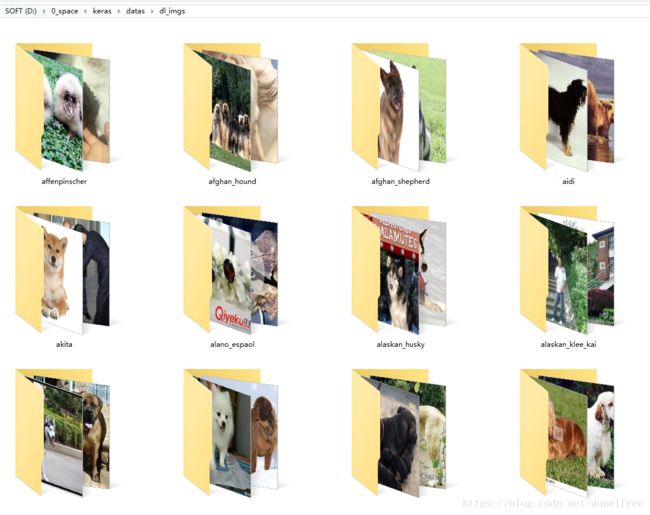
看着这些成果,我心满意足。不过从图片细节中也能看到还是不合格,还有很多无关的图片,下一步需要上cnn大法把没用的图片都去除了。
简单总结一下,我为什么一上来就想用scrapy?因为太有名了,太安利了,就像广告。
我没有专心的分析自己的想法和需求,就直接去想解决方案了,我在这个解决方案里挣扎了很久。
最终痛苦的1.5天后我做出来一辆改装宾利,然后看这个改装宾利别别扭扭的走在我家的乡村小道上,心里五味杂陈。
(这样下去一个月也干不出来个什么东西啊,房贷怎么办?车险怎么办?孩子上学怎么办?)内心戏请忽略
猛然发现好像不太对啊。这个宾利好像不是我想要的诶,我好像有个手推车就够了啊!?
然后我30分钟愉快的做了个小推车,看他欢乐的跑在乡村乡道上,我觉得心满意足。
我忽然想起一些往事:
1.为了读取一个列表,装了一星期hibernate,最后把一个pojo充满形成列表……
2.两三个类,鼓捣两三天spring,终于让他们跑起来了。然后发现好像还是互相依赖
3.为了让P2P平台能够对接银行,重新设计整个账务系统。驱动100多号人忙了半年多(虽然很必要,但也许有更简单的办法)
4.为了让正和多平台用户,重新设计了统一用户中心……
也许有些事情可以做的更简单。现成的框架,模块,会给你一个答案,但这些可能会让你忘了你内心真正的答案。追寻内心真正的答案,跟着那一点初心走,才不会迷失。
推荐阅读:
独立、坚持、完美主义:他一个人花了5年时间制作了《星露谷物语》
读后感,不要被社会分工限制住,按照你的内心需要去做,需要程序,就做程序,需要图片就做图片,需要音乐就做音乐。不要等着别人满足你,要自己满足自己。