HttpServletResponse接口
HttpServletResponse接口
HttpServletResponse接口是ServletResponse的子接口,HttpServlet类的重载service()方法及doGet()和doPost()等方法都有一个HttpServletResponse类型参数:
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
HttpServletResponse 接口提供了与 HTTP 协议相关的一些方法,Servlet 可通过这些方法来设置HTTP响应头或向客户端写Cookie。
addHeader(String name, String value):向HTTP响应头中加入一项内容。
sendError(int sc):向客户端发送一个代表特定错误的HTTP响应状态代码。
sendError(int sc, String msg):向客户端发送一个代表特定错误的HTTP响应状态代码,并且发送具体的错误消息。
setHeader(String name, String value):设置HTTP响应头中的一项内容。如果在响应头中已经存在这项内容,那么原先所做的设置将被覆盖。
setStatus(int sc):设置HTTP响应的状态代码。
addCookie(Cookie cookie):向HTTP响应中加入一个Cookie。
在HTTPServletResponse接口中定义了一些代表HTTP响应状态代码的静态常量,如下所示。
HTTPServletResponse. SC_BAD_REQUEST:对应的响应状态代码为400。
HTTPServletResponse. SC_FOUND:对应的响应状态代码为302。
HTTPServletResponse. SC_METHOD_NOT_ALLOWED:对应的响应状态代码为405。
HTTPServletResponse. SC_NON_AUTHORITATIVE_INFORMATION:对应的响应状态代码为203。
HTTPServletResponse. SC_FORBIDDEN:对应的响应状态代码为403。
HTTPServletResponse. SC_NOT_FOUND:对应的响应状态代码为404。
HTTPServletResponse. SC_OK:对应的响应状态代码为200。
例程4-4的HelloServlet类的doGet()方法先得到username请求参数,对其进行中文字符编码转换,然后判断username参数是否为null。如果满足条件,就直接返回一个代表特定错误的 403 响应状态代码;否则,就通过 HttpServletResponse 对象的getWriter()方法得到一个PrintWriter对象,然后通过PrintWriter对象来输出一个HTML文档。
例程4-4 HelloServlet.java
public class HelloServlet extends HttpServlet {
public void doGet(HttpServletRequest request,HttpServletResponse response)
throws ServletException, IOException {
//获得username请求参数
String username=request.getParameter("username"); /*字符编码转换。 HTTP请求的默认字符编码为ISO-8859-1,如果请求中包含中文, 需要把它转换为GB2312中文编码。*/ if(username!=null)
username=new String(username.getBytes("ISO-8859-1"),"GB2312"); if(username==null){
//仅仅为了演示response.sendError()的用法。
response.sendError(response.SC_FORBIDDEN);
return;
} //设置HTTP响应的正文的MIME类型及字符编码
response.setContentType("text/html;charset=GB2312"); /*输出HTML文档*/
PrintWriter out = response.getWriter();
out.println(" System.out.println("before close():"+response.isCommitted()); //false
out.close(); //关闭PrintWriter
System.out.println("after close():"+response.isCommitted()); //true
}
} |
Tips
为了节省篇幅,本书列出的部分类的源代码省略了开头的 package 语句和import语句。在本书附赠光盘中提供了范例的完整源代码。
以上HelloServlet类利用HttpServletResponse对象的setContentType()方法来设置响应正文的MIME类型及字符编码。“text/html”表示响应正文为HTML文档,“GB2312”表示响应正文采用中文字符编码。以下3种方式是等价的,都能设置HTTP响应正文的MIME类型及字符编码:
//方式一
response.setContentType("text/html;charset=GB2312");
//方式二
response.setContentType("text/html");
response.setCharacterEncoding("GB2312");
//方式三
response.setHeader("Content-type","text/html;charset=GB2312");
|
HelloServlet类的service()方法最后调用PrintWriter对象的close()方法关闭底层输出流,该方法在关闭输出流之前会先把缓冲区内的数据提交到客户端。因此在调用PrintWriter 对象的 close()方法之前,response.isCommitted()方法返回 false;而在调用PrintWriter对象的close()方法之后,response.isCommitted()方法返回true。HelloServlet类的service()方法中的“System.out.println(…)”语句把内容打印到Tomcat服务器所在的控制台。
Request 的 sendError( )方法
形式: sendError(int errnum )说明:用来向客户端发送错误信息,这对调试程序有很大帮助。常用的常量级错误代码有:
SC_CONTINUE, 状态码是100,表示客户端无法连接。
SC_SWITHING_PROTOCOLS,状态码是101,表示服务器正向报头中注明的协议切换。
SC_OK,状态码是200.表示请求被成功处理。
SC_CREATED,状态码是201,表示请求被成功处理,并在服务器方创建了一个新的资源。
SC_ACCEPTED,状态码是202,表示请求正在被处理,但尚未完成。
SC_NON_AUTHORITATIVE_INFORMATION,状态码是203,表示客户端所表达的mate信息并非来自服务器。
SC_NO_CONTENT,状态码是204,表示请求被成功处理,但没有新的信息返回。
SC_RESET_CONTENT,状态码是205,表示导致请求被发送的文档视图应该重置。
SC_PARTIAL_CONTENT,状态码是206,表示服务器已经完成对资源的GET请求。
SC_MULTI_CHOICES,状态码是300,表示对应于一系列表述的被请求资源都有明确的位置。
SC_MOVED_PERMANENTLY,状态码是301,表示请求所申请的资源已经被移到一个新的地方,并且将来的参考点在请求中应当使用一个新的URL.
SC_MOVED_TEMPORARILY,状态码是302,表示请求所申请的资源已经被移到一个新的地方,并且将来的参考点在请求中仍使用原来的URL.
SC_SEE_OTHER,状态码是303,表示请求的响应可以在一个不同的URL中找到。
SC_NOT_MODIFIED,状态码是304,表示一个有条件的GET操作发现资源可以利用,且没有被改变。
SC_USE_PROXY,状态码是305,表示被请求的资源必须通过特定位置的代理来访问。
SC_BAD_REQUEST,状态码是400,表示客户发出的请求句法不正确。
SC_UNAUTHORIZED,状态码是401,表示请求HTTP认证。
SC_PAYMENT_REQUIRED,状态码是402,表示为以后的使用保留。
SC_FORBIDDEN,状态码是403,表示服务器明白客户的请求,但拒绝响应。
SC_NOT_FAND,状态码是404,表示所请求的资源不可用。
SC_METHOD_NOT_ALLOWED,状态码是405,表示在请求行中标示的方法不允许对请求URL所标明的资源使用。
SC_NOT_ACCEPTTABLE,状态码是406,表示被请求的资源只能响应实体,而且此符合请求所发送的可接受头部域的实体的确包含不可接受的内容。
SC_PHOXY_AUTHENTICATION_REQUIRED,状态码是407,表示客户端必须先向代理验证。
一、HttpServletResponse对象介绍

HttpServletResponse对象代表服务器的响应。这个对象中封装了向客户端发送数据、发送响应头,发送响应状态码的方法。查看HttpServletResponse的API,可以看到这些相关的方法。
1.1、负责向客户端(浏览器)发送数据的相关方法

1.2、负责向客户端(浏览器)发送响应头的相关方法


1.3、负责向客户端(浏览器)发送响应状态码的相关方法
![]()
1.4、响应状态码的常量
HttpServletResponse定义了很多状态码的常量(具体可以查看Servlet的API),当需要向客户端发送响应状态码时,可以使用这些常量,避免了直接写数字,常见的状态码对应的常量:
状态码404对应的常量
![]()
状态码200对应的常量

状态码500对应的常量
![]()
二、HttpServletResponse对象常见应用
2.1、使用OutputStream流向客户端浏览器输出中文数据
使用OutputStream流输出中文注意问题:
在服务器端,数据是以哪个码表输出的,那么就要控制客户端浏览器以相应的码表打开,比如:outputStream.write("中国".getBytes("UTF-8"));使用OutputStream流向客户端浏览器输出中文,以UTF-8的编码进行输出,此时就要控制客户端浏览器以UTF-8的编码打开,否则显示的时候就会出现中文乱码,那么在服务器端如何控制客户端浏览器以以UTF-8的编码显示数据呢?可以通过设置响应头控制浏览器的行为,例如:response.setHeader("content-type", "text/html;charset=UTF-8");通过设置响应头控制浏览器以UTF-8的编码显示数据。
范例:使用OutputStream流向客户端浏览器输出"中国"这两个汉字
![]()
1 package gacl.response.study;
2
3 import java.io.IOException;
4 import java.io.OutputStream;
5 import javax.servlet.ServletException;
6 import javax.servlet.http.HttpServlet;
7 import javax.servlet.http.HttpServletRequest;
8 import javax.servlet.http.HttpServletResponse;
9
10 public class ResponseDemo01 extends HttpServlet {
11
12 private static final long serialVersionUID = 4312868947607181532L;
13
14 public void doGet(HttpServletRequest request, HttpServletResponse response)
15 throws ServletException, IOException {
16 outputChineseByOutputStream(response);//使用OutputStream流输出中文
17 }
18
19 /**
20 * 使用OutputStream流输出中文
21 * @param request
22 * @param response
23 * @throws IOException
24 */
25 public void outputChineseByOutputStream(HttpServletResponse response) throws IOException{
26 /**使用OutputStream输出中文注意问题:
27 * 在服务器端,数据是以哪个码表输出的,那么就要控制客户端浏览器以相应的码表打开,
28 * 比如:outputStream.write("中国".getBytes("UTF-8"));//使用OutputStream流向客户端浏览器输出中文,以UTF-8的编码进行输出
29 * 此时就要控制客户端浏览器以UTF-8的编码打开,否则显示的时候就会出现中文乱码,那么在服务器端如何控制客户端浏览器以以UTF-8的编码显示数据呢?
30 * 可以通过设置响应头控制浏览器的行为,例如:
31 * response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据
32 */
33 String data = "中国";
34 OutputStream outputStream = response.getOutputStream();//获取OutputStream输出流
35 response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
36 /**
37 * data.getBytes()是一个将字符转换成字节数组的过程,这个过程中一定会去查码表,
38 * 如果是中文的操作系统环境,默认就是查找查GB2312的码表,
39 * 将字符转换成字节数组的过程就是将中文字符转换成GB2312的码表上对应的数字
40 * 比如: "中"在GB2312的码表上对应的数字是98
41 * "国"在GB2312的码表上对应的数字是99
42 */
43 /**
44 * getBytes()方法如果不带参数,那么就会根据操作系统的语言环境来选择转换码表,如果是中文操作系统,那么就使用GB2312的码表
45 */
46 byte[] dataByteArr = data.getBytes("UTF-8");//将字符转换成字节数组,指定以UTF-8编码进行转换
47 outputStream.write(dataByteArr);//使用OutputStream流向客户端输出字节数组
48 }
49
50 public void doPost(HttpServletRequest request, HttpServletResponse response)
51 throws ServletException, IOException {
52 doGet(request, response);
53 }
54
55 }
![]()
运行结果如下:

客户端浏览器接收到数据后,就按照响应头上设置的字符编码来解析数据,如下所示:
2.2、使用PrintWriter流向客户端浏览器输出中文数据
使用PrintWriter流输出中文注意问题:
在获取PrintWriter输出流之前首先使用"response.setCharacterEncoding(charset)"设置字符以什么样的编码输出到浏览器,如:response.setCharacterEncoding("UTF-8");设置将字符以"UTF-8"编码输出到客户端浏览器,然后再使用response.getWriter();获取PrintWriter输出流,这两个步骤不能颠倒,如下:
1 response.setCharacterEncoding("UTF-8");//设置将字符以"UTF-8"编码输出到客户端浏览器
2 /**
3 * PrintWriter out = response.getWriter();这句代码必须放在response.setCharacterEncoding("UTF-8");之后
4 * 否则response.setCharacterEncoding("UTF-8")这行代码的设置将无效,浏览器显示的时候还是乱码
5 */
6 PrintWriter out = response.getWriter();//获取PrintWriter输出流
然后再使用response.setHeader("content-type", "text/html;charset=字符编码");设置响应头,控制浏览器以指定的字符编码编码进行显示,例如:
1 //通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
2 response.setHeader("content-type", "text/html;charset=UTF-8");
除了可以使用response.setHeader("content-type", "text/html;charset=字符编码");设置响应头来控制浏览器以指定的字符编码编码进行显示这种方式之外,还可以用如下的方式来模拟响应头的作用
1 /**
2 * 多学一招:使用HTML语言里面的标签来控制浏览器行为,模拟通过设置响应头控制浏览器行为
3 *response.getWriter().write("");
4 * 等同于response.setHeader("content-type", "text/html;charset=UTF-8");
5 */
6 response.getWriter().write("");
范例:使用PrintWriter流向客户端浏览器输出"中国"这两个汉字
![]()
1 package gacl.response.study;
2
3 import java.io.IOException;
4 import java.io.OutputStream;
5 import java.io.PrintWriter;
6 import javax.servlet.ServletException;
7 import javax.servlet.http.HttpServlet;
8 import javax.servlet.http.HttpServletRequest;
9 import javax.servlet.http.HttpServletResponse;
10
11 public class ResponseDemo01 extends HttpServlet {
12
13 private static final long serialVersionUID = 4312868947607181532L;
14
15 public void doGet(HttpServletRequest request, HttpServletResponse response)
16 throws ServletException, IOException {
17 outputChineseByPrintWriter(response);//使用PrintWriter流输出中文
18 }
19
20 /**
21 * 使用PrintWriter流输出中文
22 * @param request
23 * @param response
24 * @throws IOException
25 */
26 public void outputChineseByPrintWriter(HttpServletResponse response) throws IOException{
27 String data = "中国";
28
29 //通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
30 //response.setHeader("content-type", "text/html;charset=UTF-8");
31
32 response.setCharacterEncoding("UTF-8");//设置将字符以"UTF-8"编码输出到客户端浏览器
33 /**
34 * PrintWriter out = response.getWriter();这句代码必须放在response.setCharacterEncoding("UTF-8");之后
35 * 否则response.setCharacterEncoding("UTF-8")这行代码的设置将无效,浏览器显示的时候还是乱码
36 */
37 PrintWriter out = response.getWriter();//获取PrintWriter输出流
38 /**
39 * 多学一招:使用HTML语言里面的标签来控制浏览器行为,模拟通过设置响应头控制浏览器行为
40 * out.write("");
41 * 等同于response.setHeader("content-type", "text/html;charset=UTF-8");
42 */
43 out.write("");
44 out.write(data);//使用PrintWriter流向客户端输出字符
45 }
46
47 public void doPost(HttpServletRequest request, HttpServletResponse response)
48 throws ServletException, IOException {
49 doGet(request, response);
50 }
51 }
![]()
当需要向浏览器输出字符数据时,使用PrintWriter比较方便,省去了将字符转换成字节数组那一步。
2.3、使用OutputStream或者PrintWriter向客户端浏览器输出数字
比如有如下的代码:
![]()
1 package gacl.response.study;
2
3 import java.io.IOException;
4 import java.io.OutputStream;
5 import java.io.PrintWriter;
6
7 import javax.servlet.ServletException;
8 import javax.servlet.http.HttpServlet;
9 import javax.servlet.http.HttpServletRequest;
10 import javax.servlet.http.HttpServletResponse;
11
12 public class ResponseDemo01 extends HttpServlet {
13
14 private static final long serialVersionUID = 4312868947607181532L;
15
16 public void doGet(HttpServletRequest request, HttpServletResponse response)
17 throws ServletException, IOException {
18
19 outputOneByOutputStream(response);//使用OutputStream输出1到客户端浏览器
20
21 }
22
23 /**
24 * 使用OutputStream流输出数字1
25 * @param request
26 * @param response
27 * @throws IOException
28 */
29 public void outputOneByOutputStream(HttpServletResponse response) throws IOException{
30 response.setHeader("content-type", "text/html;charset=UTF-8");
31 OutputStream outputStream = response.getOutputStream();
32 outputStream.write("使用OutputStream流输出数字1:".getBytes("UTF-8"));
33 outputStream.write(1);
34 }
35
36 }
![]()
运行上面代码显示的结果如下:
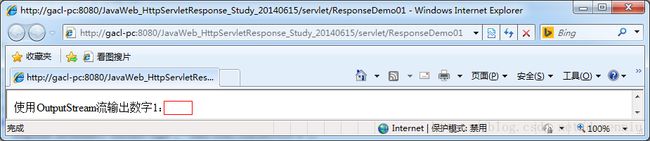
运行的结果和我们想象中的不一样,数字1没有输出来,下面我们修改一下上面的outputOneByOutputStream方法的代码,修改后的代码如下:
![]()
1 /**
2 * 使用OutputStream流输出数字1
3 * @param request
4 * @param response
5 * @throws IOException
6 */
7 public void outputOneByOutputStream(HttpServletResponse response) throws IOException{
8 response.setHeader("content-type", "text/html;charset=UTF-8");
9 OutputStream outputStream = response.getOutputStream();
10 outputStream.write("使用OutputStream流输出数字1:".getBytes("UTF-8"));
11 //outputStream.write(1);
12 outputStream.write((1+"").getBytes());
13 }
![]()
1+""这一步是将数字1和一个空字符串相加,这样处理之后,数字1就变成了字符串1了,然后再将字符串1转换成字节数组使用OutputStream进行输出,此时看到的结果如下:

这次可以看到输出来的1了,这说明了一个问题:在开发过程中,如果希望服务器输出什么浏览器就能看到什么,那么在服务器端都要以字符串的形式进行输出。
如果使用PrintWriter流输出数字,那么也要先将数字转换成字符串后再输出,如下:
![]()
1 /**
2 * 使用PrintWriter流输出数字1
3 * @param request
4 * @param response
5 * @throws IOException
6 */
7 public void outputOneByPrintWriter(HttpServletResponse response) throws IOException{
8 response.setHeader("content-type", "text/html;charset=UTF-8");
9 response.setCharacterEncoding("UTF-8");
10 PrintWriter out = response.getWriter();//获取PrintWriter输出流
11 out.write("使用PrintWriter流输出数字1:");
12 out.write(1+"");
13 }
![]()
2.4、文件下载
文件下载功能是web开发中经常使用到的功能,使用HttpServletResponse对象就可以实现文件的下载
文件下载功能的实现思路:
1.获取要下载的文件的绝对路径
2.获取要下载的文件名
3.设置content-disposition响应头控制浏览器以下载的形式打开文件
4.获取要下载的文件输入流
5.创建数据缓冲区
6.通过response对象获取OutputStream流
7.将FileInputStream流写入到buffer缓冲区
8.使用OutputStream将缓冲区的数据输出到客户端浏览器
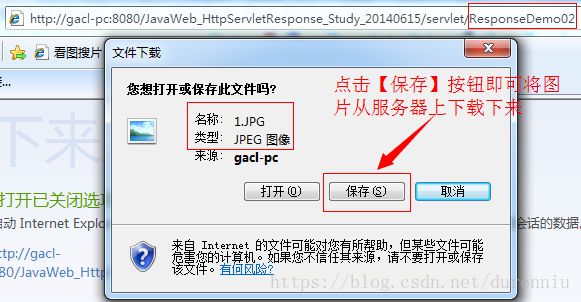
范例:使用Response实现文件下载
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
运行结果如下所示:
范例:使用Response实现中文文件下载
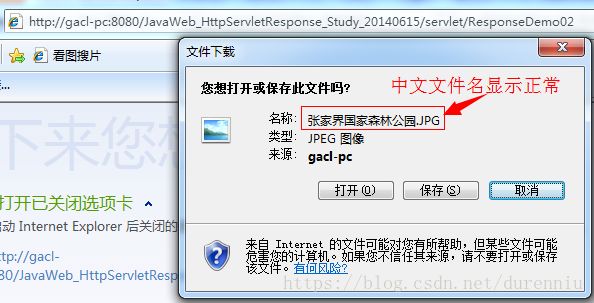
下载中文文件时,需要注意的地方就是中文文件名要使用URLEncoder.encode方法进行编码(URLEncoder.encode(fileName, "字符编码")),否则会出现文件名乱码。
![]()
1 package gacl.response.study;
2 import java.io.FileInputStream;
3 import java.io.FileNotFoundException;
4 import java.io.FileReader;
5 import java.io.IOException;
6 import java.io.InputStream;
7 import java.io.OutputStream;
8 import java.io.PrintWriter;
9 import java.net.URLEncoder;
10 import javax.servlet.ServletException;
11 import javax.servlet.http.HttpServlet;
12 import javax.servlet.http.HttpServletRequest;
13 import javax.servlet.http.HttpServletResponse;
14 /**
15 * @author gacl
16 * 文件下载
17 */
18 public class ResponseDemo02 extends HttpServlet {
19
20 public void doGet(HttpServletRequest request, HttpServletResponse response)
21 throws ServletException, IOException {
22 downloadChineseFileByOutputStream(response);//下载中文文件
23 }
24
25 /**
26 * 下载中文文件,中文文件下载时,文件名要经过URL编码,否则会出现文件名乱码
27 * @param response
28 * @throws FileNotFoundException
29 * @throws IOException
30 */
31 private void downloadChineseFileByOutputStream(HttpServletResponse response)
32 throws FileNotFoundException, IOException {
33 String realPath = this.getServletContext().getRealPath("/download/张家界国家森林公园.JPG");//获取要下载的文件的绝对路径
34 String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);//获取要下载的文件名
35 //设置content-disposition响应头控制浏览器以下载的形式打开文件,中文文件名要使用URLEncoder.encode方法进行编码,否则会出现文件名乱码
36 response.setHeader("content-disposition", "attachment;filename="+URLEncoder.encode(fileName, "UTF-8"));
37 InputStream in = new FileInputStream(realPath);//获取文件输入流
38 int len = 0;
39 byte[] buffer = new byte[1024];
40 OutputStream out = response.getOutputStream();
41 while ((len = in.read(buffer)) > 0) {
42 out.write(buffer,0,len);//将缓冲区的数据输出到客户端浏览器
43 }
44 in.close();
45 }
46
47 public void doPost(HttpServletRequest request, HttpServletResponse response)
48 throws ServletException, IOException {
49 doGet(request, response);
50 }
51 }
![]()
运行结果如下所示:
文件下载注意事项:编写文件下载功能时推荐使用OutputStream流,避免使用PrintWriter流,因为OutputStream流是字节流,可以处理任意类型的数据,而PrintWriter流是字符流,只能处理字符数据,如果用字符流处理字节数据,会导致数据丢失。
范例:使用PrintWriter流下载文件
![]()
1 package gacl.response.study;
2 import java.io.FileInputStream;
3 import java.io.FileNotFoundException;
4 import java.io.FileReader;
5 import java.io.IOException;
6 import java.io.InputStream;
7 import java.io.OutputStream;
8 import java.io.PrintWriter;
9 import java.net.URLEncoder;
10 import javax.servlet.ServletException;
11 import javax.servlet.http.HttpServlet;
12 import javax.servlet.http.HttpServletRequest;
13 import javax.servlet.http.HttpServletResponse;
14 /**
15 * @author gacl
16 * 文件下载
17 */
18 public class ResponseDemo02 extends HttpServlet {
19
20 public void doGet(HttpServletRequest request, HttpServletResponse response)
21 throws ServletException, IOException {
22 downloadFileByPrintWriter(response);//下载文件,通过PrintWriter流
23 }
24
25 /**
26 * 下载文件,通过PrintWriter流,虽然也能够实现下载,但是会导致数据丢失,因此不推荐使用PrintWriter流下载文件
27 * @param response
28 * @throws FileNotFoundException
29 * @throws IOException
30 */
31 private void downloadFileByPrintWriter(HttpServletResponse response)
32 throws FileNotFoundException, IOException {
33 String realPath = this.getServletContext().getRealPath("/download/张家界国家森林公园.JPG");//获取要下载的文件的绝对路径
34 String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);//获取要下载的文件名
35 //设置content-disposition响应头控制浏览器以下载的形式打开文件,中文文件名要使用URLEncoder.encode方法进行编码
36 response.setHeader("content-disposition", "attachment;filename="+URLEncoder.encode(fileName, "UTF-8"));
37 FileReader in = new FileReader(realPath);
38 int len = 0;
39 char[] buffer = new char[1024];
40 PrintWriter out = response.getWriter();
41 while ((len = in.read(buffer)) > 0) {
42 out.write(buffer,0,len);//将缓冲区的数据输出到客户端浏览器
43 }
44 in.close();
45 }
46
47 public void doPost(HttpServletRequest request, HttpServletResponse response)
48 throws ServletException, IOException {
49 doGet(request, response);
50 }
51 }
![]()
运行结果如下:
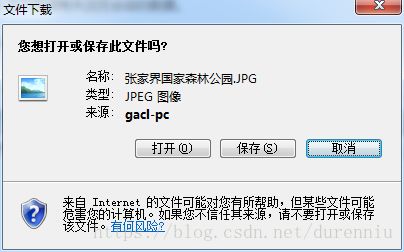
正常弹出下载框,此时我们点击【保存】按钮将文件下载下来,如下所示:
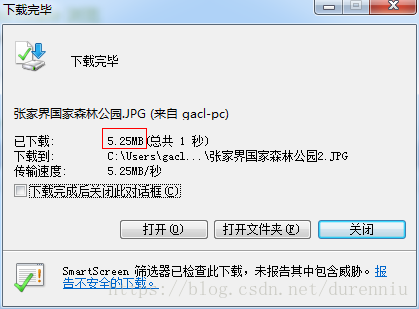
可以看到,只下载了5.25MB,而这张图片的原始大小却是

这说明在下载的时候数据丢失了,所以下载不完全,所以这张图片虽然能够正常下载下来,但是却是无法打开的,因为丢失掉了部分数据,如下所示:

所以使用PrintWriter流处理字节数据,会导致数据丢失,这一点千万要注意,因此在编写下载文件功能时,要使用OutputStream流,避免使用PrintWriter流,因为OutputStream流是字节流,可以处理任意类型的数据,而PrintWriter流是字符流,只能处理字符数据,如果用字符流处理字节数据,会导致数据丢失。
http://www.cnblogs.com/xdp-gacl/p/3789624.html