堆溢出基础——ptmalloc源码分析
0x00 前言
决定学习堆溢出很久了但却因为内心对源码的恐惧一直不愿意解出这块内容,于是在实习面试的时候被问到linux的内存管理一脸懵逼啥都不会。。。。痛定思痛利用一周末时间将堆的实现硬着头皮看了一遍,现在记录如下。
参考内容:
CTFwiki 深入理解堆的实现
Glibc内存管理Ptmalloc2源代码分析
0x01 操作系统内存分配的相关函数
brk()系统调用与sbrk()库函数
内核数据结构 mm_struct (在include/linux/mm_types.h中定义)中的成员变量 start_code 和 end_code 是进程代码段的起始和终止地址,start_data 和 end_data 是进程数据段的起始和终止地址,start_stack 是进程堆栈 段起始地址,start_brk 是进程动态内存分配起始地址(堆的起始地址),还有一个 brk(堆 的当前最后地址),就是动态内存分配当前的终止地址。。brk()是一个非常简单的系统调用, 只是简单地改变 mm_struct 结构的成员变量 brk 的值,从而达到改变堆大小的目的。
这两个函数的定义:
#include
int brk(void *addr); //参数为堆的新边界
void *sbrk(intptr_t increment); //参数 increment 为 0 时,sbrk()返回的是进程的当前 brk 值, increment 为正数时扩展 brk 值,当 increment 为负值时收缩 brk 值brk()系统调用源码分析:待补充
mmap()&munmap()
mmap()函数将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的 大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap 执行相反的操 作,删除特定地址区域的对象映射。
函数定义如下:
#include
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length); 源码分析:待补充
参数说明:
addr:映射区的开始地址
length:映射区长度
prot:期望的内存保护标志,不能与文件的打开模式冲突。
- PROT_EXEC //页内容可以被执行,ptmalloc 中没有使用
- PROT_READ //页内容可以被读取,ptmalloc 直接用 mmap 分配内存并立即返回给用户时 设置该标志
- PROT_WRITE //页可以被写入,ptmalloc 直接用 mmap 分配内存并立即返回给用户时设 置该标志
- PROT_NONE //页不可访问,ptmalloc 用 mmap 向系统“批发”一块内存进行管理时设置 该标志
flags:指定映射对象的类型,映射选项和映射页是否可以共享。
- MAP_FIXED //使用指定的映射起始地址,如果由 start 和 len 参数指定的内存区重叠于现 存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。Ptmalloc 在回收从系统中“批发”的内存时设置该标志
- MAP_PRIVATE //建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。 这个标志和以上标志是互斥的,只能使用其中一个。Ptmalloc每次调用mmap时都设置该标记
- MAP_NORESERVE //不要为这个映射保留交换空间。当交换空间被保留,对映射区修改 的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信 号。Ptmalloc 向系统“批发”内存块时设置该标志。
- MAP_ANONYMOUS //匿名映射,映射区不与任何文件关联。Ptmalloc 每次调用 mmap 都设置该标志。
fd:有效的文件描述词。如果 MAP_ANONYMOUS 被设定,为了兼容问题,其值应为-1。
offset:被映射对象内容的起点。
0x02 堆的数据结构
1、Main_arena与non_main_arena
Main_arena:
主分配区,每个进程可以自主分配的内存区域。每个进程在向系统申请内存时,系统都会给它一段较大的内存,这段内存成为arena,以后再有申请内存的请求时,会直接从arena中获取内存,而不用向系统申请,从而提高效率。
non_main_arena:
非主分配区。为了能够支持多线程,增加了non_main_arena支持,non_main_arena和main_arena作用相同,提高线程申请内存的效率。
批发与零售关系
主分配 区可以访问进程的 heap 区域和 mmap 映射区域,也就是说主分配区可以使用 sbrk 和 mmap 向操作系统申请虚拟内存。而非主分配区只能访问进程的 mmap 映射区域,主分配区每 次使用 mmap()向操作系统“批发”HEAP_MAX_SIZE(32 位系统上默认为 1MB,64 位系统默 认为 64MB)大小的虚拟内存,当用户向非主分配区请求分配内存时再切割成小块“零售” 出去,毕竟系统调用是相对低效的,直接从用户空间分配内存快多了
2、Chunk
数据结构定义:
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};Ptmalloc 采用边界标记法将内存划分成很多块,从而对内存的分配与回收进行管理(边界标记法,顾名思义)
malloc_chunk各个域的含义:
- prev_size:如果前一个 chunk 是空闲的,该域表示前一个 chunk 的大小,如果前一个 chunk 不空闲,该域无意义。
- size:当前 chunk 的大小,并且记录了当前 chunk 和前一个 chunk 的一些属性,包括前一个 chunk 是否在使用中,当前 chunk 是否是通过 mmap 获得的内存,当前 chunk 是否属于 非主分配区。
- fd 和 bk:指针 fd 和 bk 只有当该 chunk 块空闲时才存在,其作用是用于将对应的空闲 chunk 块加入到空闲 chunk 块链表中统一管理,如果该 chunk 块被分配给应用程序使用,那 么这两个指针也就没有用(该 chunk 块已经从空闲链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费
- fd_nextsize 和 bk_nextsize:当当前的 chunk 存在于 large bins 中时,large bins 中的空闲 chunk 是按照大小排序的,但同一个大小的 chunk 可能有多个,增加了这两个字段可以加快 遍历空闲 chunk,并查找满足需要的空闲 chunk,fd_nextsize 指向下一个比当前 chunk 大小 大的第一个空闲 chunk,bk_nextszie 指向前一个比当前 chunk 大小小的第一个空闲 chunk。 如果该 chunk 块被分配给应用程序使用,那么这两个指针也就没有用(该 chunk 块已经从 size 链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费。
因此可以获得chunk在两种状态下的结构:
使用状态(已分配)下的chunk:
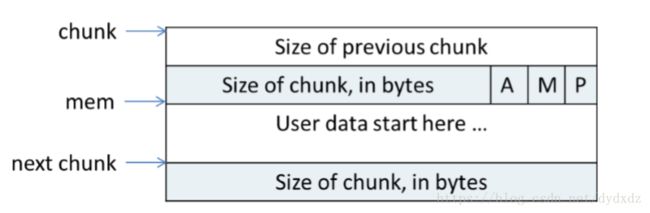
- chunk:指向一个chunk的开始,一个chunk包含用户内存区域及控制信息
- mem:真正返回给用户的内存指针(不包含控制信息)
- P:标志前一个块是否在使用中,0为空闲(只有该为为0时prev_size区域才有效,表示前一个chunk的size)
- M:标志该chunk是从mmap映射区分配(M=1)还是从heap区域分配的(M=0)
- A:标志该chunk是属于主分配区(0)还是非主分配区(1)
空闲状态下的chunk:
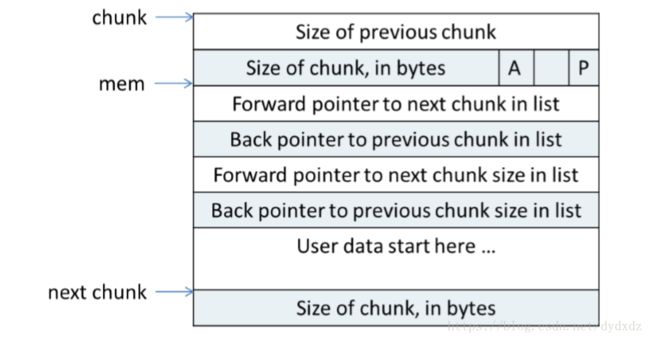
chunk空闲时,M状态不存在,只有AP状态。
用户内存空间区域存储了4个指针:fd、bk、fd_nextsize、bk_nextsize,这四个指针的作用在前面有提到过
chunk相关宏定义 参见CTFwiki,里面有很详细的介绍,这些宏定义在之后的源代码分析中都用的到
3、分箱式内存管理(bins)
对于空闲的 chunk,ptmalloc 采用分箱式内存管理方式,根据空闲 chunk 的大小和处于 的状态将其放在四个不同的 bin 中,这四个空闲 chunk 的容器包括 fast bins,unsorted bin, small bins 和 large bins。Fast bins 是小内存块的高速缓存,当一些大小小于 64 字节的 chunk 被回收时,首先会放入 fast bins 中,在分配小内存时,首先会查看 fast bins 中是否有合适的 内存块,如果存在,则直接返回 fast bins 中的内存块,以加快分配速度。Usorted bin 只有一 个,回收的 chunk 块必须先放到 unsorted bin 中,分配内存时会查看 unsorted bin 中是否有 合适的 chunk,如果找到满足条件的 chunk,则直接返回给用户,否则将 unsorted bin 的所 有 chunk 放入 small bins 或是 large bins 中。Small bins 用于存放固定大小的 chunk,共 64 个 bin,最小的 chunk 大小为 16 字节或 32 字节,每个 bin 的大小相差 8 字节或是 16 字节,当 分配小内存块时,采用精确匹配的方式从 small bins 中查找合适的 chunk。Large bins 用于存 储大于等于 512B 或 1024B 的空闲 chunk,这些 chunk 使用双向链表的形式按大小顺序排序, 分配内存时按最近匹配方式从 large bins 中分配 chunk。
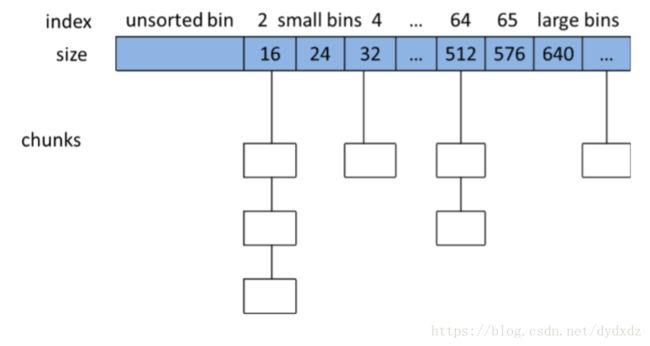
1、Small bins
ptmalloc 维护了 62 个双向环形链表(每个链表都具有链表头节点,加头节点的最大作 用就是便于对链表内节点的统一处理,即简化编程),每一个链表内的各空闲 chunk 的大小 一致,因此当应用程序需要分配某个字节大小的内存空间时直接在对应的链表内取就可以了, 这样既可以很好的满足应用程序的内存空间申请请求而又不会出现太多的内存碎片。我们可 以用如下图来表示在 SIZE_SZ 为 4B 的平台上 ptmalloc 对 512B 字节以下的空闲 chunk 组织方 式(所谓的分箱机制)。
2、Large bins
Large bins 一共包括 63 个 bin, 每个 bin 中的 chunk 大小不是一个固定公差的等差数列,而是分成 6 组 bin,每组 bin 是一个 固定公差的等差数列,每组的 bin 数量依次为 32、16、8、4、2、1,公差依次为 64B、512B、 4096B、32768B、262144B 等。
例如:第一个large_bin的起始地址为512B
3、Unsorted bins
unsorted bin 处于我们之前所说的bin数组下标1处。故而 unsorted bin只有一个链表。Unsorted bin 可以看作是 small bins 和 large bins 的 cache.,以双 向链表管理空闲 chunk,空闲 chunk 不排序,所有的 chunk 在回收时都要先放到 unsorted bin中,分配时,如果在 unsorted bin 中没有合适的 chunk,就会把 unsorted bin 中的所有 chunk 分别加入到所属的 bin 中,然后再在 bin 中分配合适的 chunk
4、Fast bins
fast bins 主要是用于提高小内存的分配效率,默认情况下,对于 SIZE_SZ 为 4B 的平台, 小于 64B 的 chunk 分配请求,对于 SIZE_SZ 为 8B 的平台,小于 128B 的 chunk 分配请求,首 先会查找 fast bins 中是否有所需大小的 chunk 存在(精确匹配),如果存在,就直接返回
有了这些数据结构的知识,可以去研究内存分配与回收的具体实现了。
0x03 内存分配与回收的具体实现
1、内存分配malloc()
Void_t* public_mALLOc(size_t bytes)
{
mstate ar_ptr;
Void_t *victim;
__malloc_ptr_t (*hook) (size_t, __const __malloc_ptr_t)= force_reg (__malloc_hook);
if (__builtin_expect (hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS (0)); 首先检查是否存在内存分配的 hook 函数,如果存在,调用 hook 函数,并返回,hook 函数主要用于进程在创建新线程过程中分配内存,或者支持用户提供的内存分配函数.
arena_lookup(ar_ptr);
arena_lock(ar_ptr, bytes); //获取分配区指针并上锁
if(!ar_ptr)
return 0;
victim = _int_malloc(ar_ptr, bytes); //调用_int_malloc函数分配相应大小内存获取分配区指针,如果获取分配区失败,返回退出,否则,调用_int_malloc()函数分配 内存
_int_malloc() ——核心函数
static void *_int_malloc(mstate av, size_t bytes) {
INTERNAL_SIZE_T nb; /* normalized request size */
unsigned int idx; /* associated bin index */
mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */
INTERNAL_SIZE_T size; /* its size */
int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */
unsigned long remainder_size; /* its size */
unsigned int block; /* bit map traverser */
unsigned int bit; /* bit map traverser */
unsigned int map; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */
mchunkptr bck; /* misc temp for linking */
const char *errstr = NULL;
/*
Convert request size to internal form by adding SIZE_SZ bytes
overhead plus possibly more to obtain necessary alignment and/or
to obtain a size of at least MINSIZE, the smallest allocatable
size. Also, checked_request2size traps (returning 0) request sizes
that are so large that they wrap around zero when padded and
aligned.
*/
checked_request2size(bytes, nb);定义了一堆内部变量,并通过checked_request2size()将所需分配的字节大小转换成chunk大小(添加控制头并对齐)
S1:尝试分配fast_bins
/*
If the size qualifies as a fastbin, first check corresponding bin.
This code is safe to execute even if av is not yet initialized, so we
can try it without checking, which saves some time on this fast path.
*/
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) {
idx = fastbin_index(nb);
mfastbinptr* fb = &fastbin (av, idx);
#ifdef ATOMIC_FASTBINS
mchunkptr pp = *fb;
do
{
victim = pp;
if (victim == NULL)
break;
}
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim))!= victim);
#else
victim = *fb;
#endif
if (victim != 0) {
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0)) {
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr (check_action, errstr, chunk2mem (victim));
}
#ifndef ATOMIC_FASTBINS
*fb = victim->fd;
#endif
check_remalloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
} 这里的部分代码开启是 ATOMIC_FASTBINS 优化,用于防止多线程时产生的错误。我们只想搞清楚代码逻辑,因此可以无视ATOMIC_FASTBINS优化,这样的化只需看下面代码即可
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) {
idx = fastbin_index(nb); //获得对应的fastbin的下标
mfastbinptr* fb = &fastbin (av, idx); // 得到对应的fastbin的头指针
victim = *fb;
if (victim != 0) {
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0))
{
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr (check_action, errstr,chunk2mem (victim));
}
*fb = victim->fd; //将头指针的下一个 chunk 作为空闲 chunk 链表的头部。
check_remalloced_chunk(av, victim, nb);
void *p = chunk2mem(victim); //取出第一个chunk
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}首先根据所需chunk大小获得所需 fast bin 的空 闲 chunk 链表的头指针,然后将头指针的下一个 chunk 作为空闲 chunk 链表的头部。取出第一个chunk,并调用chunk2mem() 函数返回用户所需的内存块。
S2:尝试分配small bin chunk
如果需要分配的大小属于small bin,则会执行以下代码:
/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/
if (in_smallbin_range(nb)) {
// 获取 small bin 的索引
idx = smallbin_index(nb);
// 获取对应 small bin 中的 chunk 指针
bin = bin_at(av, idx);
// 先执行 victim = last(bin),获取 small bin 的最后一个 chunk
// 如果 victim = bin ,那说明该 bin 为空。
// 如果不相等,那么会有两种情况
if ((victim = last(bin)) != bin) {
// 第一种情况,small bin 还没有初始化。
if (victim == 0) /* initialization check */
// 执行初始化,将 fast bins 中的 chunk 进行合并
malloc_consolidate(av);
// 第二种情况,small bin 中存在空闲的 chunk
else {
// 获取 small bin 中倒数第二个 chunk 。
bck = victim->bk;
// 检查 bck->fd 是不是 victim,防止伪造
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
// 设置 victim 对应的 inuse 位
set_inuse_bit_at_offset(victim, nb);
// 修改 small bin 链表,将 small bin 的最后一个 chunk 取出来
bin->bk = bck;
bck->fd = bin;
// 如果不是 main_arena,设置对应的标志
if (av != &main_arena) set_non_main_arena(victim);
// 细致的检查,非调试状态没有作用
check_malloced_chunk(av, victim, nb);
// 将申请到的 chunk 转化为对应的 mem 状态
void *p = chunk2mem(victim);
// 如果设置了 perturb_type , 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}
}
}S3:分配large bin chunk
/*
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
*/
else {
idx = largebin_index(nb);
if (have_fastchunks(av))
malloc_consolidate(av);
}如果fast bin和small bin都不符合要求,那就一定是large bin。在分配large bin的时候,并不会直接去分配,而是先检查是否存在fast bin,如果存在则调用malloc_consolidate()函数合并fast bin中的chunk,并将这些空闲chunk加入到unsorted bin中。
遍历unsorted bin
// 如果 unsorted bin 不为空
// First In First Out
while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) {
// victim 为 unsorted bin 的最后一个 chunk
// bck 为 unsorted bin 的倒数第二个 chunk
bck = victim->bk;
// 判断得到的 chunk 是否满足要求,不能过小,也不能过大
// 一般 system_mem 的大小为132K
if (__builtin_expect(chunksize_nomask(victim) <= 2 * SIZE_SZ, 0) ||
__builtin_expect(chunksize_nomask(victim) > av->system_mem, 0))
malloc_printerr(check_action, "malloc(): memory corruption",
chunk2mem(victim), av);
// 得到victim对应的chunk大小。
size = chunksize(victim);先写到这儿了,剩下的考完试再写(未完待续。。。)