【深度学习】日常笔记16
可以将pd.DataFrame数据结构理解为类似于Excel中的表格。pd.DataFrame是pandas库提供的一个二维数据结构,用于存储和操作具有行和列的数据。它类似于Excel中的工作表,其中每一列可以是不同的数据类型(例如整数、浮点数、字符串等)。虽然DataFrame的每一列可以具有不同的数据类型,但在数据分析和建模过程中,通常建议遵守每列(特征列)的数据类型规范。
创建缺失值NaN的代码:
import pandas as pd
data = {'Name': ['John', 'Alice', 'Bob', None, 'Mike'],
'Age': [32, 28, 45, 42, None]}
data = {'A': [1, 2, None, 4, 5],
'B': [1.5, 2.5, None, 4.5, 5.5]}
df['C'] = [None, 2, 3, None, 5] # 也可以使用None指定缺失值
df = pd.DataFrame(data)
独热编码(One-Hot Encoding)是指将分类变量转换为虚拟变量(dummy variables)的一种常见方法。通过独热编码,我们可以将每个类别表示为一个二进制的指示符特征,其中只有一个特征为1,表示当前观测值所属的类别,其余特征都为0。
pd.get_dummies()函数在Pandas中提供了一种方便的方法来执行独热编码。通过设置dummy_na=True参数,可以将缺失值也视为有效的特征值,并为其创建相应的列。
独热编码通常用于在机器学习和数据分析任务中处理分类变量,以便在建模过程中能够更好地利用这些特征。
计算均⽅误差使⽤的是MSELoss类,也称为平⽅L2范数再乘个1/n,MSE全称为Mean Squared Error,L2范数: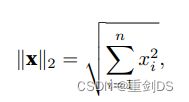 。
。
Adam优化器,常常使用Adam优化器的原因是对初试给定的超参数学习率lr不是很敏感。Adam是一种优化算法的缩写。它代表"Adaptive Moment Estimation"(自适应矩估计)。Adam算法结合了自适应学习率和动量法的优点,广泛应用于深度学习中的参数优化。
Adam算法使用了两个主要的概念:动量(momentum)和自适应学习率。动量可以理解为模拟物体在梯度方向上运动时的惯性,使得参数更新更加平稳。自适应学习率则根据参数的历史梯度信息来自适应地调整学习率,更好地适应不同参数的特性。
Adam算法的主要步骤包括计算梯度的一阶矩估计(即均值)和二阶矩估计(即方差),然后利用这些估计来更新参数。相较于其他传统的优化算法,Adam算法通常能够更快地收敛,并且对于大多数的深度学习任务表现良好。
在进行K折交叉验证时,确保将数据集刚好分成K个fold是理想的情况,但实际应用中可能会遇到无法均匀划分的情况。当数据集的样本数量不能被K整除时,可能会出现以下两种情况:
- 如果样本数量不能被K整除并且余数较小,可以选择将剩余的样本均匀分配到各个fold中。例如,如果有100个样本,要进行5折交叉验证,每个fold将有20个样本。如果有101或102个样本,可以将多出来放到已有的fold中,所以会有1或2个fold中有21个样本,而其余的fold中有20个样本。
- 如果样本数量不能被K整除并且余数较大,可以选择在数据预处理阶段进行调整。例如,可以考虑随机删除一部分样本,使得数据集能够被K整除。这样可以确保每个fold的样本数尽量接近,并且保持数据的随机性。
在实际应用中,了解数据集的特点和目标任务的要求,以及适应性地选择合适的划分策略,是确保K折交叉验证的有效性的关键。
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_loss.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_loss.append(log_rmse(net, test_features, test_labels))
第二重循环的X是一个小批次的特征。X表示每个小批次的特征,而每个小批次包含了batch_size个样本。train_iter是一个数据迭代器,它会根据batch_size将训练数据划分成小批次,并提供每个小批次的特征(X)和标签(y)。因此,在第二重循环中,每次迭代都会处理一个小批次的数据样本。
在每次迭代中,通过for X, y in train_iter语句获取到一个小批次的特征和标签。X表示该小批次的特征,形状为[batch_size, feature_dim],其中batch_size是小批次的大小,feature_dim是特征的维度。y则表示该小批次对应的标签,形状为[batch_size]。
这样做的好处是,通过一次性处理多个样本,可以利用硬件加速的优势,提高训练的效率和速度。同时,通过使用小批次的随机梯度下降(SGD)更新参数,有助于增加模型的泛化能力。
 随便参加了一个kaggle比赛
随便参加了一个kaggle比赛
import torch
from torch import nn
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
net(X)
上面的模型net具有三个层:
- 第一层为 nn.Linear(4, 8),它是一个线性变换层,输入大小为4,输出大小为8。
- 第二层为 nn.ReLU(),它是一个ReLU激活函数层。
- 第三层为 nn.Linear(8, 1),它是另一个线性变换层,输入大小为8,输出大小为1。
综上所述,网络中的层索引分别是 ‘0’,‘1’ 和 ‘2’,而只有第一个和第三个层有参数。因此,当运行 print(*[(name, param.shape) for name, param in net.named_parameters()]) 时,你会得到以下输出:
('0.weight', torch.Size([8, 4]))
('0.bias', torch.Size([8]))
('2.weight', torch.Size([1, 8]))
('2.bias', torch.Size([1]))
其中,‘0.weight’ 和 ‘0.bias’ 分别代表第一层的权重和偏置参数,‘2.weight’ 和 ‘2.bias’ 分别代表第三层的权重和偏置参数。第二层没有参数,因此没有被打印出来。
net.state_dict()['2.bias'].data可以访问第二层的偏置参数为tensor([-0.0291])。
torch.nn.init.xavier_normal_() 是在高斯分布中采样进行Xavier初始化,而 torch.nn.init.xavier_uniform_() 是在均匀分布中采样进行Xavier初始化。