【深度学习】日常笔记15
训练集和测试集并不来⾃同⼀个分布。这就是所谓的分布偏移。
真实⻛险是从真实分布中抽取的所有数据的总体损失的预期,然⽽,这个数据总体通常是⽆法获得的。计算真实风险公式如下:
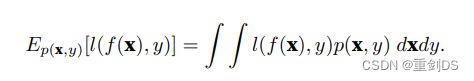
![]() 为概率密度函数
为概率密度函数
经验⻛险是训练数据的平均损失,⽤于近似真实⻛险。在实践中,我们进⾏经验⻛险最⼩化。
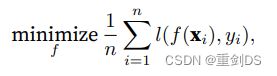 就是我们训练模型时常见的改进模型参数以最小化损失函数l
就是我们训练模型时常见的改进模型参数以最小化损失函数l
p182练习
1. 当我们改变搜索引擎的⾏为时会发⽣什么?⽤⼾可能会做什么?⼴告商呢?
答:当改变搜索引擎的行为时,可能会引发以下影响:
用户行为变化:改变搜索引擎的行为可能会影响用户在搜索过程中的行为和偏好。用户可能会有不同的搜索习惯和期望,根据搜索引擎的新行为进行调整。他们可能会改变搜索的关键词、搜索结果排序的偏好,并可能更频繁点击某些类型的结果。
搜索引擎使用率的变化:搜索引擎的行为改变可能会对其使用率产生影响。如果改变满足用户的需求并提供更准确、有用的搜索结果,用户可能会更多地使用该搜索引擎。相反,如果改变不符合用户的期望或导致搜索结果质量下降,用户可能会转向其他竞争对手搜索引擎。
广告商的策略调整:改变搜索引擎的行为可能会影响广告商的策略和投放方式。广告商可能会根据搜索引擎的行为调整他们的广告投放策略,改变目标关键词、广告排名、广告创意等。如果搜索引擎的改变对广告商不利,他们可能会考虑转向其他广告平台。
竞争格局的改变:搜索引擎行为的改变可能会导致竞争格局的变化。新的搜索引擎行为可能会吸引新的用户群体或引导现有用户流失,从而影响搜索引擎市场份额的变化。竞争对手可能会对这些变化作出相应的调整,以维持或增加其市场份额。
总的来说,当搜索引擎的行为发生改变时,用户行为、搜索引擎使用率、广告商的策略和竞争格局都可能发生变化。因此,在改变搜索引擎行为之前需要仔细评估和分析可能的影响和结果,并根据需求和市场反馈做出相应的调整和改进。
2. 实现⼀个协变量偏移检测器。提⽰:构建⼀个分类器。
答:要实现一个协变量偏移检测器,你可以按照以下步骤构建一个分类器:
①数据准备:收集需要进行协变量偏移检测的数据集,并将其划分为两个部分:源域数据和目标域数据。
②特征选择:选择与协变量偏移相关的特征。这些特征应该在源域和目标域之间有明显的差异,即它们在源域和目标域上的分布不同。
③特征工程:根据所选的特征,对源域和目标域的数据进行预处理和特征工程操作,以确保数据在相同的特征空间上。
④构建分类器:使用源域数据训练分类器模型。你可以选择常见的分类算法,如决策树、逻辑回归、支持向量机或随机森林。这个分类器将作为基准模型。
⑤计算特征重要性:利用训练好的分类器,你可以计算每个特征的重要性得分。这可以帮助你确定哪些特征对区分源域和目标域最有影响力。
⑥偏移检测:使用目标域数据作为输入,利用训练好的分类器进行预测,并观察分类器的输出。如果目标域数据的预测结果与源域数据的预测结果有显著差异,则可以判断存在协变量偏移。
⑦进一步优化:如果发现协变量偏移,你可以尝试进一步调整或优化模型,以提高在目标域上的性能。例如,可以使用领域自适应算法,通过对目标域数据进行领域适应或特征迁移,减小协变量偏移带来的影响。
请注意,协变量偏移检测是一个复杂的问题,在实际应用中可能需要进行更多的数据分析和模型调整。此外,还需要注意数据质量和样本偏差等问题,以避免结果出现误差。
3. 实现协变量偏移纠正。
答:要实现协变量偏移纠正,可以考虑以下方法:
领域自适应方法:领域自适应方法旨在通过学习源域和目标域之间的特征映射来减小协变量偏移造成的影响。常用的领域自适应方法包括最大均值差异(Maximum Mean Discrepancy, MMD)、领域对抗神经网络(Domain Adversarial Neural Network, DANN)等。这些方法通过使源域和目标域的特征分布相似化,从而减小其间的协变量偏移。
校正样本权重:通过调整目标域样本的权重,使其在训练中获得更大的关注度,以减小协变量偏移的影响。可以使用重加权(reweighting)方法,即通过为目标域中的样本赋予更高的权重来平衡源域和目标域之间的偏差。这可以让模型更加关注目标域,并更好地适应目标域的数据分布。
领域适应模型迁移:利用源域上训练好的模型参数和知识,迁移到目标域上,以减小协变量偏移对模型性能的影响。常见的方法包括迁移学习和预训练模型的迁移。这些方法通过利用源域数据的知识和模型迁移到目标域,以帮助模型更好地适应目标域数据。
样本生成和增强:对目标域的数据进行样本生成和数据增强操作,以增加目标域的样本多样性和丰富性,减小协变量偏移的影响。可以利用生成对抗网络(Generative Adversarial Networks, GANs)或数据增强技术生成合成的目标域样本,并将其用于训练模型。
这些方法可以单独或组合使用,具体的选择取决于数据集和实际需求。在实施协变量偏移纠正前,建议首先对数据进行详细的分析和了解协变量偏移的特点,并进行预实验和模型评估来决定合适的方法和策略。
4. 除了分布偏移,还有什么会影响经验⻛险接近真实⻛险的程度?
答:
特征选择:特征选择的不当可能导致模型对真实世界的不良适应。如果在训练数据中选择的特征在真实数据中没有重要性或相关性,模型在真实数据上的性能可能会下降。
模型选择和复杂度:选择不合适的模型或模型复杂度可能导致模型在真实世界中的泛化能力下降。如果模型过于简单而无法捕捉数据中的复杂关系,或者模型过于复杂而发生过拟合,都可能影响模型在真实数据上的表现。
数据不平衡:当训练数据中某一类别的样本数量明显少于其他类别时,模型可能倾向于更多地关注数量较多的类别,从而导致在真实数据上的性能下降。数据不平衡可能使模型对少数类别的识别或分类能力受限。