PAC与样本复杂度
这篇文章主要总结 PAC 学习框架以及样本复杂度相关的东西,大致来说就是:要保证以概率 1 − δ 1-\delta 1−δ 使得 generalized error 小于 ϵ \epsilon ϵ 需要多大的样本复杂度,以及时间复杂度才是好的。
问题及约定
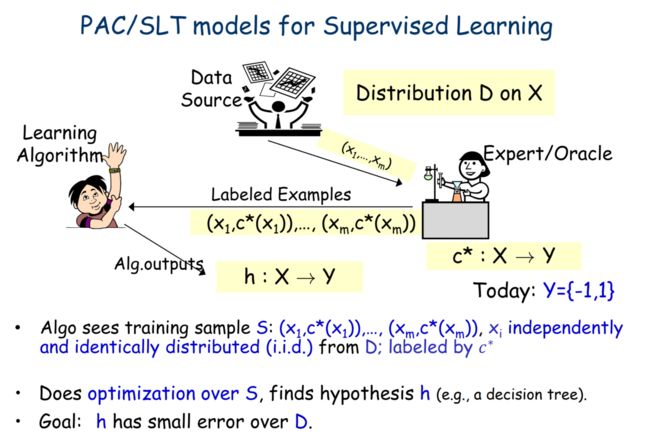
符号约定

两个 error 符号

就是我们常说的 train error 与 true error
接下来是定义我们要研究的问题

简单的来说就是 依赖于 m , H , ϵ , δ m,H,\epsilon,\delta m,H,ϵ,δ 这四个东西,我们找到一个 样本复杂度以及计算复杂度的界.或者说找到他们的一些关系
定义
consistent hypothesis:
c o n s i s t e n t ( h , S ) ∣ = h ( x ) = c ( x ) , ∀ ( x , c ( x ) ) ∈ S consistent(h,S) |= h(x)=c(x),\forall (x,c(x))\in S consistent(h,S)∣=h(x)=c(x),∀(x,c(x))∈S
一个 假设称为是 consistent 的,if and only if, ∀ ( x , c ( x ) ) ∈ S \forall (x,c(x))\in S ∀(x,c(x))∈S 都有, h ( x ) = c ( x ) h(x)=c(x) h(x)=c(x)
Version Space:
V S H , S : { h ∈ H ∣ c o n s i s t e n t ( h , S ) } VS_{H,S}:\{h \in H|consistent(h,S)\} VSH,S:{h∈H∣consistent(h,S)}
ϵ − e x h a u s t e d \epsilon-exhausted ϵ−exhausted
V S H , S VS_{H,S} VSH,S 称为 ϵ − e x h a u s t e d \epsilon-exhausted ϵ−exhausted,当且仅当,
∀ h ∈ H , e r r o r D ( h ) < ϵ \forall h\in H,error_D(h)<\epsilon ∀h∈H,errorD(h)<ϵ
throme

这个定理的证明会在文末给出,接下来的核心就在于理解这个定理
理解
这个定理的前提:
- H f i n i t e H finite Hfinite
- c ∈ H c\in H c∈H
注意这个定理说的是 not,将这个定理翻译一下就是
Pr ( ∃ h ∈ H , ( e r r o r S ( h ) = 0 ) & ( e r r o r D ( h ) > ϵ ) ) < ∣ H ∣ exp − ϵ m \Pr(\exists h \in H,(error_S(h)=0)\And(error_D(h)>\epsilon))<|H|\exp^{-\epsilon m} Pr(∃h∈H,(errorS(h)=0)&(errorD(h)>ϵ))<∣H∣exp−ϵm
也就是说 如果 e r r o r S ( h ) = 0 error_S(h)=0 errorS(h)=0, 那么 e r r o r D ( h ) < ϵ error_D(h)<\epsilon errorD(h)<ϵ 的概率至少是 ∣ H ∣ exp − ϵ m |H|\exp^{-\epsilon m} ∣H∣exp−ϵm
如果我们想要让 ∣ H ∣ exp − ϵ m < δ |H|\exp^{-\epsilon m} < \delta ∣H∣exp−ϵm<δ, 那么我们需要
m > ϵ − 1 ( log ( ∣ H ∣ ) + log ( δ − 1 ) ) m>\epsilon^{-1}(\log(|H|)+\log(\delta^{-1})) m>ϵ−1(log(∣H∣)+log(δ−1)),这么多变量
if e r r o r S ( h ) = 0 error_S(h)=0 errorS(h)=0 那么 至少我们有 1 − δ 1-\delta 1−δ 的概率保证
e r r o r D ( h ) ≤ m − 1 ( log ( ∣ H ∣ ) + log ( δ − 1 ) ) error_D(h)\le m^{-1}(\log(|H|)+\log(\delta^{-1})) errorD(h)≤m−1(log(∣H∣)+log(δ−1))
PAC learnable

简单的说,一个算法是 PAC(Probability Approximation Correct) 可学习的,要满足,时间复杂度和样本复杂度都是多项式的
agnostic learning
上面都说的是 c ∈ H c\in H c∈H ,那如果, c ∉ H c\notin H c∈/H 呢?
根据 Hoeffding 不等式(see wiki)
fix a h h h,
Pr ( e r r o r D ( h ) − e r r o r S ( h ) > ϵ ) ≤ 2 exp − 2 m ϵ 2 \Pr(error_D(h)-error_S(h)>\epsilon)\le 2\exp^{-2m\epsilon^2} Pr(errorD(h)−errorS(h)>ϵ)≤2exp−2mϵ2
修改前面的定理,
Pr ( ∃ h ∈ H , e r r o r D ( h ) − e r r o r S ( h ) > ϵ ) < ∣ H ∣ 2 exp − 2 m ϵ 2 \Pr(\exists h\in H,error_D(h)-error_S(h)>\epsilon)<|H|2\exp^{-2m\epsilon^2} Pr(∃h∈H,errorD(h)−errorS(h)>ϵ)<∣H∣2exp−2mϵ2
因此在概率为 δ \delta δ 的情况下,需要的样本 bound
就可以很容易求解了
erm
最后不加证明的给出

即 如果我们知道 e r r S ( h ) err_S(h) errS(h) 那么 e r r o r D ( h ) error_D(h) errorD(h) 的bound 在哪里?
所有的证明和材料,都可见reference
reference
- 10716 f16 Eric Xing
- 10715 f18 Maria-Florina Balcan
版权声明
本作品为作者原创文章,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议
作者: taotao
转载请保留此版权声明,并注明出处