Spark Structed Streaming 入门详解
一、概述
Structed Streaming 是一个可扩展和容错能力构建与Spark Sql引擎上的流处理引擎。你可以像采用批次处理静态数据一样处理流式数据。随着流数据的不断流入,Sparksql引擎会增量的连续不断的处理并且更新结果。可以使用DataSet/DataFrame的API进行 streaming aggregations, event-time windows, stream-to-batch joins等等。计算的执行也是基于优化后的sparksql引擎。通过checkpointing and Write Ahead Logs该系统可以保证点对点,一次处理,容错担保。
默认情况下,Structed Streaming 查询通过使用micro-batch 处理引擎来处理,spark 2.3之后引入了一个新的被称作为continuous-processing 的低延迟处理模式,延迟由100millseconds 降到1 millseconds。
二、应用举例
如下代码实现监听TCP socket,进行事实的单词统计:
1.导入必要的包,并创建一个本地的SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._
2.接下来创建一个streaming DataFrame 来表示收到的来时监听的本地端口(localhose:9999)的文本数据,并且通过对DataFrame的转化进行单词统计
// Create DataFrame representing the stream of input lines from connection to localhost:9999
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
//lines.as[String]是为了将DataFrame转化为DataSet,这样便于再其上执行flatMap操作将每一个根据空格分割成多个单词
// Generate running word count
val wordCounts = words.groupBy("value").count()
lines 这个DataFrame表示一个包含流式文本数据的无界表
这个表包含一个String类型 values列
流式文本的每一行变成表中的一行
3.定义输出并开始流计算
// Start running the query that prints the running counts to the console
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
4.通过netcat 向指定舰艇端口发送文本数据
在本地执行 nc -lk 9999
5.将1、2、3中的代码编译打包或者在idea中执行,或者可以直接在spark目录下执行
./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
6.在4的窗口式随意输入任何内容,词之间空格分割,回撤换行,如下:
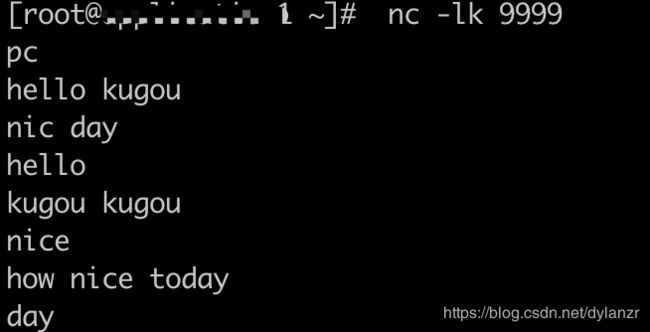
流式计算得到的结果如下:
| 
三、编程模型
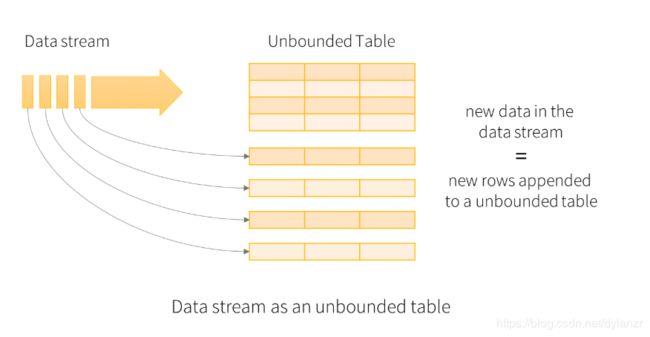
Structed Streaming 的核心思想就是将数据流看作是一个持续追加的数据表。
将流式数据看作一个输入表,流中每到来一条数据可以看作是追加到数据表中的一行数据:
对输入的一次查询会生成一个结果表,在每一个触发间隔内追加到输入表的数据最终都会更新到结果表:
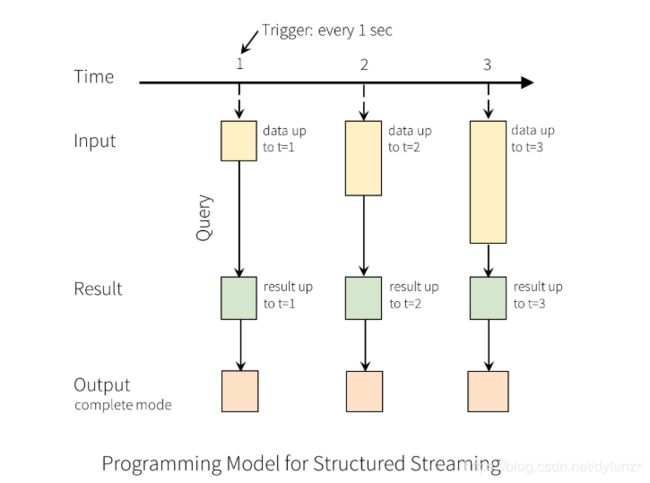
OutPut定义为保存在外部存储的结果,支持一下几种模式:
- Complete Mode-整个更新结果都会被写到外部存储上,由存储连接者决定如何处理对真个表的写处理
- Append Mode-只有在最新一次触发中新追加到结果表的行才会被写入到外部存储。仅应用于存在于结果表中的数据不改变的查询。
- Update Mode-只有在最后一次触发中被更改的行才会被写入大外部存储
四、输入输出支持
1)Sources:输入,Scala/Java/Python 可以通过SparkSession.readStream()来创建DataStreamReader,以下是几种内置的Sources:
- File sources:监听某个目录,每个触发读入新增文件
- Kafka sources:消费kafka队列
- Socket source(用于测试)
- Rate source(用于测试)
2)Sinks:输出
- File sink:将结果输出到指定目录
- Kafka sink:将结果输出到kafka的一个或多个topics
- Foreach sink:对输出中的每一条记录进行任意操作
- Console sink(用于调试):将结果输出到console/stdout
- memory sink(用于调试):输出结果以内存表的形式保存在内存中
link:http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#handling-late-data-and-watermarking