还在用ps抠图抠瞎眼?机器学习通用背景去除产品诞生记

大数据文摘作品
作者:Gidi Shperber
编译:糖竹子,康璐,赖小娟,Aileen
这篇文章图描述了我们在greenScreen.AI的研究工作。欢迎大家留言评论!
介绍
在过去几年机器学习潮流下,我一直想要搭建实用的机器学习产品。
几个月前,在Fast.AI上学习了很棒的深度学习课程后,这一想法更清楚了,我的机会来了:深度学习技术的进步让许多以前不可能完成的事变得可能,而且新工具被开发出来,让部署过程变得前所未有的简单。
在刚才提到的课程中,我认识了Alon Burg,一位资深网络开发者,为了搭建实体产品这一共同目标我们成为了搭档。我们一起为自己设定了以下目标:
1.增进我们的深度学习技巧
2.增进我们人工智能产品的部署技巧
3.打造满足市场需求的有用产品
4.产品要做的有趣(让自己觉得有趣,也要让用户用的有趣)
5.分享我们的经验
基于上面的考虑,我们有以下的想法:
1.产品是还未被完成过的事(或者未被正确完成的事)
2.产品不会过于困难计划和完成-我们计划时长是2-3个月的时间,每周花一个工作日时间
3.产品要有一个简单美观的用户界面-我们希望做一款人们可以使用的产品而不仅仅是为了论证科学道理
4.产品的训练数据要容易获取-正如任何一名机器学习专业者了解的,有时候数据比算法更重要
5.将使用前沿的深度学习技巧(这些技巧目前还未被Google,Amazon和其他云平台商品化),但又不会过于崭新(这样我们能够在网上找到类似的案例)
6.产品有形成生产品的潜力
我们最初的想法是做一些与医疗有关的项目,因为这一领域非常接近我们的理念,并且我们认为(且一直认为)深度学习在医疗领域仍有累累硕果唾手可得。然而,我们意识到将在数据收集和法律法规上遇见问题,这与我们想要保持项目简单的目标相违背。所以我们第二选择是做一款背景去除产品。
背景去除是一项如果你用了某种标记和边缘检测功能,手工或者半手工(使用Photoshop甚至PowerPoint这类工具)就能完成的非常简单的任务,这里有个例子。然而,全自动的背景去除是相当有难度的任务,而且据我们所知,尽管有人尝试,但仍然没有哪个产品能够满足这个要求。
我们要去除的是什么样的背景呢?这个问题变得非常重要,因为模型在物体、角度等问题上越具体,模型的分割质量就会越高。当我们开始时,我们想了一个广泛的目标:一款通用背景去除产品,能够自动识别各种图片类型中的前景和后景。但在训练完第一个模型后,我们意识到把精力放在某一套特定的图片上会更好。因此,我们决定专注于自拍照和人像照。

自拍图片具有凸显和聚焦的前景(一个或多个人),保证物体(脸和上半身)与背景能够很好分离,同时几乎都是一样的角度而且总是同样的物品(人)。
带着这些假设,我们开始了一系列的调查研究、代码实现和大量的训练,来创造鼠标一点就能轻松去除背景的服务。
我们的主要工作是训练模型,但也不能低估正确部署的重要性。好的分割模型仍然不能像分类模型一样简洁(例如SqueezeNet)而且我们积极的检查了服务器和浏览器部署选项。
如果你想阅读更多我们产品部署过程的细节,欢迎从服务端和客户端查看我们的公告。
如果你想阅读模型和训练过程内容,请继续。
语义分割
当思索深度学习和计算机视觉任务有哪些和我们目标相似时,我们很容易发现技术上最优选择是语义分割。
其他如通过深度检测分离的策略也存在,但看起来仍不够成熟以满足我们的目的。
语义分割是众所周知的三大计算机视觉任务之一,其余两个是分类任务和目标检测。从把图片每个像素归为某一类别的意义上说,分割任务实际是分类任务的一种。与图片分类或图片侦测不同,分割模型真正展现了对图片的理解,不仅能够辨别出“图像里有一只猫”还能在像素层面指出这只猫的位置和属性。
那么分割是怎样完成的呢?为了更好的理解,我们必须调查相关领域的早期研究。
最初的想法是采用如VGG和Alexnet的早期分类网络。VGG在2014年是当时最先进的图片分类模型,由于其简单直接的架构至今仍非常有用。在检查VGG初始网络层时,也许会注意到对需要分类的物品设置了很多激活,而且网络层越深激活更强,然而他们本质上非常粗糙因为只是重复池化。有了这些认识,我们假定分类训练经过微调后也可用于寻找或分割物体。
语义分割的早期结论是随分类算法出现的。在这篇文章中,你会看到使用VGG得到的粗分割结果。

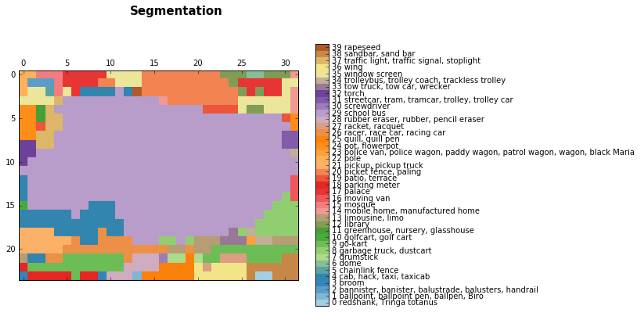
车图分割,淡紫色(29)为校车区域
双线性上采样后:
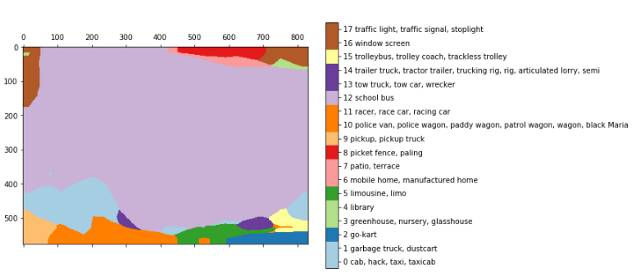
这些结果仅来自于将全连接层转换(或保留)至他们原有的形状,保留他们的空间特征 ,得到一个完全卷积网络。在上述例子中,我们为VGG输入一张768*1024的图片,并得到了24*32*1000的层。24*32是图片池化的形式(步长为32),1000是网络图像类别的数量,我们将从中得到分割结果。
为了使预测结果更平滑,研究员们使用了简单的双线性上采样层。
在FCN的论文中,研究员们改进了上述想法。为了预测结果更有效,他们依据上采样率把一些层逐渐连接起来,命名为FCN-32,FCN-16和FCN-8.
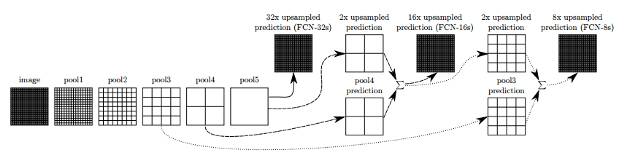
在层与层之间增加跳跃连接能让预测器从原图得到更好的细节编译。进一步的训练对结果的改进更多。
这一技术本身并没有想象中糟糕,并且证明了深度学习的语义分割确实有改进空间。

图4.以熔断来自不同步幅的层级信息来精炼全卷积网络达到提高分割细节的目的。前三张图片展示我们32、16、和8像素步幅网(见图3)
来自论文的FCN结论:
全卷积网络(FCN)的分割的概念与传统不同,研究员为这此尝试了不同架构。但核心思想依然保持相似:使用已知的架构,上采样,和网络间的跳跃层。这些依然在新模型中常见。
你可以在这些优秀文章中了解到相关领域的前沿内容:
http://blog.qure.ai/notes/semantic-segmentation-deep-learning-review
https://medium.com/m/global-identity?redirectUrl=https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
https://meetshah1995.github.io/semantic-segmentation/deep-learning/pytorch/visdom/2017/06/01/semantic-segmentation-over-the-years.html
你也会发现大多数分割方法保持了encoder-decoder的架构。
回归项目
在一番研究后,我们选定了三个可用模型:FCN,Unet 和Tiramisu ,Tiramisu是深度“编码-解码”框架。我们也想过使用mask_RCNN,但实施它似乎超出了项目范围。
FCN因为结果不尽如人意首先被我们舍弃,但我们提到的另外两个模型展现了还不错的结果:在CamVid数据集上的tiramisu和在Unet的主要优势是简洁度和速度。从实现的角度,Unet的实现非常简单(我们使用了Keras)而Tiramisu也易于实现。为了快速上手,我们使用了Jeremy Howard深度学习课程中最后一课的Tiramisu实现代码。
有了这两个模型,我们接下来开始在一些数据集上训练模型。必须提到,在第一次尝试Tiramisu后,我们认为Tiramisu还有很大潜在进步空间,因为它有抓取图片尖锐边缘的能力。从另一方面,Unet看起来不够优秀,而且结果似乎存在一些斑点。

数据:
在大方向上确定了模型后,我们开始寻找合适的训练数据集。分割数据不像分类或侦测数据那样常见。另外,手动打标签也并非实际可行。最常见的分割数据集是COCO数据集,包括约90种类别的8万张图片,VOC pascal数据集有20种类别的1.1万张图片,还有最新的ADE20K数据集。
我们选择使用COCO数据集,因为它包含更多的“人”像图片,正是我们项目的兴趣所在。
考虑产品的任务,我们在衡量是否要用和任务目标极度相关的图片还是应该选择广泛一些的数据集。一方面,使用包含更多图片和分类的广泛的数据集能让模型将来处理更多场景和挑战。另一方面,通过通宵训练模块允许我们处理15万张图片。如果为模型输入整个COCO数据集,我们的模型对每张图片将(平均)处理两次,因此缩减一些图片对模型训练会非常有益。另外,这也会让模型更加符合我们的目标。
另一件值得一提的事是,Tiramisu模型最初是在CamVid数据集上训练的,数据有些瑕疵,但最重要它的图片非常单一。所有图片都是通过汽车拍摄的街景。可以轻松理解,从这样的数据集学习(尽管包含一些人像)对我们的任务没有好处,所以在短暂的尝试后,我们放弃了它。

来自CamVid数据集图片
COCO数据集有非常简单的API,通过API让我们能明确知道每张图片内包含的内容具体是什么(通过预先设定的90种分类)
经过几次实验后,我们决定削减数据集:首先我们筛选了仅含人物的图片,留下4万张。然后我们丢弃所有包含很多人像的图片,仅留下包含1至2人的图片,因为才是产品的目标图。最终我们留下了图片只有20%-70%部分被标记为人像,去除了背景中有非常小的人像图片或者有些奇怪内容的图片(可惜并非去除了全部)。最终的数据集包含了1.1万张图片,我们认为在这个阶段够用了。

左:符合标准的图 中:角色太多 右:目标太小
Tiramisu 模型
就像说过的,我们在Jeremy Howard的课程上了解了Tiramisu模型。尽管它的全称是“100层Tiramisu”,暗示它非常庞大,实际上它却“经济实惠”,只需要9M的参数空间。相较而言,VGG16需要130M空间。
Tiramisu是基于极深网络的,这个模型最近被用来做图像分类,它的所有隐含层都互相连接。此外,Tiramisu在上采样层增加了跃层链接,例如Unet模型。
回想一下,这个构造和FCN所呈现的相同的:使用分类构造,上采样和增加跃层链接来获得精细结果。
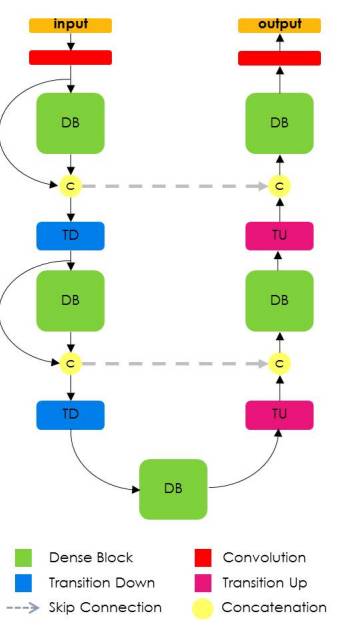
Tiramisu的基本构架
极深网络可以看成是Resnet模型的自然演进,但是与隔层就“完全失忆”的情况相比,极深网络能够牢记模型中所有的层。这些链接被称作“高速路”。这样过滤器就增加了,也就提高了成长率。Tiramisu的成长率是16,因此我们每层都增加16个过滤器,直到有1072个过滤器。你可能期待会有1600个过滤器,因为这是100层的Tiramisu模型,但是其实上采样层会丢弃一些过滤器。
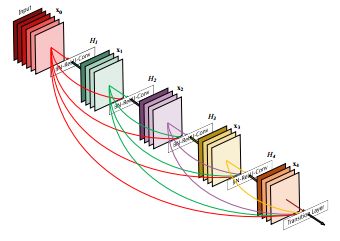
极深网络模型示意图 - 早期的过滤器一直都在堆叠在模型中
训练:
我们使用在之前文章中提到的方法训练模型:学习率为1e-3且有小额衰减的标准交叉熵损失函数法。我把我们11K的图像分成70%的训练集,20%的验证集和10%的测试集。下面的所有图像都是测试集中的数据。
为了保证我们的训练流程和之前的一样,我们把取样大小设定在500个图像。这让我们可以阶段化的存储结果中的每个改进,因为我们用了更多的数据(文中使用的CamVid数据集包括少于1000张图片)。
另外,尽管论文中涉及了12类,但是我们只训练了2分类模型:背景和人像。开始时我们试着训练coco中设定的种类,但是我们发现这并没有多大帮助。
数据问题:
数据集存在的一些问题限制了我们的表现:
·动物-我们的模型有时需要分割开动物。这让我们的IoU(交并比)变得很低。把动物在任务中都加入同一类,很可能得到糟糕的结果。
·肢体部位-由于我们的数据是自动分类的,我们无法区分划分为人像的图片是一整个人还是只有一部分,比如只有手或脚。这些图片不在我们的研究范围里,但是仍然时不时的出现。
动物、肢体部位、手持物品
·手持物体-数据集中很多图像是和体育运动有关的。棒球棒、羽毛球拍和滑雪板到处都是。我们的模型在这些部分感到困惑。就像在动物的案例中一样,把他们当做主要类别的一部分,或者单独的类别能够帮助改进模型效果。
手持物体的运动图像
·粗糙的真实数据标注-coco数据集不是一个像素一个像素标注的,而是使用多边形。应对大部分情况已经足够了,但是这导致真实数据标注非常粗糙,这也阻碍了模型对细节的学习。
图像和非常粗糙的真实数据标注



结果:
我们的结果非常令人满意,但是并不完美:我们的测试集IoU达到了84.6,现在最高水平是85。这个数字是有一定欺骗性的,因为随着数据集和分类的变化它会产生波动。有些种类非常容易区分,比如房子、道路,大部分模型在区分这些类时很容易达到90的准确度。另外的一些类很难区分,比如树和人,模型在这些类别上只能达到60左右的精度。为了评估这种困难,我们让网络专注于一个种类,并且只用几种图片。虽然我们希望我们的模型是能够实际应用的,但是我们的工作仍然只是研究性的。不过我们觉得现在是时候停下来讨论一下我们的结论了,因为模型已经能在50%的模型中得出好的结果。
下面是一些比较好的例子,你可以感受一下它的应用潜力:



图像,真实数据标记,我们的结果(取自测试集)
调试和日志:
训练神经网络的一个非常重要的部分就是调试。当开始我们的工作时,非常希望马上就着手正题,获取数据建立网络,开始训练,然后看看结论是什么。但是,我们发现记录每个步骤是非常重要的,并且必要时可以自己制作工具来检验每一步的结果。
下面是一些常见的问题,和我们的应对方法:
1.早期问题-模型不能正常训练。可能由于一些遗留的问题,或者一些预处理错误,比如忘记标准化。总之,简单的可视化非常有帮助。这里有一篇很有帮助的文章。(https://blog.slavv.com/37-reasons-why-your-neural-network-is-not-working-4020854bd607)
2.让网络自行调试-在确保这里没有重大的问题,训练就开始了,使用我们之前定义好的损失函数和矩阵。在分区时,最重要的指标是IoU(?intersect over union)-交并比。在开始使用IoU(并非交叉熵)当做我们的模型主要衡量手段前需要好几个步骤。另外一个有用做法是在每一次迭代的时候都展示一些我们的预测结果。在keras中IoU并不是一个标准的矩阵/损失,但是你可以很容易的网上找到它,比如这里(https://github.com/udacity/self-driving-car/blob/master/vehicle-detection/u-net/README.md),我们也用这个来画出每次迭代的损失和预测结果。
3.机器学习版本控制-当训练一个模型时,有很多参数,其中有一些是有欺骗性的。我不得不承认我们还没有发现完美的方法,除了狂热的记录我们的配置参宿(并且使用keras自动保存最佳模型,详见下方)
4.调试工具-上面的工作让我们可以在每一步检测我们的工作,但是并不是无缝隙的。因此,最重要的一步是把上面的工作都结合起来,并且建立一个jupyter笔记本,让我们能无缝的下载每个模型和每个图像,并且快速检验它的结果。这样我们可以很容易的看出模型的不同,陷阱和其他问题。
下面是通过调整参数和额外的训练,而使模型改进的例子。
为了存储最佳的IoU模型,我们使用了下面语句:(keras提供了非常好的回溯功能,让事情变得更加容易)
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]
除了常见的调试可能的代码错误,我们发现模型的错误是可以预见的,比如把身体的部分给砍掉了,大区块缺角,不必要的延伸了身体部分,光线差,质量差,和很多细节。一些这些问题通过加入其它数据集的图片解决了。为了在下个版本里面改进结果,我们会使用放大方法,尤其是在“高难度”的图片上。
我们已经提到过数据集的问题。下面我们来看更多模型中遇到的困难:
1.衣服-非常暗或者非常亮的衣服会被当做背景
2.缺失-一个不错的结果上,会有一些缺失
衣服和缺失
3.光线-较差的光线和模糊在图片中是非常常见的,但是在coco数据集不多。因此,除了一般模型遇到的问题,我们甚至都没有做任何准备来处理这些高难度图片。这个问题可以通过训练更多数据来解决,图片放大也是一个好选择。另外,最好不要在晚上使用我们的app :)
光照不足的例子


更进一步发展的选项
其他训练:
我们的结果是在经过了300次迭代之后得到的。经过这个阶段,模型开始出现过拟合。我们得到的结果和发布的非常接近,所有我们没有得到应用数据放大的机会。
之前的模型中我们把图片变成224*224。进一步用更多更大的图片来训练模型(coco图片的原始大小是600*1000)也有可能会改进模型结果。
CRF和其他改进:
在一些阶段,我们看见我们的结果在边缘的地方有一些噪声。CRF模型可能会改善这个现象。在这个博文中(http://warmspringwinds.github.io/tensorflow/tf-slim/2016/12/18/image-segmentation-with-tensorflow-using-cnns-and-conditional-random-fields/),但是,这对我们的模型不是很有用,可能因为它最有帮助的地方是当结果比较粗糙的时候。
抠图:
在我们现在的结果中,分区依然不是很完美。头发,精细的服饰,树枝和其他精细的物品都不能被完美的区分出来,甚至其原因可能是真实数据分区压根就没包含这些细节。区分这些精细的部分的工作叫做抠图,这是一个不同的挑战。这里是一个精细抠图的例子,它在今年早些时候发表在NVIDIA的参考中(https://news.developer.nvidia.com/ai-software-automatically-removes-the-background-from-images/)。
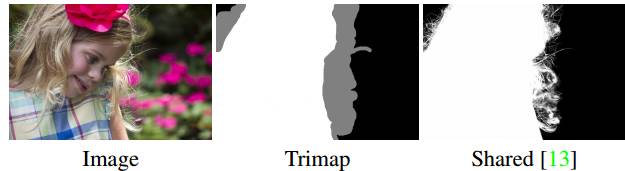
抠图例子-输入包括三元图
抠图任务和其他的图像相关任务是不同的,因为不只包括一个图像,而且包括一个三元图-图像边缘的轮廓,这样就成了一个半监督问题。
我们稍微尝试了一下抠图,把我们的分区用作三元图,不论如何我们没有得到显著的结论。
另外一个问题是缺乏用来训练的合适的数据集。
总结
就像在开始时提到的,我们的目标是建立一个显著的深度学习产品。你可以在Alon的帖子(https://medium.com/@burgalon)中看到,部署变得越来越简单和快速。另一方面,训练模型是有欺骗性的,训练,特别是整晚的训练需要详细的计划,调试和记录结果。
在调研和尝试新事物之间的平衡也是很难保持的,以及平凡的训练和改进。因为我们使用深度学习,所以我们总觉得最好的模型,或者我们需要的最确切的模型就在触手可及的地方,并且下一次google搜索或者文章都有可能让我们找到它。但是实际上,我们的真正改进,更多的来源于简单的提炼我们原有的模型,并且就像上面说的,我们依然觉得它可以继续提炼。
作为总结,做这个工作我们有很多乐趣,在几个月之前我们会觉得这些像是科幻电影中的内容。我们很高兴和大家探讨或者回答任何问题,期待能在我们的网页上见到你们:)
大数据文摘x稀牛学院
AI精品钜惠课程
人工智能的数据基础
金牌数学讲师
直播互动学习
助教全程辅导
以科研+工程的独特视角,带你搞定人工智能中所需的数学理论,
入门与进阶AI/DL领域的推荐课程!

![]()
志愿者介绍
回复“志愿者”加入我们




往期精彩文章
点击图片阅读
确定不收藏?十张机器学习和深度学习工程师必备速查表!


