Python爬虫入门
Python爬虫介绍
聚焦爬虫和通用爬虫
爬虫根据其使用场景分为通用爬虫和聚焦爬虫,两者区别并不是很大,他们获取网页信息的方式是相同的。但通用爬虫收集网页的全部信息,而聚焦爬虫则只获取和指定内容相关的网页信息,即需要信息的筛选
爬虫的工作原理
通用爬虫是百度谷歌这样提供搜索服务的公司使用的,他们需要将网上所有的网页信息通过爬虫全部抓取并存储起来,并对这些信息进行分析处理,用户进行搜索时就把有相关信息的网页展示出来。通用爬虫需要很大的硬件方面的支持,才能将互联网上的信息全部爬取,而聚焦爬虫只获取和目标信息相关的内容,所以比较简便,使用也更广泛
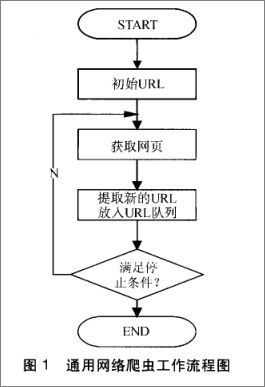
通用爬虫的工作过程如下:
第一步:抓取网页
首先选取一部分的种子URL,将这些URL放入待抓取URL队列
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环….
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬取
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。比如:提取文字,中文分词,索引处理,链接关系计算等,除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序
第四步:提供检索服务
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户
Python爬虫的基本库—–urllib2库
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 在Python中有很多库可以用来抓取网页,其中urllib2库比较经典和常用的一个爬虫库。urllib2在python3中更名为urllib.request
urllib2库的简单使用
我用的Python3,所以调用urllib2库时用urllib.request
一下是最简单的一个Python爬虫程序,爬取百度首页的信息
该例子中只是用了一个方法urlopen()方法,该方法是urllib2爬取网页时最核心的方法
# 导入urllib.request 库
import urllib.request
# 向指定的url发送请求,并返回服务器响应的类文件对象
response = urllib.request.urlopen("http://www.baidu.com")
# 类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read()
# 打印网页内容
print (html)在控制台输入命令Python spider1.py,爬虫抓取了百度首页的网页内容,并打印了下来

下图是使用浏览器打开百度首页网页源码,可以发现和爬虫爬取的内容完全相同
添加请求信息
request对象的使用
上面的例子中,只用了一个urlopen()方法,但是在实际生产过程中,这是远远不够的,在根据URL访问网站时,需要添加一些请求信息,这样才不会被反爬虫机制阻碍爬虫的正常工作
添加请求信息通过Request对象完成,如下,将URL信息封装到request对象中,并把request对象作为urlopen()方法的参数
import urllib.request
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://www.baidu.com")
# 使用request对象作为urlopen方法的参数
response = urllib.request.urlopen(request)
html = response.read()
print (html)通过request对象添加User-Agent
上面的程序中,只向request对象中添加了目标网站的URL地址,下面的程序向request中多添加了一个User-Agent
import urllib.request
# 网站的URL地址
url = "http://www.itcast.cn"
# "User-Agent"信息
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
# 将URL和User-Agent添加到request对象中
request = urllib.request.Request(url, headers = header)
response = urllib.request.urlopen(request)
html = response.read()
print (html)通过request对象添加请求头
再向request中添加一个请求头
import urllib.request
url = "http://www.itcast.cn"
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
request = urllib.request.Request(url, headers = header)
# 使用add_header()方法向request中添加请求头信息
request.add_header("Connection", "keep-alive")
response = urllib.request.urlopen(request)
html = response.read()
print (html)