Python爬虫基础-01-带有请求参数的爬虫
在上一篇文章Python爬虫入门中,Python爬虫程序爬取了指定网页的信息,爬虫发出的请求是一个固定的URL和部分请求信息,并没有请求参数,但是爬虫工作过程中发出的请求一般都需要加上请求参数,以完成对指定内容的爬取
HTTP请求分为POST请求和GET请求,在Python爬虫中,这两种请求因其结构不同,所以添加请求参数的方式也不同,下面将分别介绍使用POST请求和GET请求的Python爬虫
GET请求
使用GET请求的Python爬虫比较简单,由于GET请求的请求参数包含在URL地址中,所以只需要先确定请求参数,然后将请求参数拼接到URL中即可,即 URL + 请求参数(字符串拼接)
使用GET请求的Python爬虫案例
首先,一个使用GET请求访问网页的例子。如下图所示,使用百度,以“爬虫”为关键字进行查询,可以看到,地址栏的URL为:https://www.baidu.com/s?word=爬虫。我们可以使用这个URL地址利用爬虫爬取该网页

我们写一个可以使用和上面一样的GET请求的Python爬虫程序,需要用到urlllib2包
# coding=utf-8
import urllib2
url = "http://www.baidu.com/s"
word = {"wd":"爬虫"}
# url首个分隔符是 ?
newurl = url + "?" + word
# 添加User-Agent,完善请求信息
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
request = urllib2.Request(newurl, headers=headers)
response = urllib2.urlopen(request)
print response.read()程序写好后,直接运行会报错,这是因为请求参数需要进行编码转换,在使用浏览器访问时,这个转换是浏览器自动完成的。但是在Python爬虫程序中,这一步就需要程序员自己来完成了。编码转换需要使用urllib包
# coding=utf-8
import urllib #负责url编码处理
import urllib2
url = "http://www.baidu.com/s"
word = {"wd":"爬虫"}
# 将请求参数转换成url编码格式(字符串)
word = urllib.urlencode(word)
# url首个分隔符是 ?
newurl = url + "?" + word
# 添加User-Agent,完善请求信息
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
request = urllib2.Request(newurl, headers=headers)
response = urllib2.urlopen(request)
print response.read()运行程序,控制台打印的信息如下,爬取成功
使用GET请求的Python爬虫的应用
在使用Python爬虫爬取一个有分页的网站时,各个页面的URL非常接近,唯一的不同就是页码数字不同,这是使用GET请求能非常简单方便的将该网站的各个页面爬取下来
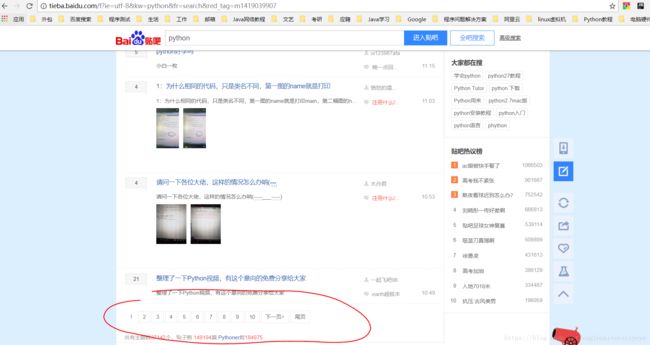
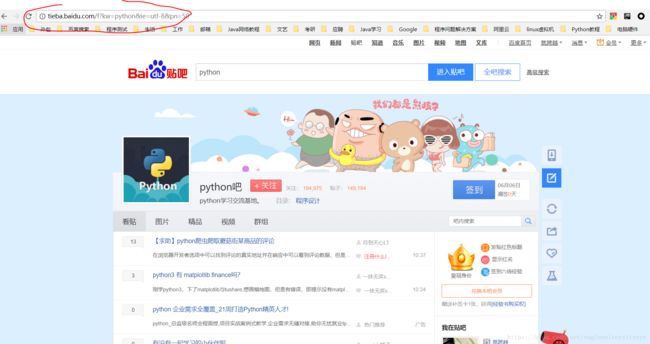
如下图,Python吧的第一页的URL地址:http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=0
第二页的URL地址:http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50
第三页的URL地址:http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=100
可以看出URL中只有pn参数在变化,它控制着到底访问该吧的那一页,发现了这个规律后,就可以通过一个循环,切换URL地址中的参数从而将整个贴吧中所有页面的内容都爬取下来
# coding=utf-8
import urllib
import urllib2
url = "http://tieba.baidu.com/f?kw=python&ie=utf-8&pn="
i = 0
while i<1000:
i = i +50
newurl = url + i
# 添加User-Agent,完善请求信息
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
request = urllib2.Request(newurl, headers=headers)
response = urllib2.urlopen(request)
print response.read()
POST请求
GET请求的请求参数是直接包含在URL中了,而POST请求的请求参数则不会出现在URL中,而是要经过单独的封装处理。所以,如果爬虫需要使用POST请求,就不能直接通过 URL + 请求参数 字符串拼接这种简单粗暴的方式了
使用POST请求的Python爬虫案例
访问百度贴吧的请求是GET类型的,而访问有道翻译的请求则是POST类型的。如下图所示,输入我在学习,点击翻译,地址栏中的URL没有变化,说明点击翻译后发送的请求是POST类型的,即无法再URL中看到参数

下面就是使用POST请求的Python爬虫程序,通过一个formdata 字典作为参数,当调用urllib2.Request类时,使用三个参数,即urllib2.Request(url, data = data, headers = headers),Python爬虫发送POST请求,使用两个参数urllib2.Request(newurl, headers=headers),Python爬虫发送GET请求
# coding=utf-8
import urllib
import urllib2
# POST请求的目标URL
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
# 添加User-Agent,完善请求信息
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
data = urllib.urlencode(formdata)
request = urllib2.Request(url, data = data, headers = headers)
response = urllib2.urlopen(request)
print response.read()