Griffin – 模型驱动的数据质量服务平台
作者:Lv, Alex
1概述
在eBay,当人们在处理大数据(Hadoop或者其它streaming系统)的时候,数据质量的检测是一个挑战。不同的团队开发了他们自己的工具在其专业领域检测和分析数据质量问题。于是我们希望能建立一个普遍适用的平台,提供共享基础设施和通用的特性来解决常见的数据质量问题,以此得到可信度高的数据。
目前来说,当数据量达到一定程度并且有跨越多个平台时(streaming数据和batch数据),数据数量验证将是十分费时费力的。拿eBay的实时个性化平台举个例子,每天我们都要处理大约600M的数据,而在如此复杂的环境和庞大的规模中,数据质量问题则成了一个很大的挑战。
在eBay的数据处理中,发现存在着如下问题:
1. 当数据从不同的数据源流向不同的应用系统的时候,缺少端到端的统一视图来追踪数据沿袭(Data Lineage)。这也就导致了在识别和解决数据质量问题上要花费许多不必要的时间。
2. 缺少一个实时的数据质量检测系统。我们需要这样一个系统:数据资产(Data Asset)注册,数据质量模型定义,数据质量结果可视化、可监控,当检测到问题时,可以及时发出警报。
3. 缺乏一个共享平台和API服务,让每个项目组无需维护自己的软硬件环境就能解决常见的数据质量问题。
为了解决以上种种问题,我们决定开发Griffin这个平台。Griffin是一个应用于分布式数据系统中的开源数据质量解决方案,例如在Hadoop, Spark, Storm等分布式系统中,Griffin提供了一整套统一的流程来定义和检测数据集的质量并及时报告问题。此项目已经发布到github上,并且也在持续改进中,欢迎fork并参与进来:https://github.com/eBay/DQSolution
主要特性:
l 精确度检测:验证结果集数据是否与源数据是一致的
l 数据剖析:利用数据集的一致性、独特性和逻辑性,来进行统计分析和数值评估。
l 异常监测:利用预先设定的算法,检测出不符合预期的数据
l 可视化监测:利用控制面板来展现数据质量的状态。
核心优势:
l 实时性:可以实时进行数据质量检测,能够及时发现问题。
l 可扩展性:可以用于多个数据系统。
l 可伸缩性:工作在大数据量的环境中,目前运行的数据量约1.2PB(eBay环境)。
l 自助服务:Griffin提供了一个简洁易用的用户界面,可以管理数据资产和数据质量规则;同时用户可以通过控制面板查看数据质量结果和自定义显示内容。
2工作流程
Griffin已经部署在eBay为核心数据系统提供服务。这个解决方案系统性地提供一组通用的功能来解决数据质量验证方面的痛点。要检测数据质量问题,主要分为以下几步:
1. 用户注册数据资产
2. 为数据资产建立一个数据质量模型
3. 模型引擎自动计算指标
4. 通过邮件或是门户网站报告数据质量问题
这里是针对以上步骤的BPMN(业务流程建模标记法)图表:
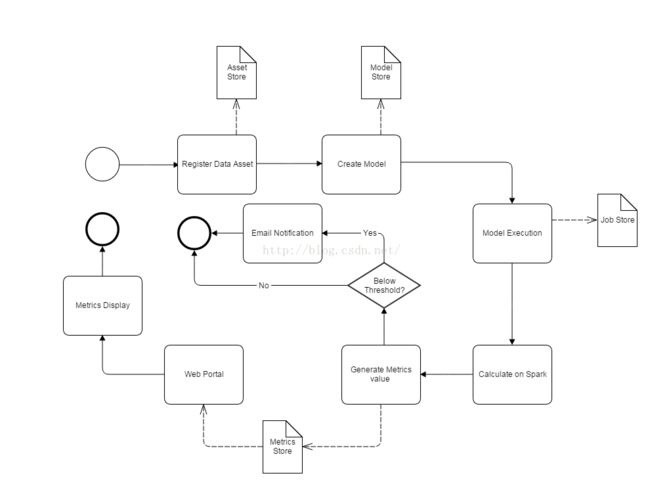
以下为每一个环节的具体内容:
2.1注册数据资产
用户把想要检测质量的数据资产注册进Griffin系统。数据资产的类型可以有很多,如离线的RDBMS(例如Teradata),Hadoop系统或是Kafka、Storm等实时数据平台。 通常情况下,注册数据资产需要提供名称、类型、数据结构、所有者等基本信息。
2.2建立模型
在注册好数据资产之后,用户可以创建数据质量模型来定义数据质量检测的规则。我们可以从不同的数据质量维度来定义模型,比如:精确度、数据分析、异常检测、有效性、时效性等维度。
2.3执行模型
通过模型或是规则的自动执行,仅几秒便可得到流数据的样本数据质量验证结果。在下一节“数据质量模型设计”中,会详细介绍模型引擎是如何设计以及执行的。
2.4利用Spark计算
这些模型运算都将在Spark上发生,为实时数据或是离线数据计算数据质量值。即便是大批量数据也可以很快地被计算出来。
2.5生成度量值
在数据质量值计算完成之后,根据计算结果生成度量值,并存放于数据库。
2.6邮件通知
如果度量值低于所设阈值,邮件通知功能将会被触发,终端用户会及时收到提醒。
2.7门户网站和度量值显示
所有的度量值最终都会在门户网站上显示出来,这样用户可以通过内置的可视化工具来分析数据质量结果,并采取相应的行动。
3系统架构
为了实现上述过程,我们为系统设计了三层结构:数据收集处理层(Data Collection&Processing Layer)、后端服务层(Backend Service Layer)和用户界面(User Interface)。请参考以下架构设计图:
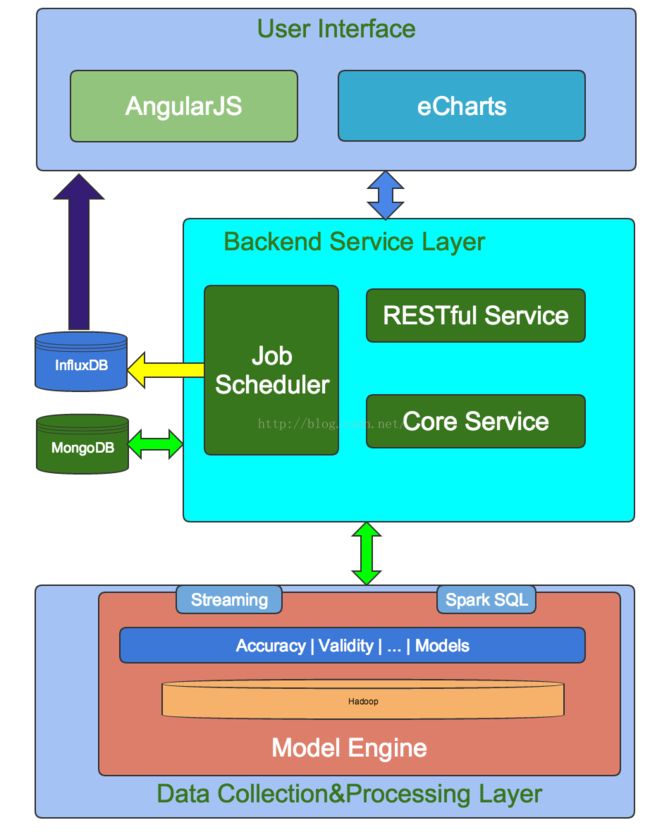
3.1数据收集处理层
在这一层,最关键的是模型引擎(Model Engine),Griffin是模型驱动的解决方案。基于目标数据集(targetdata-set)或者源数据集(作为高真的基准数据源 –“golden reference data”), 用户可以选择不同的数据质量维度来执行目标数据质量验证。我们有内置的程序库来支持以下检测方式:我们支持两种类型的数据源,batch数据和streaming数据。对于batch数据,我们可以通过数据连接器从Hadoop平台收集数据。对于streaming数据,我们可以连接到诸如Kafka之类的消息系统来做近似实时数据分析。在拿到数据之后,模型引擎将在我们的spark集群中计算数据质量。
3.2后端服务层
在这一层上,有三个关键组件:
l 核心服务:用来管理元数据,例如模型定义、订阅管理和用户定制等等。
l 作业调度:根据模型的定义创建并调度作业,然后触发模型引擎的运行并取得度量值结果,然后存储度量值,并在检测到数据质量问题时发送电子邮件通知。
l REST服务:我们提供了内置的REST服务来实现Griffin的各项功能,例如注册数据资产,创建数据质量模型,度量发布,度量检索,添加订阅等等。因此,开发人员可以基于这些web服务开发自己的用户界面。
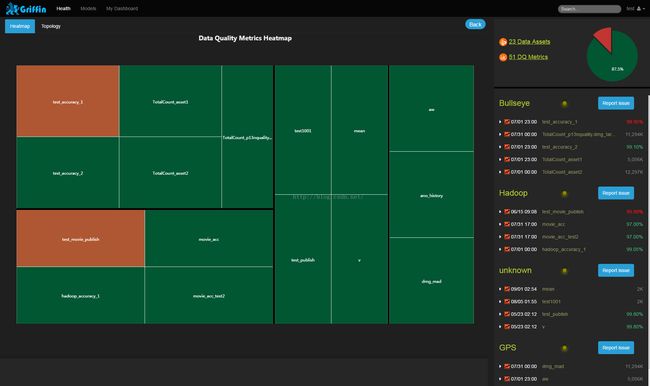
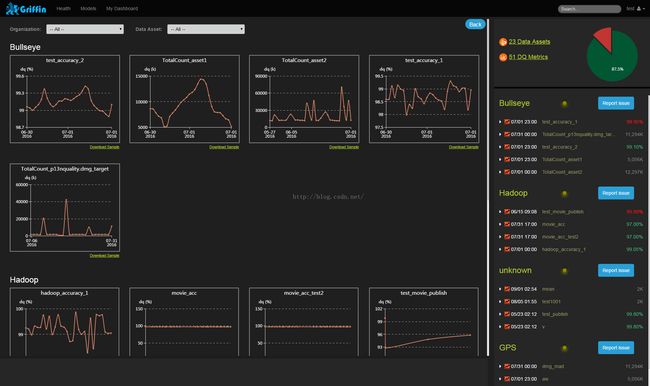
3.3用户界面
Griffin有一个内置的可视化工具,它是基于AngularJS和eCharts开发的web前端应用,可以很好地展现数据质量结果。以下是一些屏幕截图:
4数据质量模型设计
4.1精确度
对于一个给定的目标数据集(target dataset),它的数据质量是否真正如所预期的那样反映真实的数值?我们如何验证它的精确度?我们可以想办法找到它可对比的高真的基准数据源(goldenreference dataset)或者叫真实数据源(source oftruth),它们可以是经过一些逻辑处理后的上游数据而得来,或者也可以是直接来自符合用户业务规则需求的数据集,或者来自于第三方验证的数据。
现在我们有了基准数据集和目标数据集。那么,我们通过定义规则来比较两者,就可以测量目标数据源的精确度了。 比如:数据源包含了100条记录,但是在目标数据集,只有95条记录与数据源匹配,那么精确度值就是95/100*100% = 95.00%
方法
正如上文中所提及的,通过以下三步便可创建一个精确度模型。
l 用户可以定义一个高真的基准数据源(golden reference dataset)或者叫真实数据源(source of truth)
l 用户可以在界面上选择基准数据和目标数据的映射规则。
l 用户提交后,后端将会调度作业来计算精确度结果。
后端实现
假设基准数据源为S (source),目标数据集为T(target),下面将要介绍如何测量精确度。
所谓测量目标数据集T的精确度,最通常的方法则是通过一项项比较源和目标数据集中的内容计算出差值,测量所有字段是否相同,公式如下:

鉴于两个数据集都很大,因此我们利用MapReduce的编程模型进行分布式计算。
但事实上最大的挑战在于提高这个匹配算法的通用性,这不仅可以减轻数据分析师在编码方面的负担,同时对于不同的精确度需求也具有很高的灵活性。
传统上是利用基于SQL的方法来进行计算,就像hive中的scripts一样。但是这种方法没有考虑源数据和目标数据集的独特性,因此还具有提升的空间。
我们综合考虑了源数据集和目标数据集的特殊性质后,提出了一个通用的精确度模型。
基于scala的强大的表达能力,我们的算法由scala实现,并且可以在spark集群中运行。
4.2数据剖析
剖析类型
数据质量问题可以通过不同的数据剖析类型展现出来。分析结果与期望值相比较,如果二者不相符的话则会发出警告。
在Griffin中共有三种剖析类型:
1. 简单统计:用来统计表的特定列里面值为空、唯一或是重复的数量。
例如空值统计:反映了在所选列中值为空的数量。这可以帮助用户发现数据中的问题,例如一个列中为空的值的比率过高,则说明数据可能有问题。具体点说,假设设置一个列存放电子邮件信息,但很多数据都丢失了,这样利用空值统计可以发现数据中存在的问题。
2. 汇总统计:用来统计最大值、最小值、平均数、中值等。
例如对于年龄值来说,通常情况下都是应该大于0小于150的,用户可以通过统计年龄那一列中的最大值和最小值来分析数据是否正确。
3. 高级统计:用正则表达式来对数据的频率和模式进行分析。
例如对于美国邮政编码,可以用此类正则表达式表示:\d{5}-\d{4}, \d{5}或者\d{9}。如果出现可以用其他格式的数据,则说明表中很可能存在着无效或者格式错误的数据。
后端实现
我们的数据分析机制主要是基于Spark的MLlib提供的列汇总统计功能,它对所有列的类型统计只计算一次。
主要优势:
1. 我们的框架是基于Spark的,这也就使得对于大数据的分析速度很快。
2. 在创建模型之后,数据分析是自动进行的。
3. 历史趋势可视化。
4.3异常检测
异常检测的目标是从看似正常的数据中发现异常情况,是一个检测数据质量问题的重要工具。目前我们通过使用BollingerBands和MAD算法来实现异常检测功能,可以发现数据集中那些远远不符合预期的数据。而预期值则是在对历史趋势的分析中得来的。用户会根据我们所检测到的异常来调整算法中必要的参数,而更改后的参数则会及时动态地显示出来,这对于不同的用户来说也更加具体。
后端实现
以MAD作为例子,一个数据集的MAD值反映的是每个数据点与均值之间的距离。可以通过以下步骤来得到MAD值:
1. 算出均值
2. 算出每一个数据点与均值的差
3. 对差值取绝对值
4. 算出这些差值取绝对值之后的平均值
公式如下:
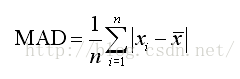
BollingerBand与MAD类似,更多细节可以参考https://en.wikipedia.org/wiki/Bollinger_Bands
5Griffin在eBay的使用
Griffin现在已经部署在eBay的生产环境中,为许多eBay系统提供核心数据质量检测服务(例如:实时的个性化数据平台,Hadoop 数据集, 网站运行速度监测),每天验证的记录超过8亿条,数据量约1.2PB。
6展望未来
1. 我们正在把Griffin引入到更多的eBay系统,使它成为eBay内部统一的数据质量检测平台。
2. 我们已经开源这个项目,使更多公司、组织或个人受益,可以点击https://ebay.github.io/DQSolution/查看项目详情,欢迎多多fork 。
3. 我们今后将会不断改进,支持更多类型和实时数据源的数据质量维度,例如:有效性、完整性、唯一性、时效性和一致性等。
4. 我们将会开发更多的机器学习算法,可以用来自动检测更加深层复杂的数据内容之间的质量关系,以此来发现其中数据质量的问题。
项目链接:https://ebay.github.io/DQSolution/
联系方式:[email protected]