Java实现简单的kmeans聚类
Kmeans的Java实现
最近决定将《机器学习》(周志华版)中的算法手动写一遍,加深理解。先拿最简单的kmeans聚类开刀吧。算法的原理和步骤在《机器学习》这本书中都有很详细的介绍,这里就不多说。代码献上,希望大伙批评指正。
这里我用的测试集是随机生成的二维平面点集
为了使结构比较清晰,将具体的操作封装到KMeansCluster.java类中
涉及的java类如下:
- Kmean.java
- KMeansCluster.java
- Point.java
先贴一张类图,理清类之间的关系
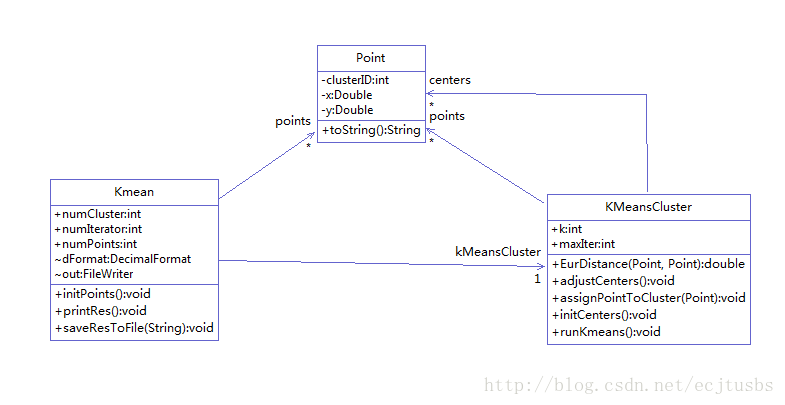
Kmean是主类,通过此类设置簇的数目,测试样本数个数,迭代次数等。这些参数最终传给KmeansCluster对象
KmeansCluster接受上述几个参数,完成实际的聚类操作。
Point:二维数据点,包括x、y坐标以及代表所属类的ID:clusterID
代码部分
Kmean.java
package kmeans;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.List;
public class Kmean
{
// 用来聚类的点集
public List points;
// 将聚类结果保存到文件
FileWriter out = null;
// 格式化double类型的输出,保留两位小数
DecimalFormat dFormat = new DecimalFormat("00.00");
// 具体执行聚类的对象
public KMeansCluster kMeansCluster;
// 簇的数量,迭代次数
public int numCluster = 5;
public int numIterator = 200;
// 点集的数量,生成指定数量的点集
public int numPoints = 50;
//聚类结果保存路径
public static final String FILEPATH="f:/kmeans/res.txt";
public static void main(String[] args)
{
//指定点集个数,簇的个数,迭代次数
Kmean kmeans = new Kmean(100, 5, 200);
//初始化点集、KMeansCluster对象
kmeans.init();
//使用KMeansCluster对象进行聚类
kmeans.runKmeans();
kmeans.printRes();
kmeans.saveResToFile(FILEPATH);
}
public Kmean(int numPoints, int cluster_number, int iterrator_number) {
this.numPoints = numPoints;
this.numCluster = cluster_number;
this.numIterator = iterrator_number;
}
private void init()
{
this.initPoints();
kMeansCluster = new KMeansCluster(numCluster, numIterator, points);
}
private void runKmeans()
{
kMeansCluster.runKmeans();
}
// 初始化点集
public void initPoints()
{
points = new ArrayList<>(numPoints);
Point tmpPoint;
for (int i = 0; i < numPoints; i++)
{
tmpPoint = new Point(Math.random() * 150, Math.random() * 100);
points.add(tmpPoint);
}
}
public void printRes()
{
System.out.println("==================Centers-I====================");
for (Point center : kMeansCluster.centers)
{
System.out.println(center.toString());
}
System.out.println("==================Points====================");
for (Point point : points)
{
System.out.println(point.toString());
}
}
public void saveResToFile(String filePath)
{
try
{
out = new FileWriter(new File(filePath));
for (Point point : points)
{
out.write(String.valueOf(point.getClusterID()));
out.write(" ");
out.write(dFormat.format(point.getX()));
out.write(" ");
out.write(dFormat.format(point.getY()));
out.write("\r\n");
}
out.flush();
out.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
KMeansCluster.java
package kmeans;
import java.util.ArrayList;
import java.util.List;
public class KMeansCluster
{
// 聚类中心数
public int k = 5;
// 迭代最大次数
public int maxIter = 50;
// 测试点集
public List points;
// 中心点
public List centers;
public static final double MINDISTANCE = 10000.00;
public KMeansCluster(int k, int maxIter, List points) {
this.k = k;
this.maxIter = maxIter;
this.points = points;
//初始化中心点
initCenters();
}
/*
* 初始化聚类中心
* 这里的选取策略是,从点集中按序列抽取K个作为初始聚类中心
*/
public void initCenters()
{
centers = new ArrayList<>(k);
for (int i = 0; i < k; i++)
{
Point tmPoint = points.get(i * 2);
Point center = new Point(tmPoint.getX(), tmPoint.getY());
center.setClusterID(i + 1);
centers.add(center);
}
}
/*
* 停止条件是满足迭代次数
*/
public void runKmeans()
{
// 已迭代次数
int count = 1;
while (count++ <= maxIter)
{
// 遍历每个点,确定其所属簇
for (Point point : points)
{
assignPointToCluster(point);
}
//调整中心点
adjustCenters();
}
}
/*
* 调整聚类中心,按照求平衡点的方法获得新的簇心
*/
public void adjustCenters()
{
double sumx[] = new double[k];
double sumy[] = new double[k];
int count[] = new int[k];
// 保存每个簇的横纵坐标之和
for (int i = 0; i < k; i++)
{
sumx[i] = 0.0;
sumy[i] = 0.0;
count[i] = 0;
}
// 计算每个簇的横纵坐标总和、记录每个簇的个数
for (Point point : points)
{
int clusterID = point.getClusterID();
// System.out.println(clusterID);
sumx[clusterID - 1] += point.getX();
sumy[clusterID - 1] += point.getY();
count[clusterID - 1]++;
}
// 更新簇心坐标
for (int i = 0; i < k; i++)
{
Point tmpPoint = centers.get(i);
tmpPoint.setX(sumx[i] / count[i]);
tmpPoint.setY(sumy[i] / count[i]);
tmpPoint.setClusterID(i + 1);
centers.set(i, tmpPoint);
}
}
/*划分点到某个簇中,欧式距离标准
* 对传入的每个点,找到与其最近的簇中心点,将此点加入到簇
*/
public void assignPointToCluster(Point point)
{
double minDistance = MINDISTANCE;
int clusterID = -1;
for (Point center : centers)
{
double dis = EurDistance(point, center);
if (dis < minDistance)
{
minDistance = dis;
clusterID = center.getClusterID();
}
}
point.setClusterID(clusterID);
}
//欧式距离,计算两点距离
public double EurDistance(Point point, Point center)
{
double detX = point.getX() - center.getX();
double detY = point.getY() - center.getY();
return Math.sqrt(detX * detX + detY * detY);
}
}
Point.java
package kmeans;
public class Point
{
// 点的坐标
private Double x;
private Double y;
// 所在类ID
private int clusterID = -1;
public Point(Double x, Double y) {
this.x = x;
this.y = y;
}
@Override
public String toString()
{
return String.valueOf(getClusterID()) + " " + String.valueOf(this.x) + " " + String.valueOf(this.y);
}
public Double getX()
{
return x;
}
public void setX(Double x)
{
this.x = x;
}
public Double getY()
{
return y;
}
public void setY(Double y)
{
this.y = y;
}
public int getClusterID()
{
return clusterID;
}
public void setClusterID(int clusterID)
{
this.clusterID = clusterID;
}
}
代码详解等下次有时间再补上。囧
测试结果
虽然代码比较水,但还是可以运行成功的,先贴一张结果图,
所用的参数如下:
//指定点集个数,簇的个数,迭代次数
Kmean kmeans = new Kmean(100, 5, 200);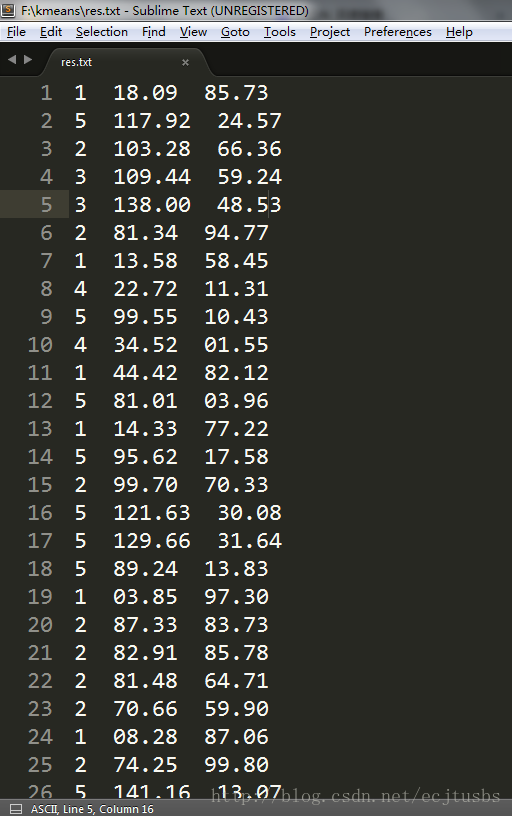
每行分别代表所属的类,x坐标,y坐标
没有实现可视化,聚类结果不直观,o(╯□╰)o