IO流的读写操作
Java IO流的分类:
除了按照流的方向可以把流划分为输入流和输出流两类,按照流读写数据的基本单位把流划分为字节流和字符流两类以外,还可以按照流是否直接连接实际数据源,例如文件、网络、字节数组等,将流又可以划分为实体流和装饰流两大类。
其中实体流指直接连接数据源的流类,如前面介绍的FileInputStream/FileOutputStream和FileReader和FileWriter,该类流直接实现将数据源转换为流对象,在实体流类中实现了流和数据源之间的转换,实体流类均可单独进行使用。
而装饰流指不直接连接数据源,而是以其它流对象(实体流对象或装饰流对象)为基础建立的流类,该类流实现了将实体流中的数据进行转换,增强流对象的读写能力,比较常用的有DataInputStream/DataOutputStream和BufferedReader/BufferedWriter等,装饰流类不可以单独使用,必须配合实体流或装饰流进行使用。
由于装饰流都是在已有的流对象基础上进行创建的,所以这种创建流的方式被称作“流的嵌套”,通过流的嵌套,可以修饰流的功能,例如使读写的速度增加或者提供更多的读写方式,方便数据格式的处理。
装饰流不改变原来实体流对象中的数据内容,只是从实体流对象基础上创建出的装饰流对象相对于实体流对象进行了一些功能的增强。
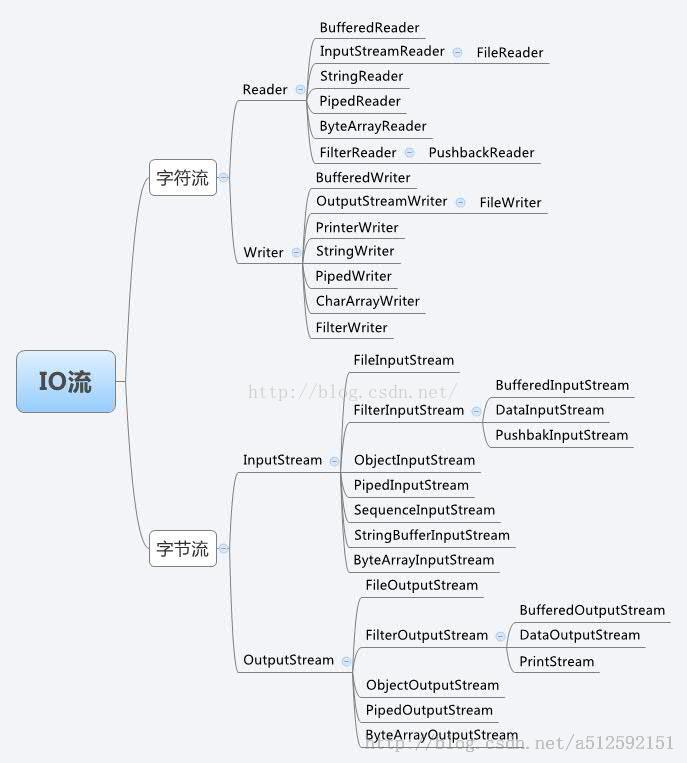
1. IO体系中的子类名后缀绝大部分是父类名称,而前缀则是体现子类特有功能的名称。
2. 输入字节流InputStreamIO 中输入字节流的继承图可见上图,可以看出:
InputStream 是所有的输入字节流的父类,它是一个抽象类。
ByteArrayInputStream、StringBufferInputStream、FileInputStream是三种基本的介质流,
它们分别从Byte 数组、StringBuffer、和本地文件中读取数据。PipedInputStream 是从与其它线程共用的管道中读取数据。
ObjectInputStream 和所有FilterInputStream 的子类都是装饰流。
3. 输出字节流OutputStream
IO 中输出字节流的继承图可见上图,可以看出:
OutputStream 是所有的输出字节流的父类,它是一个抽象类。
ByteArrayOutputStream、FileOutputStream 是两种基本的介质流,它们分别向Byte 数组、和本地文件中写入数据。
PipedOutputStream 是向与其它线程共用的管道中写入数据,
ObjectOutputStream 和所有FilterOutputStream 的子类都是装饰流。
Reader中常见的方法:
int read() :读取一个字符,并返回读到的这个字符,读到流的末尾则返回-1。
int read(char[]) :将读到的字符存入指定的数组中,返回的是读到的字符个数,读到流的末尾则返回-1。
close() :读取字符其实用的是window系统的功能,就希望使用完毕后,进行资源的释放。
Writer中常见的方法:
write() :将一个字符写入到流中。
write(char[]) :将一个字符数组写入到流中。
writer(String): 将一个字符写入到流中。
flush():刷新流,将流中的数据刷新到目的地中,流还存在。
close() :关闭资源,在关闭钱会先调用flush(),刷新流中的数据到目的地。
字符流的缓冲区:
缓冲区的出现提高了对流的操作效率。 原理:其实就是将数组进行封装。
对应的对象 :BufferedWriter
特有方法newLine(),跨平台的换行符。
BufferedReader :特有方法readLine(),一次读一行,到行标记时,将行标记之前的字符数据作为字符串返回,读到末尾返回null。
说明在使用缓冲区对象时,要明确,缓冲的存在是为了增强流的功能而存在,所以在建立缓冲区对象时,要先有流对象存在。其实缓冲区内部就是在使用流对象的方法,只不过加入了数组对数据进行了临时存储,为了提高操作数据的效率。
写入缓冲区对象 :根据前面所说的建立缓冲区时要先有流对象,并将其作为参数传递给缓冲区的构造函数
BufferedWriter bufw=new BufferedWriter(new FileWriter(“test.txt”));
bufw.write(“将数据写入缓冲区”);
bufw.flush();//将缓冲区的数据刷新到目的地
bufw.close();//其实关闭的是被包装在内部的流对象
读取缓冲区对象
BufferedReader bufr=new BufferedReader(new FileReader(“test.txt”));
String line=null;
while((line=bufr.readLine())!=null){ //每次读取一行,取出的数据不包含回车符
system.out.println(line); }
bufr.close();
使用缓冲区对文本文件进行拷贝代码:
private static void test4(){
BufferedReader bufr=null;
BufferedWriter bufw=null;
try {
bufr=new BufferedReader(new FileReader("D:/a.txt"));
bufw=new BufferedWriter(new FileWriter("D:/b.txt"));
String line=null;
while((line=bufr.readLine())!=null){
bufw.write(line);//每次将一行写入缓冲区
bufw.flush();//刷新到目的地
}
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(bufw!=null){
bufw.close();
}
if(bufr!=null){
bufr.close();
}
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
在进行流的关闭时,先关闭输出流,在关闭输入流。
字节流:
InputStream(读)
OutputStream(写)
由于字节是二进制数据,所以字节流可以操作任何类型的数据,值得注意的是字符流使用的是字符数组char[]而字节流使用的是字节数组byte[]。
使用字节流读写文本
private static void test5(){
FileOutputStream fos=null;
try{
fos=new FileOutputStream("D:/test.txt");
fos.write(0010);//写入二进制数据
fos.flush();
}catch(IOException e){
}finally{
try{
fos.close();
}catch(IOException ex){
}
}
FileInputStream fis=null;
try{
fis=new FileInputStream("D:/test.txt");
//fis.available()是获取关联文件的字节数,即test.txt的字节数
//这样创建的数组大小就和文件大小刚好相等
//这样做的缺点就是文件过大时,可能超出jvm的内存空间,从而造成内存溢出
byte[] buf=new byte[fis.available()];
fis.read(buf);
System.out.println(new String(buf));
}catch(IOException e){
}finally{
try{
fos.close();
}catch(IOException ex){
}
}
}
转换流:是字节流和字符流之间的桥梁
该流对象可以对读取到的字节数据进行指定编码表的编码转换
何时使用: 当字节和字符之间有转换动作时;流操作的数据需要进行编码表的指定时。
具体对象体现 :InputStreamReader:字节到字符的桥梁
OutputStreamWriter:字符到字节的桥梁
构造函数:
InputStreamReader(InputStream) :通过该构造函数初始化,使用的是系统默认的编码表GBK。
InputStreamReader(InputStream,String charset) :通过该构造函数初始化,可以通过charset参数指定编码。
OutputStreamWriter(OutputStream):使用的是系统默认的编码表GBK。
OutputStreamWriter(OutputSream,String charset) :通过该构造函数初始化,可以通过参数charset指定编码。
操作文件的字符流对象是转换流的子类
|--Reader
|--InputStreamReader(转换流)
|--FileReader(文件字符流)
|--Writer
|--OutputStreamWriter(转换流)
|--FileWriter(文件字符流)
在使用FileReader操作文本数据时,该对象使用的是默认的编码表,如果要使用指定的编码表,必须使用转换流。
操作test.txt中的数据都是使用了系统默认的编码GBK:
InputStreamReader isr=new InputStreamReader(new FileInputStreamReader(“test.txt”));
如果test.txt中的数据是通过UTF-8形式编码的,那么在读取的时候就需要指定编码表:
isr=newInputStreamReader(new FileInputStream(“a.txt”),”UTF-8”);
由于编码不同,多字节的字符可能占用多个字节。比如GBK的汉字就占用2个字节,而UTF-8的汉字就占用3个字节。
其实所有的字符流的实质上是对字节流的封装,在方法的底层还是对字节流方法的调用,所以任何基于字节的操作都是正确的。无论你是文本文件还是二进制的文件又或者是图片和多媒体文件。但是字节流在处理纯文本的文件时,效率是不如字节流的,所以如果确认流里面只有可打印的字符,包括英文的和各种国家的文字,也包括中文,那么可以考虑用字符流。