一、boston房价预测
1. 读取数据集
2. 训练集与测试集划分
3. 线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
4. 多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
5. 比较线性模型与非线性模型的性能,并说明原因。
二、中文文本分类
按学号未位下载相应数据集。
147:财经、彩票、房产、股票、
258:家居、教育、科技、社会、时尚、
0369:时政、体育、星座、游戏、娱乐
分别建立中文文本分类模型,实现对文本的分类。基本步骤如下:
1.各种获取文件,写文件
2.除去噪声,如:格式转换,去掉符号,整体规范化
3.遍历每个个文件夹下的每个文本文件。
4.使用jieba分词将中文文本切割。
中文分词就是将一句话拆分为各个词语,因为中文分词在不同的语境中歧义较大,所以分词极其重要。
可以用jieba.add_word('word')增加词,用jieba.load_userdict('wordDict.txt')导入词库。
维护自定义词库
5.去掉停用词。
维护停用词表
6.对处理之后的文本开始用TF-IDF算法进行单词权值的计算
7.贝叶斯预测种类
8.模型评价
9.新文本类别预测
处理过程中注意:
- 实验过程中文件遍历从少量到多量,调试无误后再处理全部文件
- 判断文件大小决定读取方法
- 注意保存中间结果,以免每次从头读取文件重复处理
- 内存不足时进行分批处理
- 利用数组的保存np.save('x1.npy',x1)与数组的读取np.load('x1.npy')和数组的拼接np.concatenate((x1,x2),axis=0)
- 及时用 del(x1) 释放大块内存,用gc.collect()回收内存。
- 边处理边保存数据,不要处理完了一次性保存。万一中间发生的异常情况,就全部白做了。
- 进行Python 异常处理,把出错的文件单独记录,程序可以继续执行。回头再单独处理出错的文件。
- 在准备长时间无监督运行程序之前,请关闭windows自动更新、自动屏保关机等......
#线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
boston=load_boston()#导入数据集
x = boston.data
y = boston.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)#划分训练集和测试集
lineR=LinearRegression()#线性模型
lineR.fit(x_train,y_train)
#判断模型的好坏
print('预测的准确率:',lineR.score(x_test,y_test))

#4. 多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=2)
from sklearn.linear_model import LinearRegression
lineR=LinearRegression()
x= boston.data
y = boston.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)#划分训练集和测试集
#多项式操作
x_train_poly=poly.fit_transform(x_train)
x_test_poly=poly.transform(x_test)
lineR.fit(x_train_poly,y_train)#建立模型
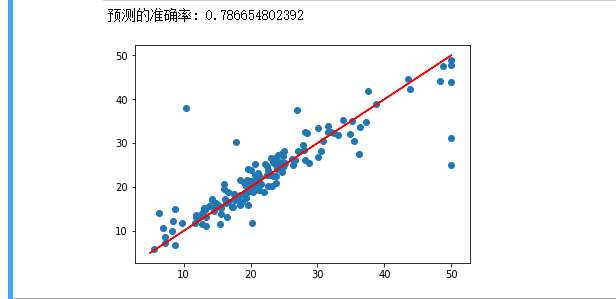
print('预测的准确率:',lineR.score(x_test_poly,y_test))
#图形化
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
lineR=LinearRegression()
lineR.fit(x_train_poly,y_train)
y_poly_pred=lineR.predict(x_test_poly)
plt.plot(y,y,'r')
plt.scatter(y_test,y_poly_pred)
plt.show()
#新闻文本分类
import os
import jieba
#读取文件内容
content=[]#存放新闻的内容
label=[]#存放新闻的类别
def read_txt(path):
folder_list=os.listdir(path)#遍历data下的文件名
for file in folder_list:
new_path=os.path.join(path,file) #读取文件夹的名称,生成新的路径
files=os.listdir(new_path)#存放文件的内容
#遍历每个txt文件
for f in files:
with open(os.path.join(new_path,f),'r',encoding='UTF-8')as f: #打开txt文件
temp_file=f.read()
content.append(processing(temp_file))
label.append(file)
print(content)
print(label)
#划分训练集和测试,用TF-IDF算法进行单词权值的计算
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
tfidf= TfidfVectorizer()
x_train,x_test,y_train,y_test=train_test_split(content,label,test_size=0.2)
X_train=tfidf.fit_transform(x_train)
X_test=tfidf.transform(x_test)
#构建贝叶斯模型
from sklearn.naive_bayes import MultinomialNB #用于离散特征分类,文本分类单词统计,以出现的次数作为特征值
mulp=MultinomialNB ()
mulp_NB=mulp.fit(X_train,y_train)
#对模型进行预测
y_predict=mulp.predict(X_test)
# # 从sklearn.metrics里导入classification_report做分类的性能报告
from sklearn.metrics import classification_report
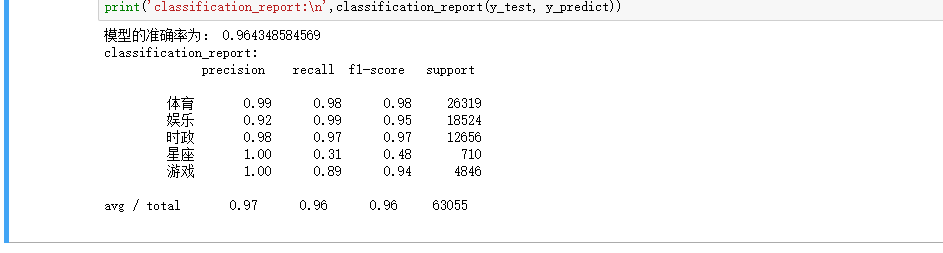
print('模型的准确率为:', mulp.score(X_test, y_test))
print('classification_report:\n',classification_report(y_test, y_predict))