循环神经网络(RNN)中的LSTM和GRU模型的内部结构与意义
LSTM和GRU的基本结构
循环神经网络 RNN 是一种很重要的网络结构模型,通过每个时刻利用当前的输入以及之前的输出,在同一个单元产生当前时刻的输出,从而可以用来处理具有一定时序的问题,比如语音信号处理,机器翻译,股票走势等等。RNN的基本单元如下:
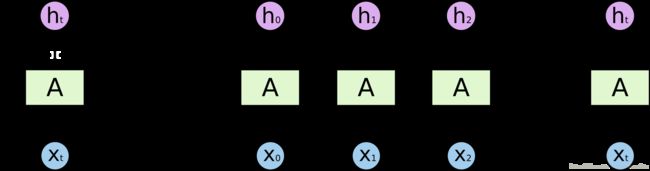
左边表示RNN的R,即循环调用自身,而右边是RNN的展开形式,unrolled form,可以看成一个复制了很多个同样copy的链状结构的时序网络模型。常见的结构有LSTM及其变种,以及GRU结构。
LSTM基本结构与思想
LSTM模型是用来解决simple RNN对于长时期依赖问题(Long Term Dependency),即通过之前提到的但是时间上较为久远的内容进行后续的推理和判断。LSTM的基本思路是引入了门控装置,来处理记忆单元的记忆/遗忘、输入程度、输出程度的问题。通过一定的学习,可以学到何时对各个门开启到何种程度,因为门控也是由有一定可以学习的参数的神经网络来实现的,这样就可以让机器知道何时应该记住某个信息,而何时应该抛弃某个信息。
标准的RNN结构如图:
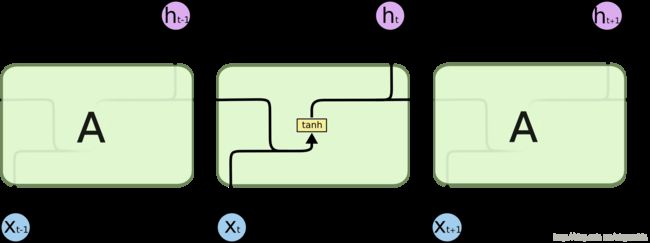
也就是将上一个时刻的输出加上本时刻的输入,过一个activation,比如tanh,就成了下一个时刻的输出。这是最简单也最好理解的RNN结构,而LSTM是改进版的RNN,由于它的三个门(gate),结构就稍稍复杂了一些:
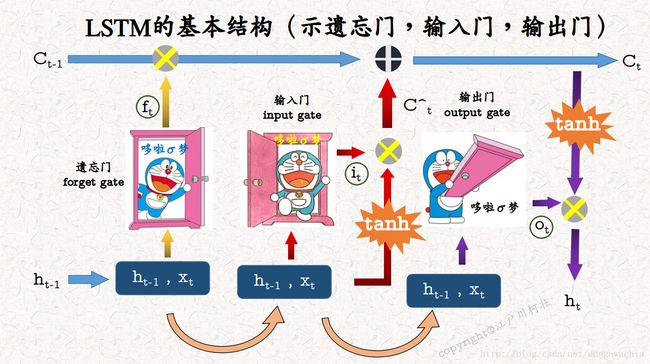
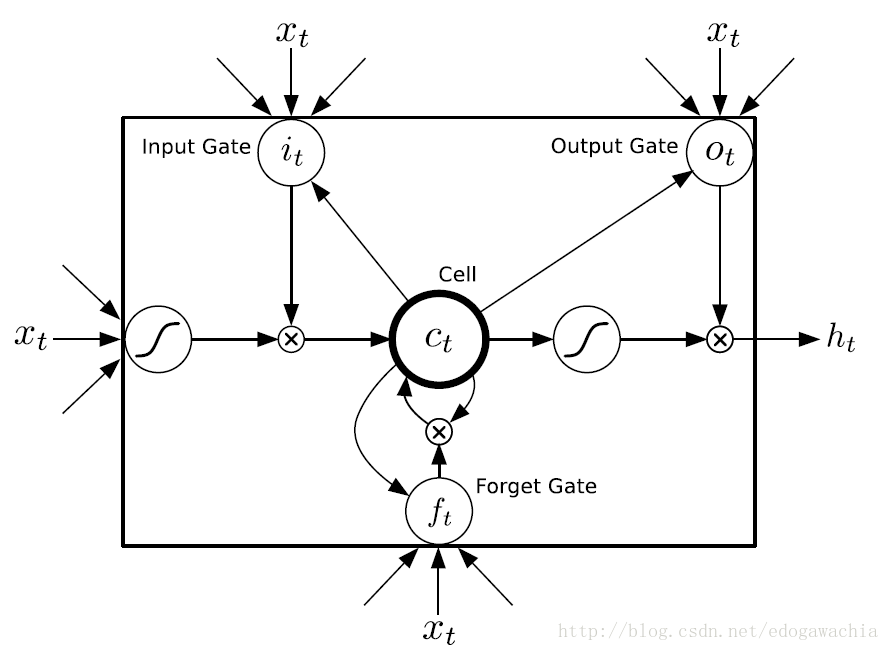
对照上面那个机器猫的图,可以看出,LSTM的流程是这样的:首先,每一个时刻都有一个输出和cell state,输出就是上面的h,state就是C,那么,对于下一个时刻,把上一个时刻的输出连带着这一个时刻的输入作为整体,当做cell的输入,同时也是控制三个门的输入。首先,先要经过一个遗忘门,forget gate,注意到,sigma表示sigmoid函数,0到1之间,如果遗忘门的输出结果接近0,表示尽量忘掉上一个时刻的输出,而接近1表示进行记忆;然后,上一个状态残存的部分(Ct-1和ft的乘积)继续向前,它要加上这个状态的输入的信息,那么又遇到了输入门,input gate,这个门表征通过多少量的输入,经过输入门处理后的输入信号(在进入输入门之前要对输入做tanh运算,把值域压缩到[-1,1]范围内)和前面的上一个state的残余加起来,就是这个时刻的细胞状态。
这样,细胞状态,就是state完成了从t-1到t时刻的更新,那么输出和状态C有何关系呢?这就是最后一个门,输出门的功能,输出门和tanh后的cell state相乘,结果就是t时刻的输出。
总结上面的步骤,即可写出LSTM的公式:


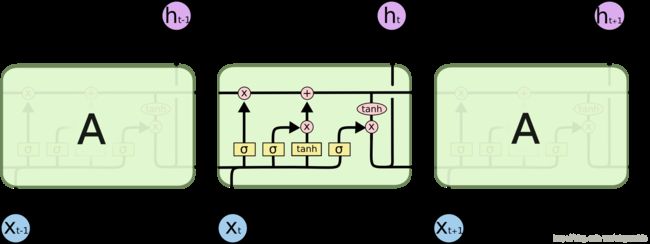
LSTM的结构还有另外一种示意图,不过可能较难理解,当上面的内容清晰了以后,可以参考:
还有几种LSTM的变体:Peephole LSTM,在三个门控的输入中除了h(t-1)和x(t)以外,还加上了C(t-1)。另一种将ft和it,也就是forget gate的结果和input gate的结果couple起来,从而让input gate = 1 - forget gate。
GRU基本结构与思想
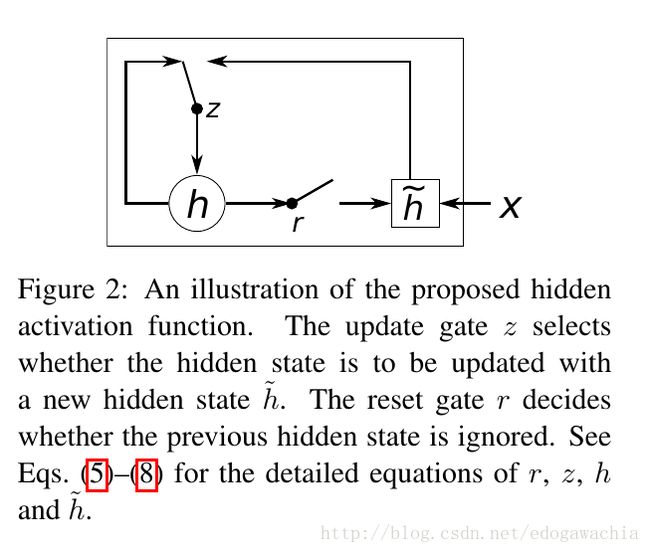
GRU的结构如上图所示,虽然有时候GRU被视为LSTM的一个variation,不过两者差别还是比较大的,所以单独讨论。
GRU不像LSTM的三门控,它虽然也有门,但是只有两个,分别叫做重置门(reset gate),和更新门(update gate)。重置门顾名思义,控制着是否重置,也就是说多大程度上擦除以前的状态state;更新门则表示,多大程度上要用candidate 来更新当前的hidden layer。下面是另一种示意图,以及它的公式:

从这个图的公式来看,r和z就是两个门,分别表示reset和update。(此图的公式和论文Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation 中的公式略有出入,见下图,个人以为此图更好,因为逻辑上讲update越大应该更新的内容,也就是选择的candidate的内容越多)

GRU的基本原理是,首先,用x(t)和h(t-1)生成两个门,然后用reset门乘以上一时刻的状态,看看是否要reset或者reset多大程度,然后,和新输入的x拼接,过网络并用tanh激活,形成candidate的隐含变量\hat{h_t},然后,将上一时刻的h和candidate的h做一个线性组合,两者的权重和为1,candidate的权重就是update门的输出,表征更新强度多大。
要注意的是,h只是一个变量,因此在每个时刻,包括最后的线性组合,h都是在用以前的自己和当前的备选答案更新自己。举例来说,这一个变量好比一杯酒,每次我们要把一部分酒倒出去,并把倒出去的酒和新加入的原料混合,然后在倒回来,这里的reset控制的就是要倒出去的,并且混合好之后再倒回来的酒的比例,而update控制的则是用多大的比例混合新原料和倒出来的之前调制好的酒。同理,也可以以此理解LSTM,LSTM的遗忘门功能上和reset相似,而输入门与update相似,不同之处在于LSTM还控制了当前状态的exposure,也就是输出门的功能,这是GRU所没有的。
GRU参数少,好训练,结构相对简单一些。对于上图展示的GRU公式,如果reset = 1,update = 1,那么就变成了一个plain RNN。实际上,有测试表明,RNN各种变体之间性能上相差不大,基本相同。
2018年02月25日22:50:07
reference:http://colah.github.io/posts/2015-08-Understanding-LSTMs/