SQL排序函数基础详解 row_number()/rank()/dense_rank() over(partition by)
为了方便学习和测试,所有的例子都是在Oracle自带用户Scott下建立的。
我用了mysql的环境,借助以下语句进行建表和插入数据,以备后续练习使用
create table EMP --创建表EMP
(
empno int(4) not null,
ename VARCHAR(10),
job VARCHAR(9),
mgr int(4),
hiredate DATE,
sal decimal(7,2),
comm decimal(7,2),
deptno int(2)
)
alter table EMP add primary key (EMPNO); --为表追加empno列为主键
--插入数据
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, str_to_date('1980-12-17', '%Y-%m-%d'), 800, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, str_to_date('1981-02-20', '%Y-%m-%d'), 1600, 300, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, str_to_date('1981-02-22', '%Y-%m-%d'), 1250, 500, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, str_to_date('1981-04-02', '%Y-%m-%d'), 2975, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, str_to_date('1981-09-28', '%Y-%m-%d'), 1250, 1400, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, str_to_date('1981-05-01', '%Y-%m-%d'), 2850, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, str_to_date('1981-06-09', '%Y-%m-%d'), 2450, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, str_to_date('1987-04-19', '%Y-%m-%d'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, str_to_date('1981-11-17', '%Y-%m-%d'), 5000, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, str_to_date('1981-09-08', '%Y-%m-%d'), 1500, 0, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, str_to_date('1987-05-23', '%Y-%m-%d'), 1100, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, str_to_date('1981-12-03', '%Y-%m-%d'), 950, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, str_to_date('1981-12-03', '%Y-%m-%d'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, str_to_date('1982-01-23', '%Y-%m-%d'), 1300, null, 10);
- 1.假如现在有这样一个需求,查询每个部门工资最高的雇员的信息,一般面对"最大","最小"问题的时候我们最容易想到的是用max(),min()等聚合函数来解决
外链接:
-- 1.查询每个部门工资最高的雇员的信息
select * from
(SELECT ename,job,hiredate,sal,deptno from emp)t1
right join
(select deptno,max(sal) sal from emp group by deptno)t2
on t1.deptno = t2.deptno and t1.sal = t2.sal
order by t1.deptno;
思路:我们先看看查询t2表的语句干了什么,
select deptno,max(sal) sal from emp group by deptno
以deptno 部门分组,同事利用max()筛选出sal工资列的最高数值,查询的结果即为每个部门的最高工资及对应部门;

我们的需求是每个部门最高工资员工的信息,此时我们已经完成一半,既然需要相关信息那么我们势必需要将全部员工的相关信息先查询出来,再通过与刚才t2表(部门,最高工资)做连接的操作,即以t2表为基表,以deptno与sal值相等的作为限制条件,对两个表做笛卡尔积取结果集,得到结果如下:

或者我们以内连接方式查询
select * from (select ename, job, hiredate, sal, deptno
from emp)t1,
(select deptno, max(sal) sal from emp group by deptno)t2
where t1.deptno = t2.deptno
and t1.sal = t2.sal
order by t1.deptno;
结果如下:

–以上是常用内连接简写,我们用标准内连接写法再写一次,注意写法上的区别
select * from
(select ename, job, hiredate, sal, deptno
from emp)t1
inner join
(select deptno, max(sal) sal from emp group by deptno)t2
on t1.deptno = t2.deptno and t1.sal = t2.sal
order by t1.deptno;
得到的结果当然也是一样的

上面很啰嗦,因为最近从工作中发现自己在连接这块还是很欠缺的,所以针对这最简单的例子进行一个回顾,有益无害吧,大佬们直接略过就好
接下来才是这篇博客我想总结的点
- 在满足第一个需求的同时,我们应该习惯性的思考一下是否还有别的方法。答案是肯定的,
–就是标题中 rank() over(partition by)、dense_rank() over(partition by)、**row_number() over(partition by)**的排序函数
SQL分别如下:
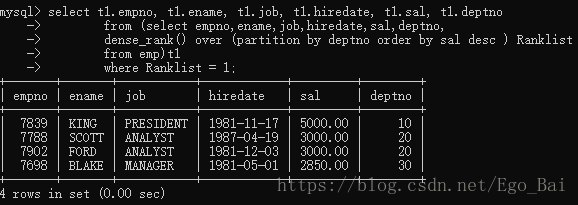
- rank() over(partition by)
select t1.empno, t1.ename, t1.job, t1.hiredate, t1.sal, t1.deptno
from (select empno, ename, job, hiredate, sal, deptno,
rank() over (partition by deptno order by sal desc ) Ranklist
from emp)t1
where Ranklist =1;
先看结果:

可见,得到的结果相同
那为什么会得出跟上面的语句一样的结果呢?
这里我们着重分析一下rank()/dense_rank() over(partition by e.deptno order by e.sal desc)这句的语法。
- over —— 在什么条件之上。
- partition by e.deptno —— 按部门编号划分(分区)。
- order by e.sal desc —— 按工资从高到低排序(使用rank()/dense_rank() 时,必须要带order by否则为非法(都说要排序了,再不指定排序的字段是怕是不合适吧?))
- rank()/dense_rank()/row_number() —— 排序
那结合起来,整个语句的意思就是:
在按部门划分的基础上,按工资从高到低对雇员进行排序,“排序”由从小到大(desc降序)的数字表示(最小值一定为1)。
以下两个排序函数的结果
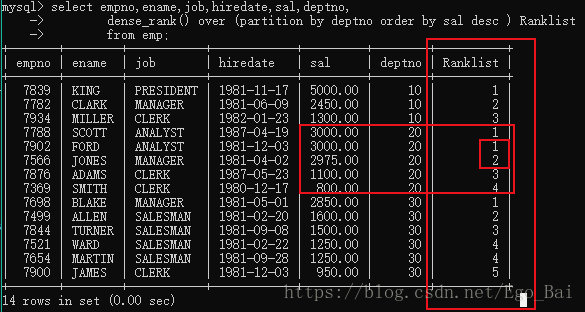
- dense_rank() over(partition by)
select t1.empno, t1.ename, t1.job, t1.hiredate, t1.sal, t1.deptno
from (select empno,ename,job,hiredate,sal,deptno,
dense_rank() over (partition by deptno order by sal desc ) Ranklist
from emp)t1
where Ranklist = 1;
结果:
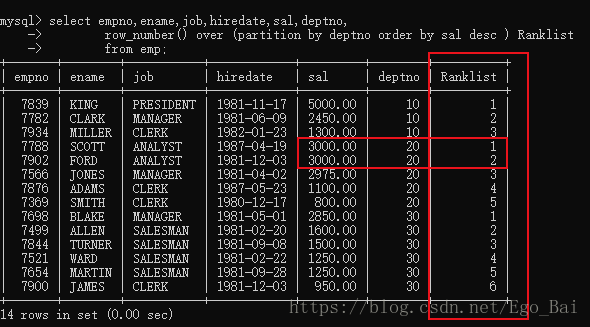
- row_number() over(partition by)
select t1.empno, t1.ename, t1.job, t1.hiredate, t1.sal, t1.deptno
from (select empno,ename,job,hiredate,sal,deptno,
row_number() over (partition by deptno order by sal desc ) Ranklist
from emp)t1
where Ranklist = 1;
结果如下:

我们可以看到,rank()、dense_rank()结果相同,而row_number()仅出线了以为sal为3000的员工scott
这时候我们会想是什么导致了以上的差别?
那我们此时关注的问题便转化为:
- row_number()、rank()与dense_rank()与之间的区别?
1.row_number()
- row_number():暂且称为去重排序,在每个分组内,为查询出来的每一行记录生成一个序号,依次排序且不会重复;
- 其基本原理是先使用over子句中的排序语句对记录进行排序,然后按照这个顺序生成序号。over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同
-
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。
-
partition by 用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。
-
注意:在使用row_number实现分页时需要特别注意一点,over子句中的order by要与Sql排序记录中的order by 保持一致,否则得到的序号可能不是连续的。
结果:
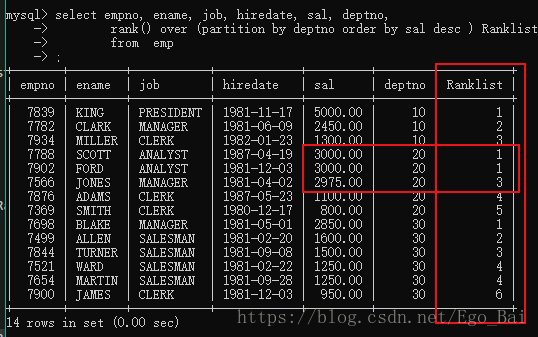
2. rank()
-
rank(): 跳跃排序,在每个分组内,如果有两个第一位时,接下来就是第三位。
他会对查询出来的记录进行排名,与row_number函数不同的是, rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号;
通过刚才例子中的子句运行结果可清楚得知:
rank()
3. dense_rank()
- dense_rank(): 连续排序,在每个分组内,如果有两个第一级时,接下来仍然是第二级。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。
dense_rank函数 出现相同排名时,将不跳过相同排名号 ,rank值 紧接 上一次的rank值。在各个分组内,rank()是跳 跃排序,有两个第一名时接下来就是第四名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
结果如下: