利用Kettle进行数据同步(下)
版权声明:
本文为博主原创文章,未经博主允许不得转载。关注公众号技术汇(ID: jishuhui_2015) 可联系到作者。
上篇介绍了基于kettle的数据同步工程的搭建,entrypoint.kjb就是整个工程执行的入口。
为了进一步降低操作成本,让整个数据同步过程更稳定、安全,需要进行更高层面的抽象,做成一个简单易用的系统。
以下是应用截图:
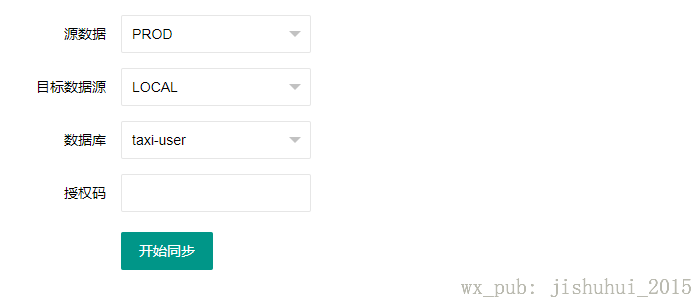
除了选择数据源和数据库之外,还加入了授权码,意味着授权范围内的用户才能使用该系统。
因为是内部使用,授权用户还没实现后台管理,直接往应用数据库里添加,所选择的数据源和数据库都是通过配置文件生成的。
文末会附上GitHub上的源码地址,有需要的读者,可以进行二次开发改造。
一、数据库设计
数据库名称:kettle,目前有两张表:
1、授权用户表。表内记录的用户即可使用数据同步系统
CREATE TABLE `authorized_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID,自增',
`user` varchar(128) NOT NULL COMMENT '用户名,全局唯一',
`token` varchar(20) NOT NULL COMMENT '用户的授权码,全局唯一',
`status` char(1) NOT NULL DEFAULT 'A' COMMENT '授权用户状态:A-已授权,R-未授权',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modify` datetime NOT NULL COMMENT '最后修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `unique_index_token` (`token`) USING BTREE,
UNIQUE KEY `unique_index_user` (`user`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='授权用户表'2、同步记录表。记录用户的数据同步操作
CREATE TABLE `sync_record` (
`sync` varchar(20) NOT NULL COMMENT '同步记录主键',
`ipv4` varchar(15) NOT NULL COMMENT 'ip地址',
`from_db` varchar(100) NOT NULL COMMENT '源数据',
`to_db` varchar(100) NOT NULL COMMENT '目标数据',
`user` varchar(128) NOT NULL COMMENT '用户名',
`token` varchar(20) NOT NULL COMMENT '用户的授权码',
`status` char(1) NOT NULL DEFAULT 'P' COMMENT '同步状态:P-正在执行,S-成功,F-失败',
`gmt_create` datetime NOT NULL COMMENT '同步创建时间',
`gmt_modify` datetime NOT NULL COMMENT '最后修改时间',
PRIMARY KEY (`sync`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='同步记录表';二、程序设计
因为系统做得比较简单实用,没有什么特别设计之处。笔者重点说三点:
1、数据源及其参数配置
在application.yml配置文件中,有这么一段配置:
env:
entry-point: kettle/entrypoint.kjb
databases:
- taxi-user
- taxi-account
- taxi-trade
- taxi-coupon
- taxi-bi
- taxi-system
- taxi-credits
- taxi-finance
- taxi-notification
- taxi-gateway
from-dbs:
- PROD
- TEST
- LOCAL
to-dbs:
- LOCAL
- TEST
db-settings:
- name: LOCAL
host: *****
port: 3306
user: *****
password: *****
- name: TEST
host: *****
port: 3306
user: *****
password: *****
- name: PROD
host: *****
port: 3306
user: *****
password: *****利用了springboot的@ConfigurationProperties的注解。
@Setter
@Getter
@ConfigurationProperties(prefix = "env")
public class EnvConfig {
private List databases;
private List fromDbs;
private List toDbs;
private List dbSettings;
public DBSetting getDBConfig(String name) {
if (StringUtils.isBlank(name)) return null;
return dbSettings.stream().filter(dbSetting -> dbSetting.getName().equalsIgnoreCase(name)).findFirst().orElse(null);
}
} 当中的DBSetting的定义如下所示:
@Setter
@Getter
@NoArgsConstructor
public class DBSetting {
private String name;
private String host;
private String port = "3306";
private String user = "root";
private String password;
public DBSetting(String host, String user, String password) {
this.host = host;
this.user = user;
this.password = password;
}
}通过客户端传来的参数,即可定位到对应的参数设置。
2、集成kettle的API
因为kettle相关的jar包放在了自己搭建的nexus私服上,所以如果使用的是maven管理jar包的话,需要在settings.xml配置文件中做一点修改:
<mirror>
<id>nexusid>
<url>公司内部的nexus的URLurl>
<mirrorOf>*,!pentaho-releasesmirrorOf>
mirror> 其中的mirrorOf节点加上了!pentaho-releases,表示排除pentaho-releases。
然后,在springboot工程中的pom.xml中指定pentaho-releases的url。
<repositories>
<repository>
<id>pentaho-releasesid>
<url>https://nexus.pentaho.org/content/groups/omni/url>
repository>
repositories>接下来是核心的对接代码,具体可以参照工程源码。
JobMeta jobMeta = getJobMeta(new ClassPathResource(envConfig.getEntryPoint()));
Job job = new Job(null, jobMeta);
//设置Variable
job.setVariable("sync", sync);
job.setVariable("TO_HOST", toDbSetting.getHost());
job.setVariable("TO_DB", form.getDb());
job.setVariable("TO_USER", toDbSetting.getUser());
job.setVariable("TO_PASSWORD", toDbSetting.getPassword());
job.setVariable("TO_PORT", toDbSetting.getPort());
job.setVariable("FROM_HOST", fromDbSetting.getHost());
job.setVariable("FROM_DB", form.getDb());
job.setVariable("FROM_USER", fromDbSetting.getUser());
job.setVariable("FROM_PASSWORD", fromDbSetting.getPassword());
job.setVariable("FROM_PORT", fromDbSetting.getPort());
job.start(); //开始执行Job
job.waitUntilFinished(); //等待Job完成3、异步执行作业
因为一个Job的执行时间可能会很长,这个主要是看数据量的多少,所以一个request的来回可能会导致TIMEOUT,所以需要改为异步的模式。
其核心的思想是:启动新的线程,客户端定时轮询执行结果。
三、总结
笔者分两篇文章介绍了如何利用kettle进行数据同步,并实现一个简易的系统,降低操作成本和出错率。
就介绍到这了,如有疑问,可以留言。
欢迎fork我的工程代码(https://github.com/liu-weihao/kettle)。
