python网络爬虫(web spider)系统化整理总结(一):入门
接触爬虫很久了,一直没有个系统的理解和整理,近来假日无事,总结一下。
-------------------------------------------以下是目录---------------------------------------------------------
一、爬虫概述及分类
二、爬虫的应用场景
三、爬虫的一般执行过程
四、爬虫技术常用的知识
五、反爬虫
-------------------------------------------以下是正文---------------------------------------------------------
一、爬虫概述及分类
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
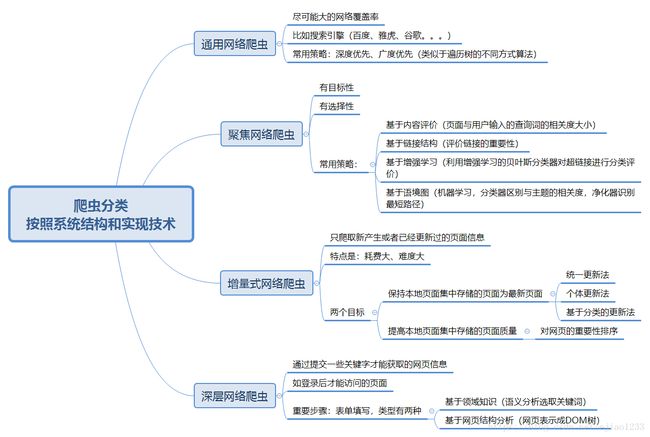
目前爬虫种类和一些基本信息如下:
二、爬虫的应用场景

三、爬虫的一般执行过程
执行过程:
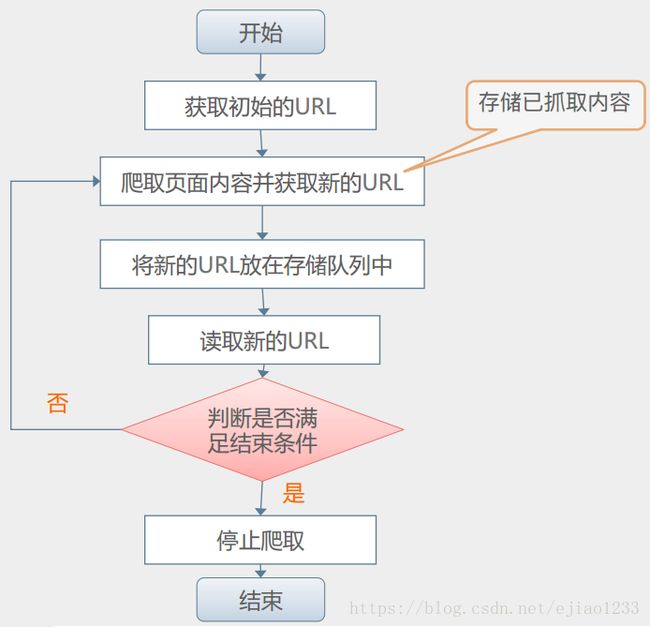
各部分运行关系流程图:

四、爬虫技术常用的知识
1、数据抓取:
1.1,涉及的过程主要是模拟浏览器向服务器发送构造好的http请求,一般是get或者post类型;
1.2,爬虫的实现,除了scrapy框架之外,python有很多可供调用的库:
urllib、requests、mechanize:用于获取URL对应的原始响应内容;
selenium、splinter通过加载浏览器驱动,获取渲染之后的响应内容,模拟程度高,但是效率低;
1.3,http协议、身份认证机制(Cookie);
1.4,网络流量分析:Chrome、Firfox+Firebug、Fiddler、Burp Suite 。
2、数据解析:
2.1,HTM结构、json数据格式、XML数据格式;
2.2,库:lxml、beautiful-soup4、re、pyquery;
2.3,从页面提取所需数据的方法:
xpath路径表达式、CSS选择器(主要用于提取结构化数据)
正则表达式(主要用于提取非结构化数据)。
3、数据库:
3.1,结构化数据库:MySQL、SQLite等;
3.2,非结构化数据库:Redis等。
4、其他:
4.1,多线程、任务调度、消息队列、分布式爬虫、图像识别、反爬虫技术等等。。。。。。
五、反爬虫
1. 基本的反爬虫手段,主要是检测请求头中的字段,比如:User-Agent、 referer等。 针对这种情
况,只要在请求中带上对应的字段即可。 所构造http请求的各个字段最好跟在浏览器中发送的完全一
样,但也不是必须。
2. 基于用户行为的反爬虫手段,主要是在后台对访问的IP(或User-Agent)进行统计,当超过某一
设定的阈值,给予封锁。 针对这种情况,可通过使用代理服务器解决,每隔几次请求,切换一下所用
代理的IP地址(或通过使用User-Agent列表解决,每次从列表里随机选择一个使用)。 这样的反爬
虫方法可能会误伤用户。
3. 希望抓取的数据是如果通过ajax请求得到的,假如通过网络分析能够找到该ajax请求,也能分析出
请求所需的具体参数,则直接模拟相应的http请求,即可从响应中得到对应的数据。 这种情况,跟普
通的请求没有什么区别。
4. 基于Java的反爬虫手段,主要是在响应数据页面之前,先返回一段带有Java代码的页面,用于验
证访问者有无Java的执行环境,以确定使用的是不是浏览器。