机器学习-mnist的第一次亲密接触
本文代码在python3.6 win7 32bit环境下测试通过。
1.什么是mnist
就好像每种程序语言都有一个helloworld的例子,mnist则是机器学习领域的helloworld,该数据集中的图片表示0~9的手写阿拉伯数字。mnist包含一个训练集(一个训练图片文件和一个训练标签文件)和一个测试集(一个测试图片文件,一个测试标签文件),其中训练集有60000个样本,测试集有10000个样本。
2.mnist数据集
mnist数据集包含4个文件,分别对应60000个训练图片,60000个训练标签,10000个测试图片,10000个测试标签。
样本数据下载传送门:http://yann.lecun.com/exdb/mnist/
train-images-idx3-ubyte.gz: 60000个训练图片 (9912422 bytes)
train-labels-idx1-ubyte.gz: 60000个训练标签 (28881 bytes)
t10k-images-idx3-ubyte.gz: 10000个测试图片 (1648877 bytes)
t10k-labels-idx1-ubyte.gz: 10000个测试标签 (4542 bytes)
从官方网站下载的数据是gz格式的压缩包,解压后可以得到原始文件。
2.2 mnist数据格式
每个mnist文件的格式如下所示:
magic number 4字节,大尾端,
size in dimension 0 4字节,大尾端
size in dimension 1 4字节,大尾端
size in dimension 2 4字节,大尾端
.....
size in dimension N 4字节,大尾端
data 1字节
dimension N的值由magic number的最后一个字节决定,等于LSB(magic number)-1,在image数据中LSB(magic number)=3,label数据中LSB(magic number)=1
data数据根据是图片还是标签有不同的值,如果是图片数据其取值范围为0~255,表示某个像素点的亮度,这里0表示最亮,255表示最暗;如果是标签数据其取值范围是0~9,表示在图片数据中对应位置的图片实际表示的数字。
图片文件数据,训练集和测试集的文件头差别只在dimension0表示的图片个数:
magic number 4字节,大尾端, 0x0000 0803
size in dimension 0 4字节,大尾端,60000或10000
size in dimension 1 4字节,大尾端,28 表示像素的row为28个
size in dimension 2 4字节,大尾端 ,28表示像素的col为28个
data 1字节,像素点值,0 ~255
标签文件数据,训练集和测试集的文件头差别只在dimension0表示的标签个数:
magic number 4字节,大尾端, 0x0000 0801
size in dimension 0 4字节,大尾端, 60000或10000
data 1字节, 0~9
具体到每个数据文件对应的格式如下:(摘自http://yann.lecun.com/exdb/mnist/)
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
TEST SET LABEL FILE (t10k-labels-idx1-ubyte):
[offset] [type] [value] [description]0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 10000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.
TEST SET IMAGE FILE (t10k-images-idx3-ubyte):
[offset] [type] [value] [description]0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 10000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
3 读取mnist文件
到目前为止只是介绍了文件的格式,还只是纸上谈兵,可能说的还是云里雾里,为了得到更感性、更直观的认识,下面介绍怎么用python将图片直观的显示出来。python有2个功能强大的库:numpy和matplotlib,可以帮助我们款速构建应用。
传送几个numpy和matplotlib的教程链接:
matplotlib:
https://matplotlib.org/users/pyplot_tutorial.html ,
https://www.jianshu.com/p/aa4150cf6c7f?winzoom=1
numpy:
https://docs.scipy.org/doc/numpy-dev/user/quickstart.html
链接的内容比较全面,对这2个库的熟悉也不必面面俱到,有了初步了解就可以对后文的代码一边学习一边使用。这种方法对于学习其他的新技术也是适用的,先了解理论、熟悉部分基础内容,然后设计实验快速上手应用,会有事半功倍的效果。
3.1读文件头
import os
from matplotlib import pyplot as plt
import numpy as np
#图片的大小
IMAGE_ROW = 28
IMAGE_COL = 28
IMAGE_SIZE = 28*28
'''
功能:
获取文件头dimension数据
入参:
filename, 文件名称
返回:
返回文件头的dimension数据
'''
def read_head(filename):
print('读取文件头:',os.path.basename(filename))
dimension = []
with open(filename,'rb') as pf:
#获取magic number
data = pf.read(4)#读出第1个4字节
magic_num = int.from_bytes(data,byteorder='big')#bytes数据大尾端模式转换为int型
print('magcinum: ', hex(magic_num))
#获取dimension的长度,由magic number的最后一个字节确定
dimension_cnt = magic_num & 0xff
#获取dimension数据,
#dimension[0]表示图片的个数,如果是3维数据,dimension[1][2]分别表示其行/列数值
for i in range(dimension_cnt):
data = pf.read(4)
dms = int.from_bytes(data,byteorder='big')
print('dimension %d: %d'%(i,dms))
dimension.append(dms)
print(dimension)
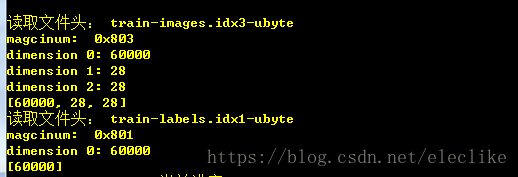
return dimension 这里以读取训练样本的图片和标签文件为例,magicnum的最低字节为3,表示dimension的个数为3,dimension0表示获取到的图片数量,都为60000,dimension1和dimension2表示每张图片的大小,为28*28:
3.2 读某一张图片数据
这里先用控制台方式打印数据显示一张图片,在这段程序中如果图片的某个字节数据中大于10,则表示为1 ,小于10则表示为0,,这样print()打印出来的数据显示时的宽度都是单个字符宽度,可直观地观察读出的数值是多少,也相当于做了个简单的滤波:
'''
功能:
文件头的长度为4字节的magic num+dimension的个数*4
入参:
dimension, read_head()返回的维度
返回:
文件头的长度
'''
def get_head_length(dimension):
return 4*len(dimension)+4
'''
功能:
读出文件中的第n张图片,mnist单张图片的数据为28*28个字节
入参:
filename, 样本图片的文件名称
head_len, 文件头长度
offset, 偏移位置或者图片的索引号,从第offset张图片开始的位置
返回:
image,
'''
def read_image(filename,head_len,offset):
image = np.zeros((IMAGE_ROW,IMAGE_COL),dtype=np.uint8)#创建一个28x28的array,数据类型为uint8
with open(filename,'rb') as pf:
#magic_num的长度为4,dimension_cnt单个长度为4,前面的number个长度为28*28*offset
pf.seek(head_len+IMAGE_SIZE*offset)
for row in range(IMAGE_ROW):#处理28行数据,
for col in range(IMAGE_COL):#处理28列数据
data = pf.read(1)#单个字节读出数据
pix = int.from_bytes(data,byteorder='big')#由byte转换为int类型,
#简单滤波,如果该位置的数值大于指定值,则表示该像素为1.因为array已经初始化为0了,如果小于该指定值,不需要变化
if pix >10:image[row][col] = 1
print(image)
return image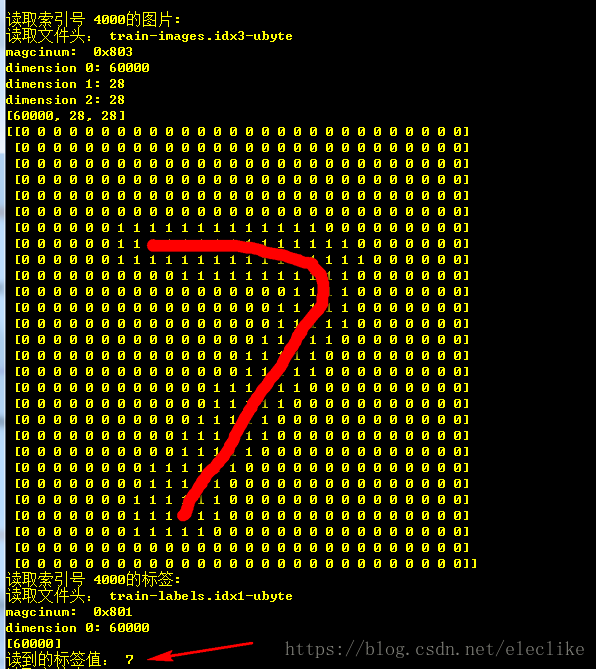
3.3 读标签数据
'''
功能:
读出文件中的第n张图片对应的label
入参:
filename, 样本标签的文件名称
head_len, 文件头长度
offset, 偏移位置或者标签的索引号,从第offset个标签开始的位置
返回:
label,
'''
def read_label(filename,head_len,offset):
label = None
with open(filename,'rb') as pf:
#pf 指向label的第number个数据,magic_num的长度为4,dimension_cnt单个长度为4
pf.seek(head_len+offset)
data = pf.read(1)
label = int.from_bytes(data,byteorder='big')#由byte转换为int类型,
print('读到的标签值:',label)
return label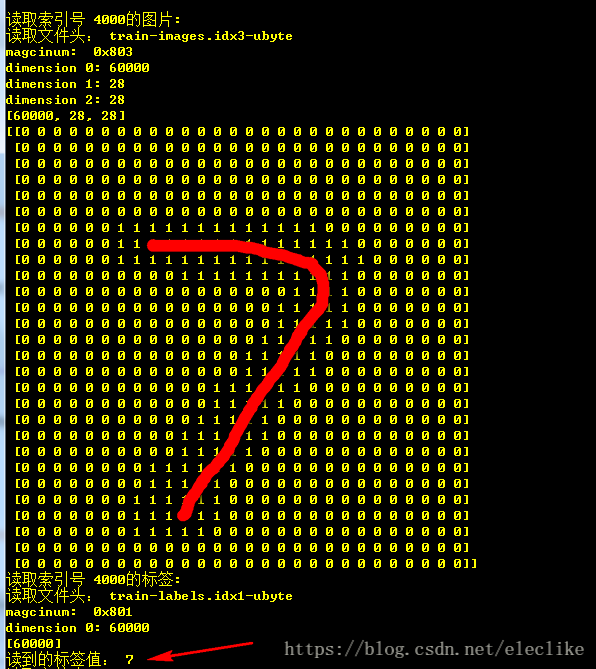
3.4 转换为numpy数据并显示图片
get_sample_count()函数用来获取样本数量,用于后面读取文件时判断图片文件和标签文件的样本数量是否一致,如果保证了都使用训练集或者测试集,这个判断可以不需要:
'''
功能:
获取样本数量
入参:
dimension, read_head()返回的维度
返回:
样本数量
'''
def get_sample_count(dimension):
return dimension[0]read_image_vector()用来获取多张图片的数据,将一张图片数据先转换成一维向量,再将多张图片合成转换成一个numpy 向量:
'''
功能:
读出文件中的第offset张图片开始的amount张图片,mnist单张图片的数据为28*28个字节
入参:
filename, 样本图片的文件名称
head_len, 文件头长度
offset, 偏移位置,从第offset张图片开始的位置
amount, 要返回的图像数量
返回:
image_list,
'''
def read_image_vector(filename,head_len,offset,amount):
image_mat=np.zeros((amount,IMAGE_SIZE),dtype=np.uint8)
with open(filename,'rb') as pf:
#magic_num的长度为4,dimension_cnt单个长度为4,前面的number个长度为28*28*offset
pf.seek(head_len+IMAGE_SIZE*offset)
for ind in range(amount):
image = np.zeros((1,IMAGE_SIZE),dtype=np.uint8)#创建一个1,28x28的array,数据类型为uint8
for row in range(IMAGE_SIZE):#处理28行数据,
data = pf.read(1)#单个读出数据
pix = int.from_bytes(data,byteorder='big')#由byte转换为int类型,
#简单滤波,如果该位置的数值大于指定值,则表示该像素为1.因为array已经初始化为0了,如果小于该指定值,不需要变化
if pix >10:image[0][row] = 1
image_mat[ind,:]=image
print('read_image_vector:当前进度%0.2f%%'%(ind*100.0/amount),end='\r')
print()
#print(image)
return image_mat read_label_vector()获取标签数据,标签数据可以用一个list表示:
'''
功能:
读出文件中的第n张图片开始的amout个的label
入参:
filename, 样本标签的文件名称
head_len, 文件头长度
offset, 偏移位置,从第offset张图片开始的位置
amount, 要返回的图像数量
返回:
label_list,标签list
'''
def read_label_vector(filename,head_len,offset,amount):
label_list=[]
with open(filename,'rb') as pf:
#pf 指向label的第number个数据,magic_num的长度为4,dimension_cnt单个长度为4
pf.seek(head_len+offset)
for ind in range(amount):
data = pf.read(1)
label = int.from_bytes(data,byteorder='big')#由byte转换为int类型,
label_list.append(label)
print('read_label_vector:当前进度%0.2f%%'%(ind*100.0/amount),end='\r')
print()
return label_listread_image_label_vector()同时读取image和label文件,并返回图片数据的numpyt向量和标签数据的list:
'''
从文件中读offset起始位置开始读出amout个image和label。
'''
def read_image_label_vector(image_file,label_file,offset,amount):
image_dim = read_head(image_file)
label_dim = read_head(label_file)
#判断样本中的image和label是否一致
image_amount = get_sample_count(image_dim)
label_amount = get_sample_count(label_dim)
if image_amount != label_amount:
print('Error:训练集image和label数量不相等')
return None
if offset+amount > image_amount:
print('Error:请求的数据超出样本数量')
return None
#获取样本image和label的头文件长度
image_head_len = get_head_length(image_dim)
label_head_len = get_head_length(label_dim)
#得到image和label的向量
image_mat = read_image_vector(image_file,image_head_len,offset,amount)
label_list = read_label_vector(label_file,label_head_len,offset,amount)
return image_mat,label_list这里是执行的主程序,从训练集图片偏移=4000处开始读取并显示10张图片
if __name__ == '__main__':
print('\n\n')
train_image_file = '..\\data\\mnist\\train-images.idx3-ubyte'
train_label_file = '..\\data\\mnist\\train-labels.idx1-ubyte'
offset = 4000
number = 10
image_mat, label_list = read_image_label_vector(train_image_file,train_label_file,offset,number)
for index in range(number):
#画图,imshow可以直接读array数据:
image = np.zeros((IMAGE_ROW,IMAGE_COL),dtype=np.uint8)
for row in range(IMAGE_ROW):
for col in range(IMAGE_COL):
image[row][col] = image_mat[index][row*IMAGE_ROW+col]
#print(image_list[index])
label = label_list[index]
print('LABEL=',label)
print(image)
plt.imshow(image)
plt.title('picture no=%d,label=%d'%(offset+index,label))#在图片标题栏显示读到的标签数据
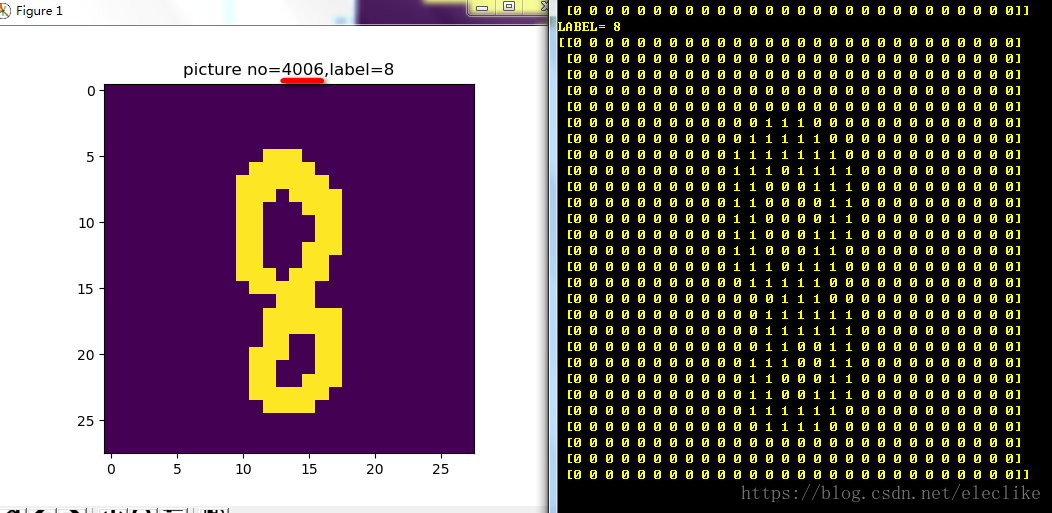
plt.show()下图是读取索引号=40000的图片:

下图是索引号=40006的图片:
4 后话
通过本文对mnist图片和标签文件格式的分析,并通过python读取文件、显示图片,对mnist数据格式有了初步的认识。
下一篇文章(https://blog.csdn.net/eleclike/article/details/79994846)将介绍如何利用kNN算法识别手写字体。