摘录自:
[Learning Multi-Domain Convolutional Neural Networks for Visual Tracking]
Author:Hyeonseob Nam, Bohyung Ham
参考:https://zhuanlan.zhihu.com/p/25312850
- 跟踪的目标虽然各式各样但也有值得网络去学习的共性(such as robustness to illumination changes, motion blur, scale variations, etc. ),所以可以使用视频跟踪数据来训练CNN
- 同一目标有时被当作背景有时被当作前景,每个序列的目标存在较大差异,再加上有遮挡和形变
- 现有的很多训练好的网络主要针对的任务比如目标检测、分类、分割等的网络很大,因为他们要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景。而且目标一般都相对比较小,那么其实不需要这么大的网络,会增加计算负担。
Multi-domain representation learning(提前用CNN学共性)
with
online visual tracking(在线学特性)
Multi-domain representation learning part
separate domain-independent information from domain-specific one and learn generic feature representations for visual tracking.
MDNet的结构

- Input: 网络的输入是107x107的Bounding box,设置为这个尺寸是为了在卷积层conv3能够得到3x3的feature map。
This input size is designed to obtain 3×3 feature maps in conv3:
107 = 75 (receptive field) + 2 × 16 (stride). - Convolutional layers: 网络的卷积层conv1-conv3来自于VGG-M [1]网络,只是输入的大小做了改变。
- Fully connected layers: 接下来的两个全连接层fc4,fc5各有512个输出单元(fc4,fc5 combined with ReLUs and Dropouts)。fc6是一个二分类层(Domain-specific layers,binary classification layer with softmax crossentropy loss),一共有K个,对应K个Branches(即K个不同的视频),每次训练的时候只有对应该视频的fc6被使用,前面的层都是共享的。
训练过程
K个视频,N次循环
mini-batch:某一视频中随机采8帧图片,在这8帧图片上随机采32个正样本和96个负样本——>128个框
每次循环K次迭代(分别用K个视频来取mini-batch)
SGD
每个视频会对应自己的fc6层
通过这样的训练来学得各个视频中目标的共性
generic target representation in shared layer
补充:integrate hard negative mining step into minibatch selection
就是让负样本越来越难分,从而使得网络的判别能力越来越强。
- hard negative mining
就是要挑负样本里面最难分的哪些即positive scores最高的那些(特别是false positive)
each iteration of learning procedure
a minibatch->Mp个positives,Mn个hard negatives
Mn个hard negatives是怎么来的呢:
testing M(>>Mn)negatives选分数最高的Mn个
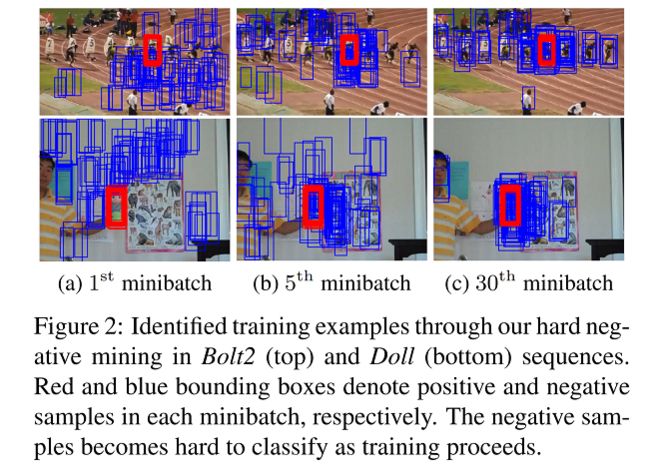
This approach examines a predefined number of
samples and identifies critical negative examples effectively
without explicitly running a detector to extract false positives as in the standard hard negative mining techniques.
Only the weights in the fully connected layers w4:6 are updated online whereas the ones in the convolutional layers w1:3 are fixed throughout tracking; this strategy is beneficial to not only computational efficiency but also avoiding overfitting by preserving domain-independent
训练好的网络在做test的时候,会新建一个fc6层,在线fine-tune fc4-fc6层,卷积层保持不变。
online visual tracking
输入:
每次新来一帧图片,以上一帧的目标位置为中心,用多维高斯分布(宽,高,尺度三个维度)的形式进行采样256个candidates,将他们大小统一为107x107后,分别作为网络的输入进行计算。输出:
表示BoundingBox对应前景与背景的概率的二维向量
更新策略
The online update is conducted to model long-term and short-term appearance variations of a target for robustness and adaptiveness, respectively.(更新是为了建模目标的长期或短期的变化)
采用long-term和short-term两种更新方式。
在跟踪的过程中,会保存历史跟踪到的目标作为正样本(得分高于一个阈值)
long-term对应历史的100个样本(超过100个抛弃最早的),固定时间间隔做一次网络的更新(程序中设置为每8帧更新一次)
short-term对应20个(超过20个抛弃最早的),在目标得分低于0.5进行更新。负样本都是用short-term的方式收集的。
Bounding Box Regression
Due to the high-level abstraction of CNN-based features and our data augmentation strategy which samples multiple positive examples around the target (which will be described in more detail in the next subsection), our network sometimes fails to find tight bounding boxes enclosing the target.
最后得到的candidate不是直接作为目标,还要做一步bounding box regression。做法与R-CNN一样。
Given the first frame of a test sequence, we train a simple linear regression model to predict the precise target location using conv3 features of the samples near the target location. In the subsequent frames, we adjust the target locations estimated from Eq. (1) using
the regression model if the estimated targets are reliable
The bounding box regressor is trained only in the first frame since it is time consuming for online update and incremental learning of the regression model may not be very helpful considering its risk.
总结一下MDNet效果好的原因:
- 用了CNN特征,并且是专门为了tracking设计的网络,用tracking的数据集做了训练
- 有做在线的微调fine-tune,这一点虽然使得速度慢,但是对结果很重要
- Candidates的采样同时也考虑到了尺度,使得对尺度变化的视频也相对鲁棒
- Hard negative mining和bounding box regression这两个策略的使用,使得结果更加精确
采用比较浅层的网络的原因
1,visual tracking aims to distinguish only two classes, target and background, which requires much less model complexity
2,a deep CNN is less effective for precise target localization since the spatial information tends to be diluted as a network goes deeper(越深越抽象的意思?)
3,since targets in visual tracking are typically small, it is desirable
to make input size small, which reduces the depth of the network naturally.
4, a smaller network is obviously more efficient in visual tracking problem, where training and testing are performed online.
Online Tracking Algorithm



Implementation Detials
- convolutional layers: initialized by VGG-M network(pretrained on ImageNet)
- Network learning For multi-domain learning with K training sequences: train the network for 100K iterations with learning rates 0.0001 for convolutional layers2 and 0.001 for fully connected layers.
- At the initial frame of a test sequence: train the fully connected layers for 30 iterations with learning rate 0.0001 for fc4-5 and 0.001
for fc6. - online update: train the fully connected layers for 10 iterations with the learning rate three times larger than that in the initial frame for fast adaptation.
- momentum: 0.9
- weight decay: 0.0005
- mini-batch consists: M+(= 32) positives and Mh−(= 96) hard negatives selected out of M−(=1024) negative examples.
- offline multi-domain learning: collect 50 positive and 200 negative samples from every frame, where positive and negative examples have ≥ 0.7 and ≤ 0.5 IoU overlap ratios with ground-truth bounding boxes, respectively.
- online learning, we collect St+(=50) positive and St-(= 200) negative samples with ≥ 0.7 and ≤ 0.3 IoU overlap ratios with the estimated target bounding boxes, respectively(except that S1+ = 500 and S1-= 5000.
- bounding-box regression: use 1000 training examples with the same parameters as [13].
- For offline training of MDNet, we use 58 training sequences collected from VOT2013 [26], VOT2014 [25] and VOT2015 [1], excluding the videos included in OTB100.
Experiment
-
在OTB50和OTB100上和其他分类器进行比较
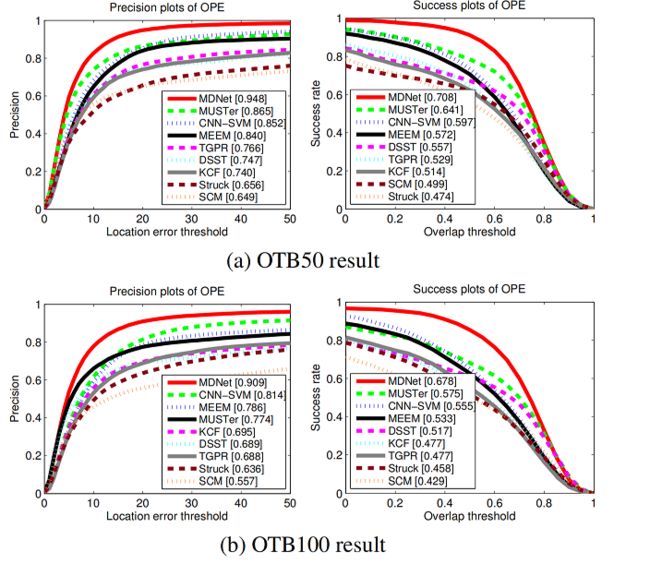
The exceptional scores at mild thresholds means our tracker hardly misses targets while the competitive scores at strict thresholds implies that our algorithm also finds tight bounding boxes to targets.
-
应对fast motion,background clutter,low resolution,occlusion,illumination variation,plane rotation,out of view, scale variation的效果也很好
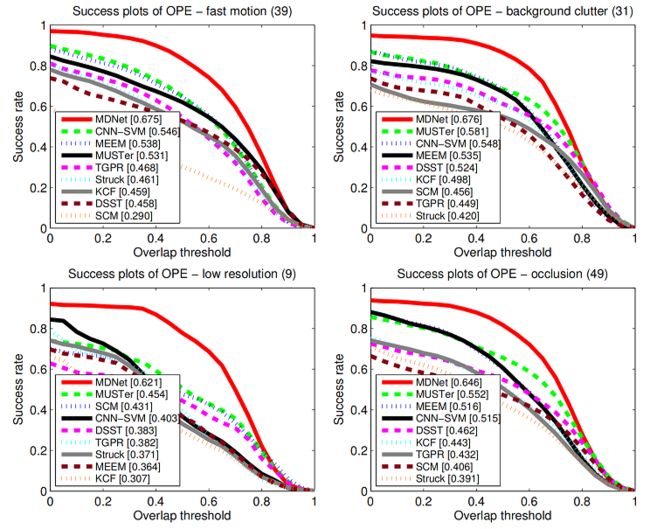

In particular, our tracker successfully track targets in low resolution while all the trackers based on low-level features are not successful in the challenge.
-
与Single-domain net,without bounding box regression,with bounding box regression and hard negative samples进行比较,证明这些component对性能都是由效果的

-
Figure 7 shows a few failure cases of our algorithm; slight target
appearance change causes a drift problem in Coupon sequence, and dramatic appearance change makes our tracker miss the target completely in Jump sequence.

Furthermore, MDNet works well with imprecise re-initializations as shown in the region noise experiment results, which implies that it can be effectively combined with a re-detection module and achieve long-term tracking.