对于scrapy我们前面已经介绍了简单的应用,今天我们用一个完整的例子,爬取豆瓣电影TOP250来做一个小的练习,把scrapy阶段做一个总结。
1 环境配置
语言:Python 3.6.1
IDE: Pycharm
浏览器:firefox
爬虫框架:Scrapy 1.5.0
操作系统:Windows 10 家庭中文版2 爬取前分析
2.1 需要保存的数据
首先确定我们要获取的内容,在items中定义字段,来将非结构化数据生成结构化数据,获取的内容主要包括:排名、电影名称、得分、评论人数。
如下图: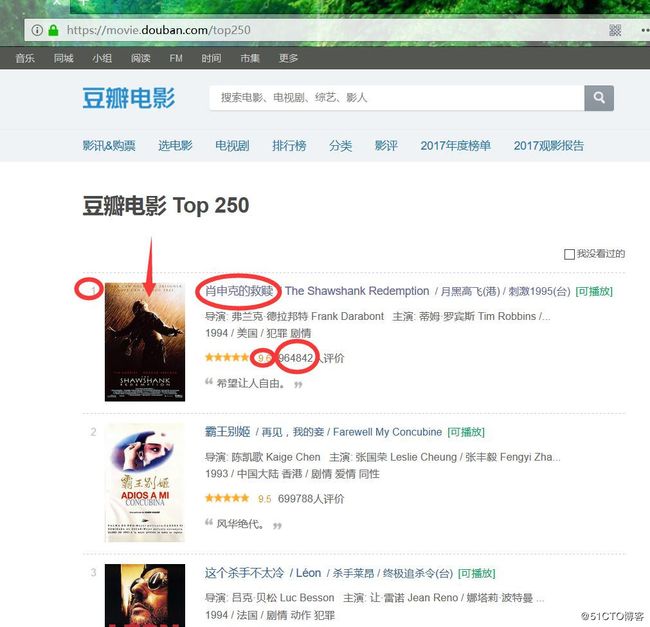
在scrapy中需要定义items.py来配置我们的字段:
import scrapy
class SpItem(scrapy.Item):
"""
定义item字段
"""
# 排名
ranking = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 评分
score = scrapy.Field()
# 评论人数
people_num = scrapy.Field()
2.2 编写爬虫spider
基本的框架如下:
import scrapy
from sp.items import SpItem
class DoubanSpider(scrapy.Spider):
"""
爬取豆瓣电影TOP250类,继承了scrapy.Spider类
"""
# 定义spider名称,必须要有而且是唯一值
name = 'douban'
# 初始url,可以使用start_requests(self)也可以直接使用start_urls方式,而且区别是start_requests(self)可以更灵活,添加更多内容,如header等。
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
"""
解析response中的字段,传送到items中
"""
# 实例化item,用来添加获取的内容
item = SpItem()
pass下面我们就看一看我们需要解析的内容,打开firefox浏览器,开发者模式(F12),通过元素选择箭头选择我们要获取的内容,发现我们要获取的当前页面的信息都在一个class为grid_view的ol标签中,如下图: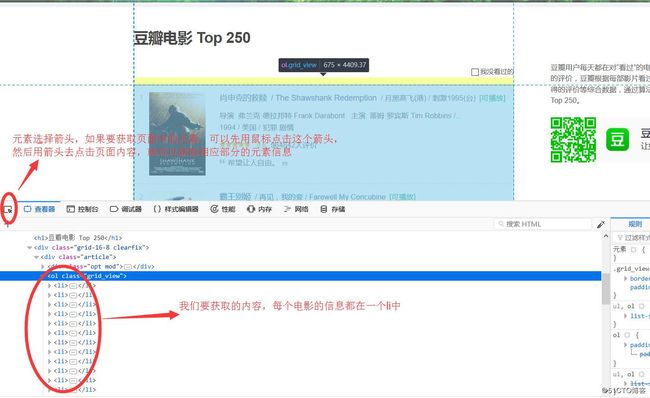
2.3 使用scrapy shell获取内容
因为我们无法一次就能准确获取我们的内容,所以建议还是先用scrapy shell来获取内容再执行,执行结果如下:
scrapy shell "https://movie.douban.com/top250"执行结果如下: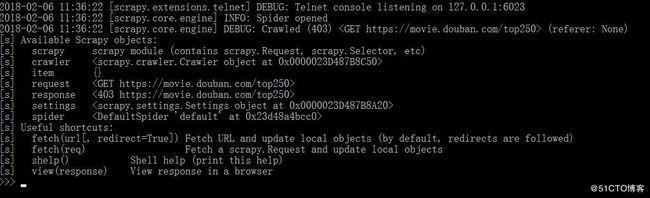
小伙伴们有没有发现问题,没错看到403了,这是什么原因,难道是因为没有添加header,好的那我就加上header试试,scrapy shell 添加header命令运行如下:
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0" "https://movie.douban.com/top250"使用-s参数更多参数可以查看官方文档(scrapy shell),传入USER_AGENT头信息,头信息我们哪里获取呢?见下图: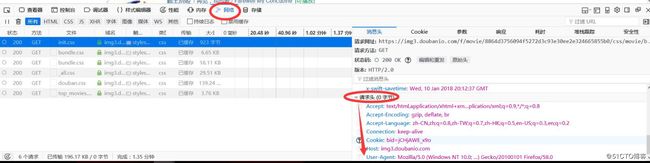
让我们看一下结果: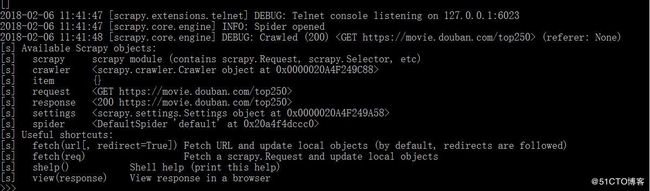
ok,成功了,那我们就获取我们想要的内容吧。
通过使用开发者工具和scrapy shell,我们先获取ol下的所有li标签,然后循环每个标签提取我们需要的内容,分析步骤略了,大家多联系xpath和css使用方法即可。最终结果如下:
# 所有电影的标签,每个电影的信息在一个li中,我们先获取所有的li标签
movies = response.css("ol.grid_view li")
# 循环每一个li标签,也就是每一个电影的信息
for movie in movies:
# 排名
item['ranking'] = movie.css("div.pic em::text").extract_first()
# 电影名字
item['movie_name'] = movie.css("div.hd a span:first-child::text").extract_first()
# 得分
item['score'] = movie.css("div.star span.rating_num::text").extract_first()
# 评论人数
item['people_num'] = movie.css("div.star span:last-child::text").re("\d+")[0]
完善我们的spider代码(douban_spider.py)如下:
# -*- coding: utf-8 -*-
import scrapy
from sp.items import SpItem
class DoubanSpider(scrapy.Spider):
"""
爬取豆瓣电影TOP250
"""
name = 'douban'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
"""
解析response中的字段,传送到items中
"""
item = SpItem()
movies = response.css("ol.grid_view li")
for movie in movies:
# 排名
item['ranking'] = movie.css("div.pic em::text").extract_first()
# 电影名字
item['movie_name'] = movie.css("div.hd a span:first-child::text").extract_first()
# 得分
item['score'] = movie.css("div.star span.rating_num::text").extract_first()
# 评论人数
item['people_num'] = movie.css("div.star span:last-child::text").re("\d+")[0]
yield item2.4 运行spider
我的spider里面没有添加头,我在settings.py中增加了如下参数:
这里添加也是可以的 。
运行spider输出到csv文件命令如下:
scrapy crawl douban -o douban.csv执行结果如下: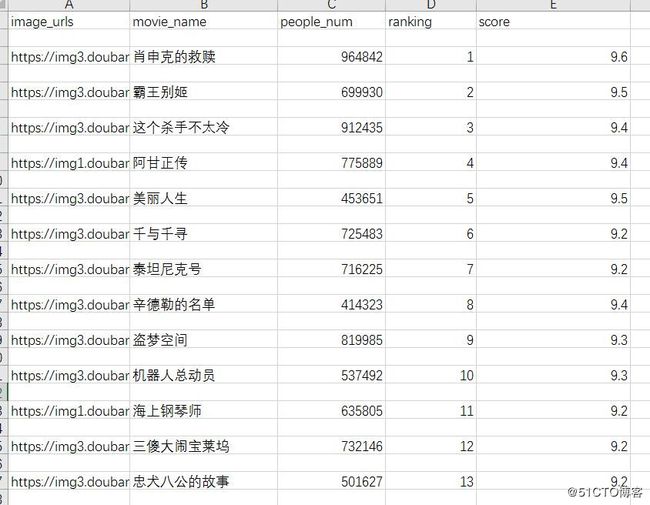
这里有两个地方要注意:
1.如果直接用excel打开这个csv文件的话,会出现乱码,需要用类似notepadd++工具打开后选择编码--转码为utf-8格式,然后再用excel打开后就没有这个问题了。
2.我们看输出结果是有空行的,这个需要修改scrapy的源码内容,在pycharm中连续点击两下shift键,弹出搜索框后搜索exporters.py,如下图: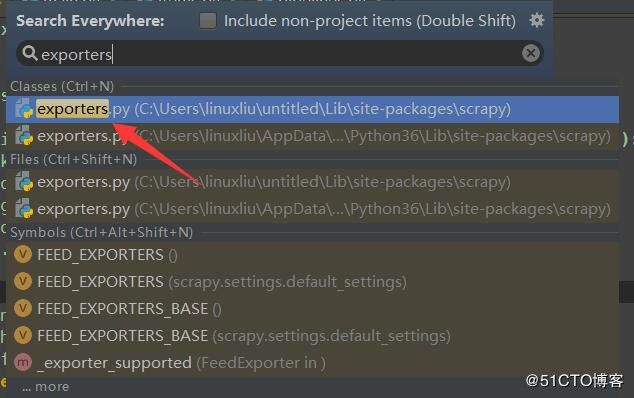
找到下面内容,添加一行newline=' ',如下图: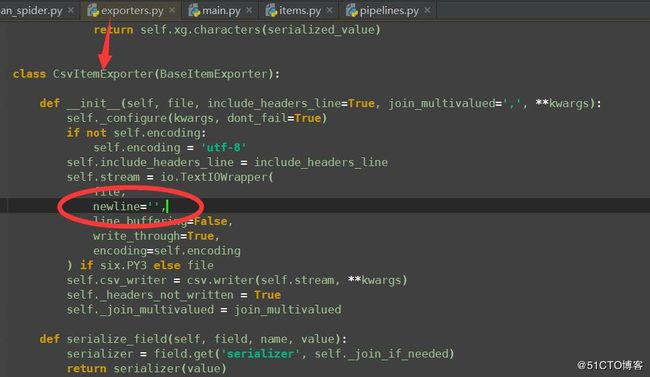
我们再次执行操作后输出结果如下: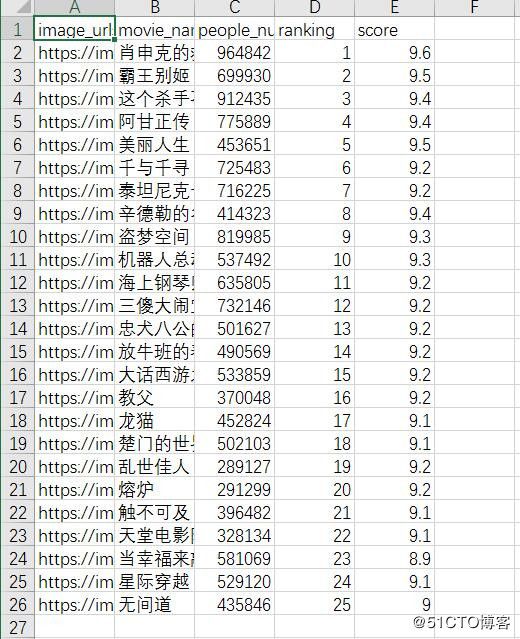
是不是很神奇!
2.5 爬取所有页面内容
首先还是分析页面,找到最下面页面内容部分,用浏览器工具找到后页所对应的标签,里面的href内容就是我们要获取的内容,如下: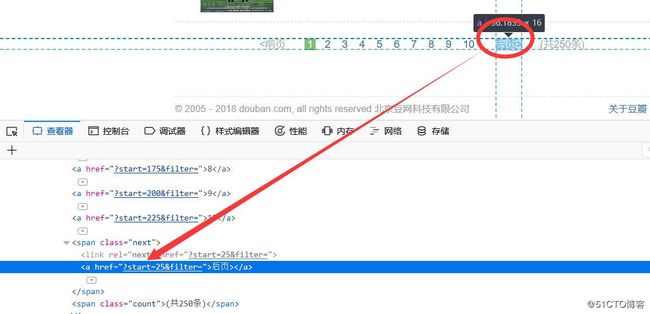
注意这里获取的是相对链接,不是绝对链接,有一下两种方式调用相对连接:
# scrapy 1.4版本以前的版本使用此段代码
next_page = response.css("span.next a::attr(href)").extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
# scrapy 1.4版本以后加入了follow方法,可以使用下面代码
# next_page = response.css("span.next a::attr(href)").extract_first()
# if next_page is not None:
# yield response.follow(next_page, callback=self.parse)我们的完整spider代码如下:
# -*- coding: utf-8 -*-
import scrapy
from sp.items import SpItem
class DoubanSpider(scrapy.Spider):
"""
爬取豆瓣电影TOP250
"""
name = 'douban'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
"""
解析response中的字段,传送到items中
"""
item = SpItem()
movies = response.css("ol.grid_view li")
for movie in movies:
# 排名
item['ranking'] = movie.css("div.pic em::text").extract_first()
# 电影名字
item['movie_name'] = movie.css("div.hd a span:first-child::text").extract_first()
# 得分
item['score'] = movie.css("div.star span.rating_num::text").extract_first()
# 评论人数
item['people_num'] = movie.css("div.star span:last-child::text").re("\d+")[0]
yield item
# scrapy 1.4版本以前的版本使用此段代码
next_page = response.css("span.next a::attr(href)").extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
# scrapy 1.4版本以后加入了follow方法,可以使用下面代码
# next_page = response.css("span.next a::attr(href)").extract_first()
# if next_page is not None:
# yield response.follow(next_page, callback=self.parse)
输出结果如下: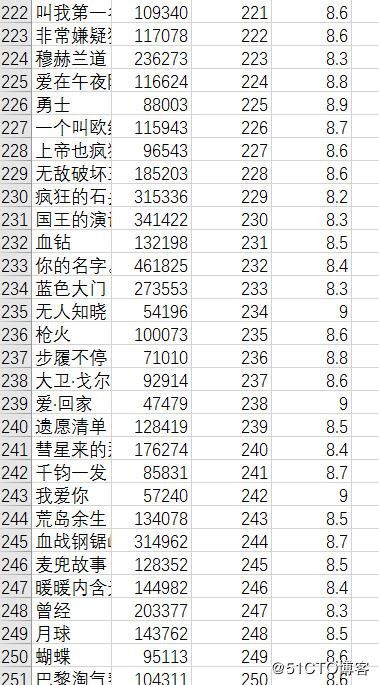
除去标题,正好250。