什么是 ELK
官方网址:https://www.elastic.co/cn/
-
Elasticsearch
- Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
-
Logstash
- Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
-
Kibana
- Kibana 让您能够可视化 Elasticsearch 中的数据并操作 Elastic Stack。
Elasticsearch
几个特性:
- 查询:Elasticsearch 允许执行和合并多种类型的搜索 — 结构化、非结构化、地理位置、度量指标 — 搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。
- 分析:找到与查询最匹配的十个文档是一回事。但是如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。
- 速度:我们通过有限状态机实现了用于全文检索的倒排索引,实现了用于存储数值数据和位置数据的 BKD 树, 以及用于分析的列存储。
而且由于每个数据都被编入了索引,因此您再也不用因为某些数据没有索引而烦心。您可以用快到令人发指的速度使用和访问您的所有数据。 - 可扩展性:无论 Elasticsearch 是在一个节点上运行,还是在一个包含 300 节点的集群上运行,您都能够以相同的方式与 Elasticsearch 进行通信。
它能够水平扩展,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。 - 弹性:硬件故障。网络瞬断。Elasticsearch 为您检测这些故障并确保您的集群(数据)安全和可用。
- 灵活性:数字、文本、地理位置、结构化、非结构化。所有的数据类型都欢迎。
应用搜索、安全分析或是日志分析只是全球众多公司利用 Elasticsearch 解决各种挑战的冰山一角。 - 客户端库:Elasticsearch 使用的是标准的 RESTful API 和 JSON。此外,我们还构建和维护了很多其他语言的客户端,例如 Java, Python, .NET, 和 PHP。
- X-PACK:X-Pack 可以很轻松的安装在 Elasticsearch 从而带来为您带来增强的使用体验,提供的特性包括 security、monitoring、alerting、reporting、graph 关联分析和 machine learning。
Mac 上安装与操作 Elasticsearch
使用 Homebrew 安装:
brew install elasticsearch
产生的几个目录:
- Data 数据:
/usr/local/var/lib/elasticsearch/elasticsearch_xianch/ - Logs 日志:
/usr/local/var/log/elasticsearch/elasticsearch_xianch.log - Plugins 插件:
/usr/local/var/elasticsearch/plugins/ - Config 配置:
/usr/local/etc/elasticsearch/ - 安装目录:
/usr/local/Cellar/elasticsearch/6.2.4
查看 Elasticsearch 版本:
elasticsearch --version
Version: 6.2.4, Build: ccec39f/2018-04-12T20:37:28.497551Z, JVM: 1.8.0_172
启动和停止 Elasticsearch:
brew services start elasticsearch
brew services stop elasticsearch
启动后可以访问 http://localhost:9200/ 看到 Elasticsearch 的信息,返回一段 JSON:
{
"name" : "XUgy0CH",
"cluster_name" : "elasticsearch_xianch",
"cluster_uuid" : "mjJZ5tJHTAW0ef2FsnLfqw",
"version" : {
"number" : "6.2.4",
"build_hash" : "ccec39f",
"build_date" : "2018-04-12T20:37:28.497551Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
Logstash
几个特性:
- 输入:数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
- 过滤器:Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响。
- 输出:尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。 - 即插即用:Logstash 模块通过流行的数据源(如 ArcSight 和 Netflow )呈现瞬间可视化的体验。通过立即部署摄入管道和复杂的仪表板,您的数据探索将以几分钟而不是几天的时间开始。
- 可扩展:Logstash 采用可插拔框架,拥有 200 多个插件。您可以将不同的输入选择、过滤器和输出选择混合搭配、精心安排,让它们在管道中和谐地运行。
- 可靠性 & 安全性:假如 Logstash 节点发生故障,Logstash 会通过持久化队列来保证运行中的事件至少一次被送达(at-least-once delivery)。那些未被正常处理的消息会被送往死信队列(dead letter queue)以便做进一步处理。由于具备了这种吸收吞吐量的能力,现在您无需采用额外的队列层,Logstash 就能平稳度过高峰期。
- 监控:Logstash 管道通常服务于多种用途,会变得非常复杂,因此充分了解管道性能、可用性和瓶颈异常重要。借助 X-Pack monitoring 功能,您可以轻松观察和研究处于活动状态的 Logstash 节点或整个部署。
- 管理 & 治理:借助 Pipeline 管理图形界面来管理 Logstash 的部署,这让您数据加工管道的治理变得轻而易举。
Mac 上安装与操作 Logstash
使用 Homebrew 安装:
brew install logstash
产生的几个目录:
- 安装目录:
/usr/local/Cellar/logstash/6.2.4
查看 Logstash 版本:
logstash --version
logstash 6.2.4
创建一个 Logstash 配置文件 logstash.conf:
语法参考:https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
input {
tcp {
mode => "server"
host => "127.0.0.1"
port => 9250
}
}
filter {
}
output {
elasticsearch {
action => "index"
hosts => "127.0.0.1:9200"
index => "testing-log"
}
}
启动一个 Logstash 实例,其实相当于定义了一个数据处理的管道,从 9250 端口接受数据,并发送存储到上面创建的 Elasticsearch 示例:
logstash -f logstash.conf
Kibana
几个特性:
- 可视化与探索
- 分享 KIBANA <3
- 统一的 UI 管理界面
- 开发工具
Mac 上安装与操作 Kibana
请确保 Kibana 的版本与 Elasticsearch 的版本一致。否则启动 Kibana 之后会出现错误提示:
先下载到本地并解压缩:
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-darwin-x86_64.tar.gz
tar zxvf kibana-6.2.4-darwin-x86_64.tar.gz
编辑 /config/kibana.yml,确保:
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://localhost:9200"
通过 ./bin/kibana 启动 Kibana:

随后可以通过 http://localhost:5601/ 访问 Kibana 页面:

导入示例数据到 Elasticsearch
三个数据集:
- 威廉·莎士比亚全集,解析成合适的字段。点击这里下载这个数据集: shakespeare.json.
- 一组虚构的账户与随机生成的数据。点击这里下载这个数据集: accounts.zip.
- 一组随机生成的日志文件。点击这里下载这个数据集: logs.jsonl.gz.
具体过程参考:
- 中文 https://www.elastic.co/guide/cn/kibana/current/tutorial-load-dataset.html
- 英文 https://www.elastic.co/guide/en/kibana/current/tutorial-load-dataset.html
几个注意的点:
- 在莎士比亚和日志数据集加载之前,我们需要为字段设置 映射 Mapping。 映射把索引中的文档按逻辑分组并指定了字段的属性,比如字段的可搜索性或者该字段是否是 tokenized ,或分解成单独的单词。
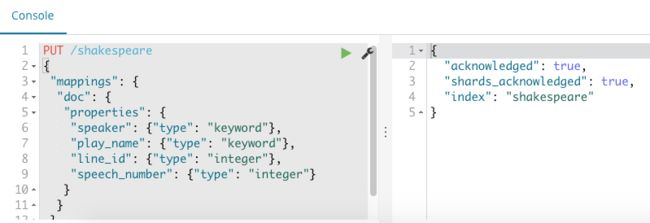 通过 Kibana UI 的 Dev Tools 创建映射 Mapping
通过 Kibana UI 的 Dev Tools 创建映射 Mapping - 可以通过
GET /_cat/indices?v查看是否导入成功:
 可以通过 GET /_cat/indices?v 查看是否导入成功
可以通过 GET /_cat/indices?v 查看是否导入成功
在 Elasticsearch 中创建索引模式 Index Patterns
具体过程参考:
- 中文 https://www.elastic.co/guide/cn/kibana/current/tutorial-define-index.html
- 英文 https://www.elastic.co/guide/en/kibana/current/tutorial-define-index.html
导入数据后,我们再次访问 Kibana 页面 http://localhost:5601/ 会看到如下的信息:
Index Patterns: In order to visualize and explore data in Kibana, you'll need to create an index pattern to retrieve data from Elasticsearch.

加载到 Elasticsearch 的每组数据都有一个索引模式(Index Pattern)。
在上一节中,为莎士比亚数据集创建了名为 shakespeare 的索引,为 accounts 数据集创建了名为 bank 的索引。
一个 索引模式 是可以匹配多个索引的带可选通配符的字符串。例如一般在通用日志记录中,一个典型的索引名称一般包含类似 YYYY.MM.DD 格式的日期信息。例如一个包含五月数据的索引模式: logstash-2015.05*。
定义索引模式时,匹配该模式的索引必须在 Elasticsearch 中存在。并且那些索引必须包含数据。



在 Elasticsearch 中搜索数据
具体过程参考:
- 中文 https://www.elastic.co/guide/cn/kibana/current/tutorial-discovering.html
- 英文 https://www.elastic.co/guide/en/kibana/current/tutorial-discovering.html
单击侧面导航中的 Discover 进入 Kibana 的数据探索功能。在查询框里,您可以输入 Elasticsearch 查询语句 来搜索您的数据。
例如我们想查询0到99之间所有余额超过47,500的账户号码:
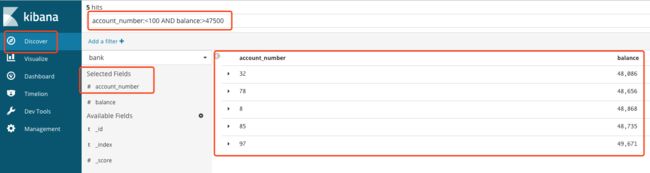
可视化数据
具体过程参考:
- 中文 https://www.elastic.co/guide/cn/kibana/current/tutorial-visualizing.html
- 英文 https://www.elastic.co/guide/en/kibana/current/tutorial-visualizing.html
在侧边导航栏点击 Visualize 开始视化您的数据。例如:我们使用饼图这个重要的可视化控件来查看银行账户样本数据中的账户余额。点击屏幕中间的 Create a visualization 蓝色按钮开始。
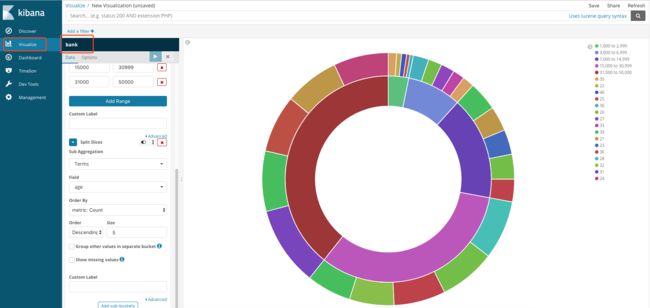
使用仪表板汇总数据
具体过程参考:
- 中文 https://www.elastic.co/guide/cn/kibana/current/tutorial-dashboard.html
- 英文 https://www.elastic.co/guide/en/kibana/current/tutorial-dashboard.html
仪表板可用于集中管理和分享可视化控件集合。
Spring Cloud Sleuth 集成 ELK
参见 Spring Cloud 学习笔记 - No.8 分布式服务跟踪 Sleuth