摘要: DataWorks基于MaxCompute作为核心的计算、存储引擎,提供了海量数据的离线加工分析、数据挖掘的能力。通过DataWorks,可对数据进行数据传输、数据转换等相关操作,从不同的数据存储引入数据,对数据进行转化处理,最后将数据提取到其他数据系统。
摘要:DataWorks基于MaxCompute作为核心的计算、存储引擎,提供了海量数据的离线加工分析、数据挖掘的能力。通过DataWorks,可对数据进行数据传输、数据转换等相关操作,从不同的数据存储引入数据,对数据进行转化处理,最后将数据提取到其他数据系统。在本文中,阿里巴巴计算平台产品专家祎休为大家介绍了通过DataWorks进行新增调度资源、调度资源管理、配置不同周期任务依赖等最佳实践。
直播视频回看,戳这里!
分享资料下载,戳这里!
更多精彩内容传送门:大数据计算技术共享计划 — MaxCompute技术公开课第二季
以下内容根据演讲视频及PPT整理而成。
大家在使用MaxCompute的时候更多地是在DataWorks上面实现基于ETL加工、调度、配置以及云上数仓的构建任务。本文将与大家分享DataWorks后台强大调度系统的实现逻辑以及一些具体的实现案例,希望能够对大家在做云上数仓相关工作时有所帮助。
本次分享主要分成3个部分,在第一部分是调度的基本介绍,主要为大家分享DataWorks的基本概念,这部分将帮助大家理解后续的依赖关系。第二部分将与大家分享依赖关系的简介,比如自依赖、跨周期依赖以及版本依赖等,以及这些依赖之间会在后台生成什么样的实例等。最后一部分将与大家分享依赖关系的实战,为大家剖析两个案例,并回顾本次分享的内容。总体上而言,通过本次分享希望能够帮助大家区分DataWorks和MaxCompute的不同点,让大家更好地理解DataWorks的定位是MaxCompute之上云上数仓的开发工具。
一、调度基本介绍
首先需要明确两个概念:节点和实例。如下图左侧所示,节点是描述DataWorks数据分析和处理过程的基本单元,比如Shell、ODPS SQL、ODPS MR、PyODPS等。而在Dataworks后台前一天23:30的节点会生成快照,统一生成的运行实例。对于用户而言,在配置调度上的最大感触就是在23:30分之前提交的调度配置,会在23:30分之后生效,而在23:30分之后配置的一些依赖关系只能够间隔一天再统一地生成实例。实例会对非天任务进行拆分,如一小时一次的小时节点将会拆分成具体的24个实例。
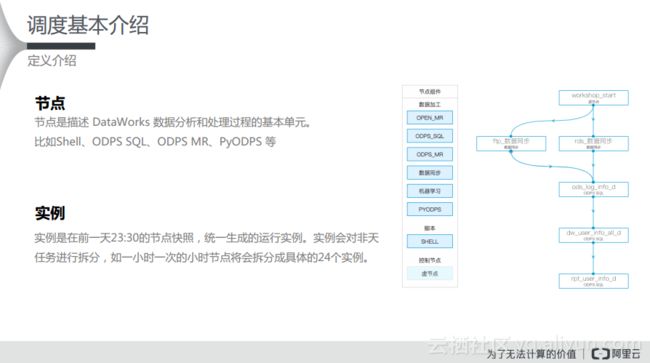
此外,还需要明白两个关系,就是调度规则和依赖关系。对于调度规则而言,首先需要满足依赖关系,即上游节点必须完成,才能调度下游节点;其次,需要判断定时的时间是否已经到了,如果到了就立即执行,如果没有到,就需要等待时间。对于依赖关系而言,正如下图中右侧所示,是描述两个或多个节点之间的语义连接关系,其中上游节点的状态将影响其他下游节点的运行状态,反之则不成立。

此外,还需要为大家介绍跨周期依赖和自依赖关系。在如下图右侧的栏目去打开就能看到,跨周期的依赖有很多选项,在这些选项背后有很多的概念。第一个就是跨周期依赖,这其实也分了跨周期和跨版本的两个概念,如何理解呢?其实,跨周期依赖是针对小时任务的,也就是小时任务依赖同一天的上一个周期。比如每个节点按照小时进行调度,那当前的节点能否调度起来需要依赖于上一个周期是否成功返回了。另外一部分就是跨版本依赖,这种依赖就是针对于天依赖的任务做的,比如今天任务能否成功运行依赖于昨天的任务能否成功返回,这里更多的会有一些数据的先后依赖关系,因此在这部分需要做跨版本的依赖配置。而自依赖可以理解成为跨周期和跨版本的依赖,针对于天任务,如果配置了自依赖,那么就是会依赖于昨天版本的实例。针对于小时任务,就会依赖于每天的最后一个周期。

二、依赖关系简介
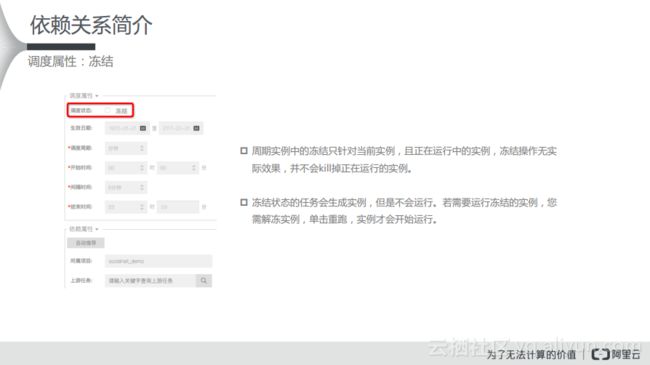
调度属性:冻结
在依赖关系里面,可以通过整体的架构图来看。在WorkFlow里面可以看到,属性里面有一个冻结的概念,周期实例中的冻结只针对当前实例,且正在运行中的实例,冻结操作无实际效果,并不会杀掉正在运行的实例。冻结状态的任务会生成实例,但是不会运行,可以理解为空跑状态。如果需要运行冻结的实例,需要解冻实例,单击重跑,实例才会开始运行。
出错机制
在公共云上,如果开启了出错机制,那么默认会重试3次,每次间隔2分钟,如果经历了3次重试还是失败,那么就会返回失败状态。

对于调度属性而言,DataWorks有5种调度周期,分别是分钟、小时、日、周和月。如果周期大于天的,那么由于调度的实例划分时按天生成的,所以周月任务在不运行的哪一天实际是按照空跑处理的。如果选择日调度,而且不勾选定时调度的,定时时间统一按照0点处理。
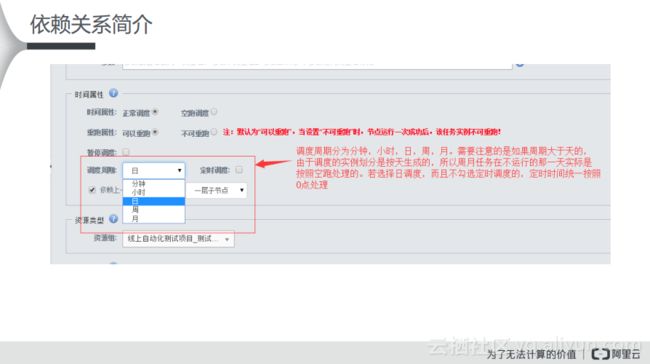
此外,跨周期依赖里面有4个选项,他们分别对应了不同的概念。比如“不依赖上一调度周期”就是其不会形成跨周期和版本的依赖关系,而如果勾选了“自依赖”,那么就会依赖当前节点的上一周期,只有当上一周期运行结束并且返回成功,当前节点才能运行。另外一部分,如果选择了如图所示的,依赖于“一层子节点”或者等待“下游任务的上一周期结束”才能运行。此外,还能自定义一些节点,当然在节点里面可以输入节点ID或者名称与一些自定义的任务进行依赖关系配置。而如果勾选了“等待自定义任务的上一周期结束,才能继续运行”,这样当前的工作流任务就会等待依赖的任务节点结束才会运行。

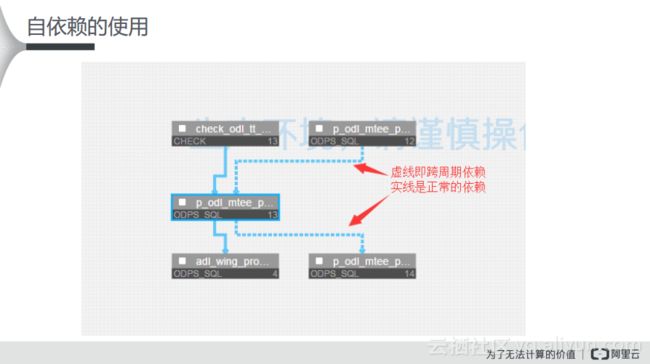
自依赖的使用
如下图所示,大家可以在DataWorks运维中心里面看到每天生成的运行实例的图。这与开发面板不太一样,如果存在实现的上下游依赖关系,那么就是正常的依赖关系,而有虚线的就是跨周期或者自依赖的关系。从这些可以判断,一些用户配置了自依赖,如果发现今天的任务没有跑起来,就需要去追溯昨天的任务是否运行正常,如果昨天的任务也没有正常运行就需要继续向上追溯。
三、依赖配置实战
调度依赖关系
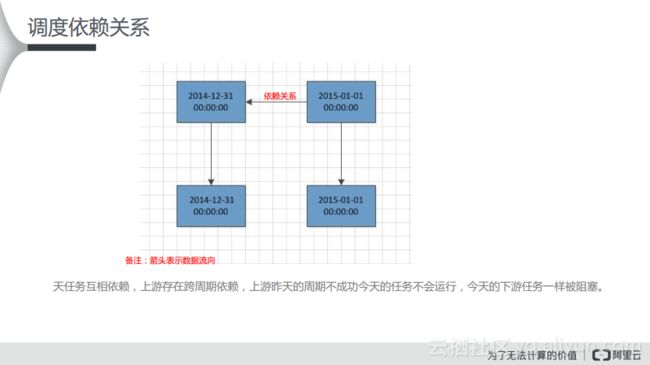
如下所示的整页图里面是天任务的相互依赖,箭头表示的数据流向。如果根据下图将箭头反方向调整就可以理解成依赖关系,也就是下游会依赖上游。现在箭头则表示数据的流向,假设现在有两个天调度的任务,两个都是凌晨开始运行的,那么当上游任务成功运行了,下游才会运行起来,而且如果上游任务没有运行完成,下游任务即使定时时间到了也无法运行。
在下图中可以看出,天任务可以相互依赖,上游存在跨周期依赖。如果下游任务想要成功执行,就需要上游任务成功运行作为前提。下图中可以看出,2014年和2015年的两个实例分别存在相互依赖关系,上游的任务会依赖上一周期的一层子节点,如果上游昨天的任务未成功运行,那么就会阻塞昨天的任务和今天的下游任务。
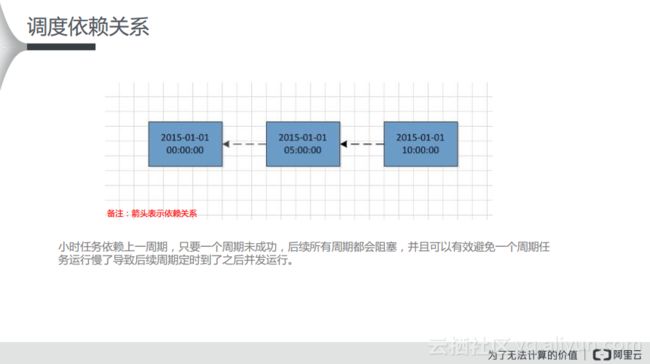
如下图所示的小时任务比较流行,大家可能会经常配置6个小时或者8个小时的任务,这样会生成3至4个实例,这样只要一个周期未成功,后续的所有周期都会阻塞,并且可以有效避免一个周期任务运行慢了导致后续周期定时到了之后并发运行。
调度基础依赖类型介绍
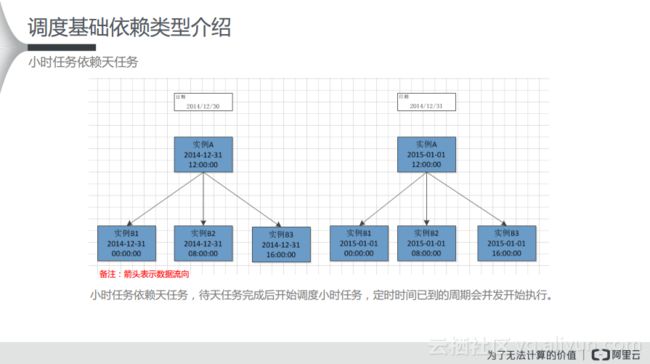
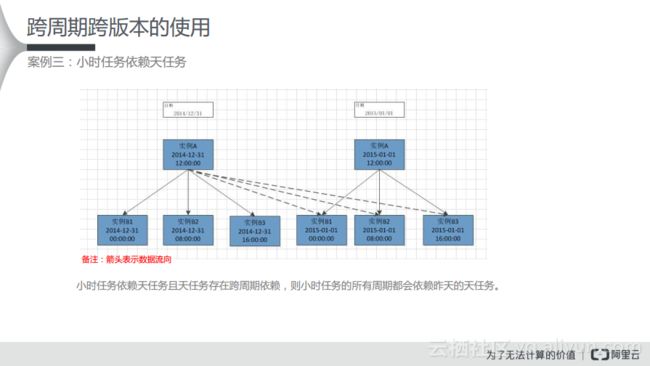
(1) 小时任务依赖天任务
从下图中可以看出,是小时任务依赖天任务。在左侧中是2014年12月31日的情况,实例B1、B2和B3都会依赖实例A,实例A是12点运行,而实例B1、B2以及B3都是小时任务,所以需要依赖天任务,需要等待天任务完成之后才能运行。而当定时的时间到了,这些任务才会并发地执行,在这里就是上游实例A成功运行了,下游的B1、B2和B3才能同时并发地执行。
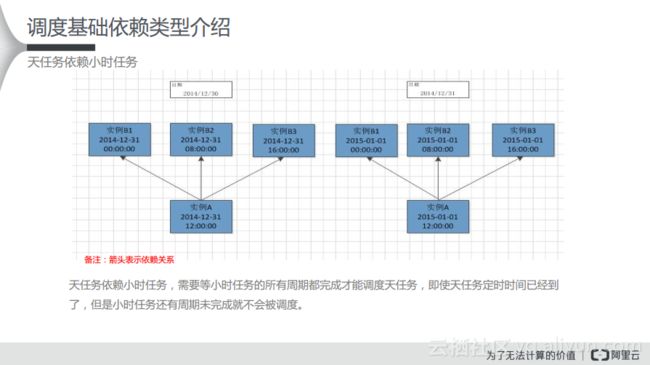
(2) 天任务依赖小时任务
实例A是实例B1、B2和B3的下游节点,也就是说实例A依赖于上游的几个小时任务节点。这样一来,天任务就需要等待小时任务的所有周期都完成了才能去调度这样的天任务,所以如果按照每8个小时跑一个小时任务,这样就能够拆分成3个实例,只有当这些小时实例都成功运行之后,下游的天任务才能在时间已经到了的情况下运行起来。
(3) 小时任务依赖小时任务且周期数一样
比如上游节点是小时任务,下游的节点也是小时任务,当这两个小时任务都是按照每几个小时生成时,其生成的实例数是一样的,在这种情况下可以理解为父子节点都是小时任务,同时其周期数也是一样的。而每一个运行的实例都会形成一个一一对应的关系。当然,若下游的定时晚于上游的定时,在下游定时时间到了的时候也不能调度,需要等待上游对应的周期完成之后才能开始调度。
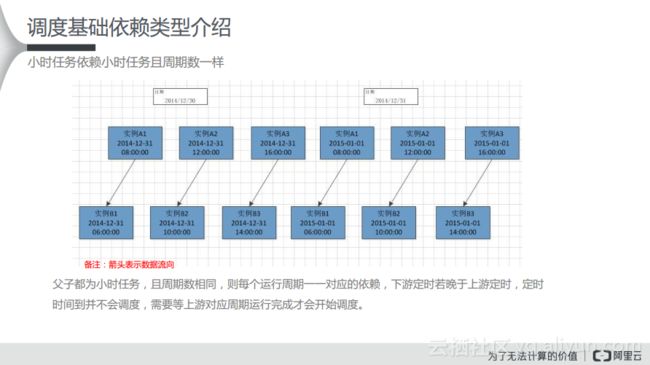
(4) 小时任务依赖小时任务且周期数不同
在这种情况下,可能上游按照12个小时运行一次,那么一天可能会生成两个实例,下游则可能每天按照6个小时,那么这个时候可能生成6个实例。其实,可以从图中看出其是如何依赖的关系,小时任务依赖小时任务,如果其周期数不同,如果下游周期数大于上有的周期数,则会依据就近原则挂依赖,也就是时间小于或者等于自己且不重复的依赖。
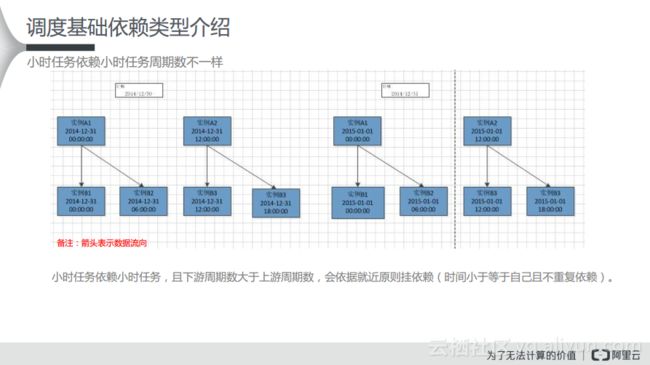
自依赖的使用
案例1:小时任务依赖天任务
在如下图所示的任务依赖中,箭头表示了数据的流向。之前案例也讲到,如果上游天任务完成时下游有多个周期定时时间已到,会导致这些周期被并发调度起来,如果不希望下游并发调度起来,则需要将下游小时任务设置成自依赖,即依赖上一周期,也就是本节点,这样形成一个自依赖。需要注意的是,自依赖会依赖跨版本(跨天),如果昨天最后一个周期未完成,会导致今天的任务无法调度。如下图所示,实例A属于天任务,而下游实例B则是每8小时执行一次的小时任务,实例B之间则会有一些虚线的依赖关系。比如实例A在12点运行成功了,那么实例B在运行的时候需要先去判断实例A的状态与自己的定时时间,生成完之后才会依次执行B2、B3,而当出现了跨天的情况,比如执行到B4的时候,需要去判断昨天最后一个实例的状态。
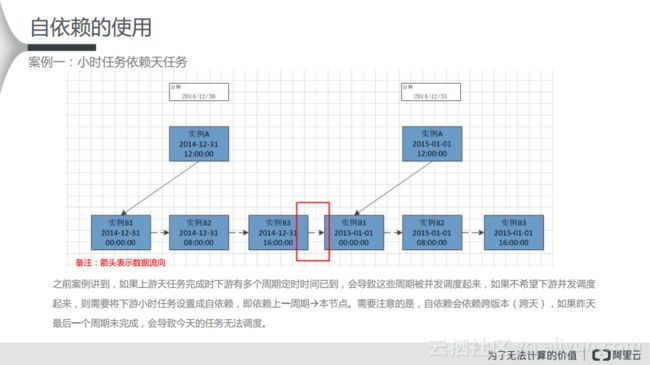
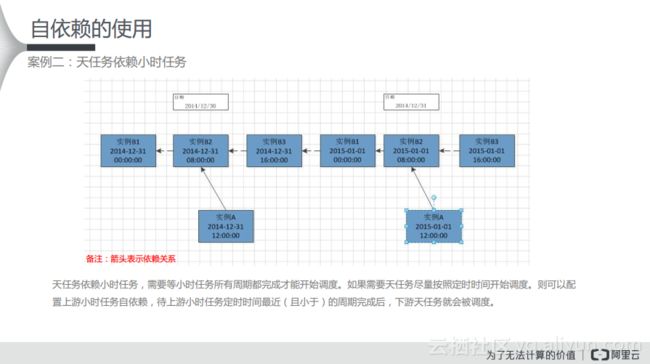
案例2:天任务依赖小时任务
在下图里面,箭头表示依赖关系。如果天任务依赖小时任务,需要等待小时任务的所有周期都完成了才能开始调度。比如在上游按照每小时运行一次的数据,等所有数据都落入到对应的分区之后,再按照一定的数据汇总24小时的数据。如果需要天任务尽量按照定时时间开始调度。则可以配置上游小时任务自依赖,待上游小时任务定时时间最近(且小于)的周期完成后,下游天任务就会被调度。
案例3:小时任务依赖天任务
小时任务依赖天任务且天任务存在跨周期依赖,则小时任务的所有周期都会依赖昨天的天任务。
案例4:天任务依赖小时任务
对于这样的情况需要配置依赖一层子节点,比如上游的小时任务跨周期依赖下游的定时天任务,效果即上游小时任务会在每一周期都会依赖上一版本的下游任务。

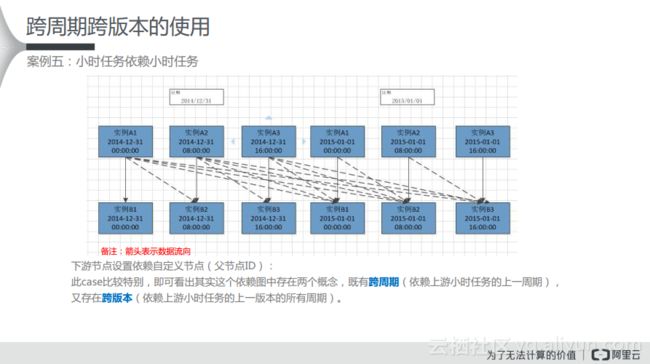
案例5:小时任务依赖小时任务
这种情况比较复杂,图中的实线表示依赖关系,虚线则表示自依赖关系。为了实现这样的依赖关系,需要在下游节点设置依赖自定义节点(父节点ID)。在这个case比较特别,即可看出其实这个依赖图中存在两个概念,既有跨周期(依赖上游小时任务的上一周期),又存在跨版本(依赖上游小时任务的上一版本的所有周期)。
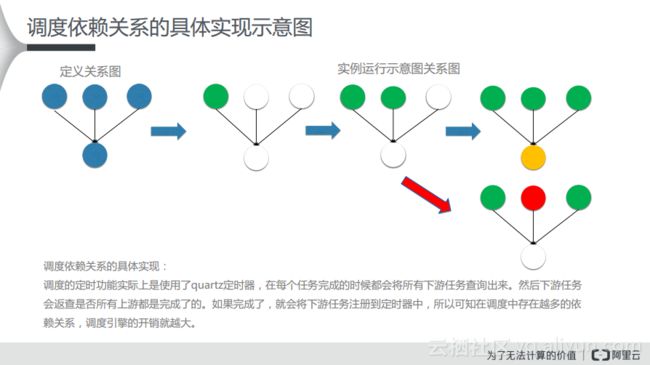
调度依赖关系的具体实现示意图
首先对于定义关系图而言,上游三个节点,下游一个节点这样的情况而言,在每天23:30分会生成一个节点快照,生成一个可运行的实例。当实例运行的时候,会依次运行上游的各个节点,当各个节点全部运行成功了之后,下游节点就会判断是否已经到了自己能够执行的时间,如果符合执行条件就会去执行。而如果上游任何一个节点执行失败了,就会导致下游节点一直处于等待状态。
跨周期跨版本的使用
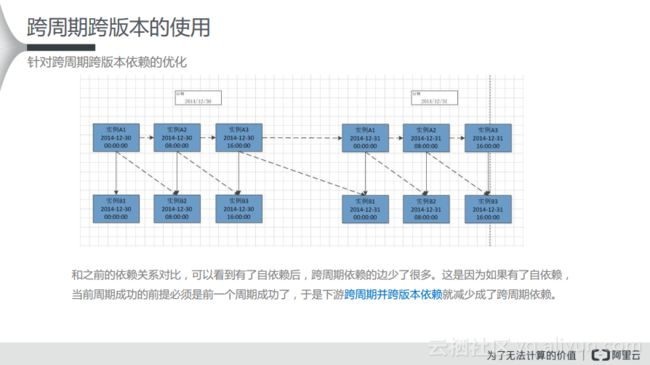
(1) 针对跨周期跨版本依赖的优化
和之前的依赖关系对比,可以看到有了自依赖后,跨周期依赖的边少了很多。这是因为如果有了自依赖,当前周期成功的前提必须是前一个周期成功了,于是下游跨周期并跨版本依赖就减少成了跨周期依赖。
(2) 天任务依赖小时任务
在天任务依赖小时任务的场景下,系统需求统计截止到每小时的业务数据增量,然后在最后一个小时的数据汇总完成后,需要一个任务进行一整天的汇总。对于这样的场景进行需求分析得到以下两点:
1)每个小时的增量,即每整点起任务统计上个小时时间段的数据量。需要配置一个每天每整点调度一次的任务,每天最后一个小时的数据是在第二天第一个实例进行统计。
2)最后的汇总任务为每天执行一次,且必须是在每天最后一个小时的数据统计完成之后才能执行,那么需要配置一个天任务,依赖小时任务的第一个实例。
如下图中左侧所示,可能期望的结果就是在调度任务的定义时,上游是小时任务,每个小时运行一次,下游是天任务,每天凌晨开始运行,就形成了这样的依赖关系。而对于绿色的图而言,对应的任务实例的状况,只有当每天最后一个小时任务处理完成之后,才会去处理天任务。而当真正按照这种依赖关系进行配置,直接挂靠这种依赖关系,在调度系统中会生成右侧所示的实例,但是这是不符合预期的。
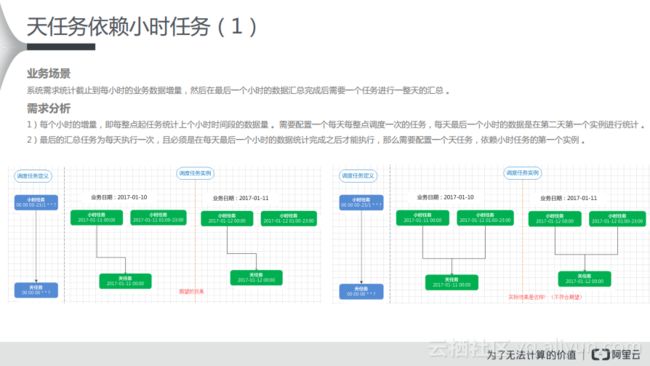
而如果想要达到整体的需求,就需要配置上游小时任务的自依赖。如果上游的小时任务形成自依赖,那么上游的24个小时任务实例就会按照下图左侧中的实例进行依赖,当小时任务都生成之后才会去运行天任务。对于这样的依赖关系,只需要去DataWorks里面选择跨周期依赖的自依赖就可以了。

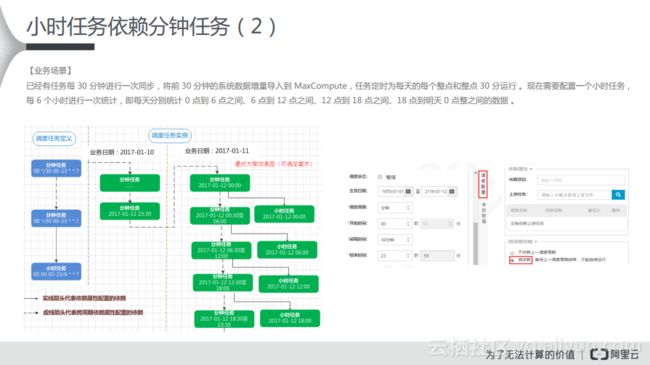
(3) 小时任务依赖分钟任务
对于小时任务依赖分钟任务而言,有这样的一种业务场景:已经有任务每30分钟进行一次同步,将前30分钟的系统数据增量导入到MaxCompute,任务定时为每天的每个整点和整点30分运行。现在需要配置一个小时任务,每6个小时进行一次统计,即每天分别统计0点到6点之间、6点到12点之间、12点到18点之间、18点到明天0点整之间的数据。从分析来看,我们期望的效果就是如下图中左侧所示,上游的分钟任务,每隔30分钟调度一次,下游是小时任务,每隔6个小时调度一次,那么对应的实例里面就会产生对应的依赖关系。
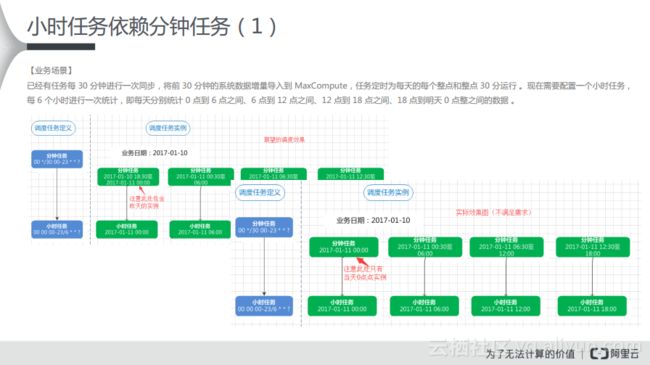
在进行配置时需要选择上游的节点进行自依赖,在如下所示的依赖图中可以看出,分钟级别的依赖任务有自依赖,它会依赖上一周期的成功,并触发下游的小时任务的统计。
原文链接
本文为云栖社区原创内容,未经允许不得转载