前言:
Hadoop的课程已经告一段落,基本上在零基础课程里不会再出现了,接下来的课程由若总来上,第一讲Have。
复习前一个月的课程内容:
1、Linux
Linux:
文件(*****)
权限(*****)
压缩/解压(*****)
软件安装: JDK/MySQL/Hadoop/...(*****)
2、MySQL
DDL/DML(GROUP BY/JOIN:是大数据处理中的超级杀手:shuffle) 这两个是重点数据倾斜的案例:必然是 GROUP BY/JOIN导致的,到时候把这两个反复看熟解决shuffle对大数据来说已经掌握了60%

3、Hadoop
hadoop阐述:狭义和广义两个角度去阐述
狭义: 海量数据的一个分布式的存储和计算框架而已 (HDFS MapReduce YARN)
广义: 描述的是整个Hadoop生态圈,Hadoop里面的框架是处理某一个场景或者是某一类场景
Hadoop访问方式:
shell CLI(*****) 用命令行的方式
Java API(*****): FileSystem
Web UI: HUE(HDFS/RDBMS/Hive/HBase/Solr...)
HDFS/MR/YARN架构:掌握一些基础的就行,明白每个进程的结构和如何使用就行。(面试使用)
面试前准备:
架构
MapReduce 执行流程 (生产不使用,比较low)
MR/Spark/...提交到YARN的执行流程:1~8步骤,举一反三
4、Hadoop的常用操作
HDFS:mkdir put get rm mv
问题:copy vs mv
MR:mr的执行流程(一定要掌握的)
YARN:mr作业跑在yarn之上,杀死yarn上的作业,提交的时候指定的一些重要的参数。
问题:使用MapReduce实现join、mapjoin的功能?
===>非常繁琐
wordcount
明白:MR是非常麻烦的
5.Hive的产生背景:
1、MR编程不便性
2、传统的RDBMS人员的需求
HDFS上面的文件就是普通的文件,它并没有schema的概念
schema:RDBMS中的表结构
people.txt <== id name age address
sql ===> 搞定海量数据的统计分析
===> 产生Hive
6.Hive
Hive 是一个使用SQL来操作分布式存储系统上面的大数据集的读写和管理操作的一个客户端,Hive它不是一个集群。用JDBC去连接Server的话,不应该是走查询统计分析,而是去拿到统计结果,只拿结果,不做计算。
Structure:半 非
分布式系统:HDFS/S3
问题:HDFS存的是近期的数据
1min:几百G
冷数据:定期的移走S3 table的location指向S3
FaceBook开源目的是解决海量结构化日志数据的统计文件
Hive构建在Hadoop之上的数据仓库
Hive的数据就是存在 HDFS之上
计算时使用MR
弹性:线性扩展
Hive底层的执行三个引擎:
MapReduce(在Hive1.x的时代MapReduce是默认引擎,在Hive2.x标记MapReduce为过期版本)
Tez
Spark (生产环境正在使用的引擎)
Hive定义一种类似SQL的查询语言:HQL 类SQL
问题:HQL和SQL的关系?
什么关系都没有,只是语法类似,Hive抄的MySQL的语法
很多的SQL on Hadoop的语法都是和RDBMS非常类似的
Hive常用于:离线批处理
SQL ===> MR:我们输入一个SQL通过我们的HIVE工具把SQL语句翻译成MapReduce/Spark/Tez 作业,并提交到YARN上运行 问题:是否智能、执行计划(sql是如何翻译成mr作业)
高级:UDF
Hive的重点
存储格式:
1.textfile
textfile为默认格式
存储方式:行存储
磁盘开销大 数据解析开销大
压缩的text文件 hive无法进行合并和拆分
2.sequencefile
二进制文件,以的形式序列化到文件中
存储方式:行存储
可分割 压缩
一般选择block压缩
优势是文件和Hadoop api中的mapfile是相互兼容的。
3.rcfile存储方式:
数据按行分块 每块按照列存储
压缩快 快速列存取
读记录尽量涉及到的block最少
读取需要的列只需要读取每个row group 的头部定义。
读取全量数据的操作 性能可能比sequencefile没有明显的优势
4.orc存储方式:
数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本
5.自定义格式
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。
总结:
相比传统的行式存储引擎,列式存储引擎具有更高的压缩比,更少的IO操作而备受青睐(注:列式存储不是万能高效的,很多场景下行式存储仍更加高效),尤其是在数据列(column)数很多,但每次操作仅针对若干列的情景,列式存储引擎的性价比更高。在互联网大数据应用场景下,大部分情况下,数据量很大且数据字段数目很多,但每次查询数据只针对其中的少数几行,这时候列式存储是极佳的选择
压缩格式:
可使用Gzip,Bzip2等压缩算法压缩,压缩后的文件不支持split
Hive阶段版本
Stinger plan:(阶段版本)
08/2007: facebook
05/2013: 0.11.0 Stinger Phase1ORC HiveServer2
10/2013: 0.12.0 Stinger Phase2ORC improvement
04/2014: 0.13.0 Stinger Phase3Vectorized query engine Tez(0.13版本后才能用)
11/2014: 0.14.0 Stinger.next Phase 1Cost-based optimizer(CBO基于成本的优化,代价的优化) 01/2015: 1.0.0 (里程碑点)
Stinger:不是一个项目或产品,而是一种提议,旨在将Hive性能提升100倍(仅仅是个参考),包括Hive的改进和Tez项目两个部分。
为什么要使用Hive
1)、简单易用
2)、扩展性好:hdfs空间不够加磁盘加机器,存储不是问题。底层MapReduce或者Spark计算处理不过来就加CPU加内存就行。
3)、统一的元数据管理
如果存放在hdfs上就仅仅就是一个文件而已,如果要进行计算,肯定要告诉这个文件meta信息,哪个文件哪个列,列的数据类型是什么Hive不是集群,Hdoop是集群,Hive仅仅是一个客户端,没有进程,不会挂掉,提交在YARN上执行。
元数据信息:
database、table、clumn:name type、hdfs存储位置:location
元数据存放在哪里呢?
元数据信息,全部配置在MySQL里面
元数据统一管理的好处:
/ruozedata/hadoop/a.txt 将hdfs上的数据用 Hive可以处理,Sprk也可以计算处理,不需要做任何的改进。
Hive/Pig/Impala/Spark SQL/Presto:共享元数据的信息是最大的好处,Hive里面创建了一张表,可以直接用Spark SQL进行访问
问题:Hive的数据存放在哪里?
HDFS + metadata
Vectorized query engine(向量化查询引擎):
传统方式中,对数据的处理是以行为单位,依次处理的。Hive也采用了这种方案。这种方案带来的问题是,针对每一行数据,都要进行数据解析,条件判断,方法调用等操作,从而导致了低效的CPU利用。
向量化特性,通过每次处理1024行数据,列方式处理,从而减少了方法调用,降低了CPU消耗,提高了CPU利用率。结合JDK1.8对SIMD的支持,获得了极高的性能提升。
通过以下参数启用向量化查询引擎:
相关参考:
https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution
Hive体系架构
测试环境部署架构:
客户端(client、web、idbc)发送HQL语句到Hive(可以存放数据在MySQL或者Derby)上,最后作业提交到Hadoop集群上。
问题:Hive需要集群吗?
Hive不需要集群,可以理解Hive为一个客户端。
问题:测试环境存在什么缺陷?
一个MySQL在生产中可能存在单点故障,所以需要准备两个MySQL,一个是active一个是standby,一台机器出现问题,另外一台机器运行。
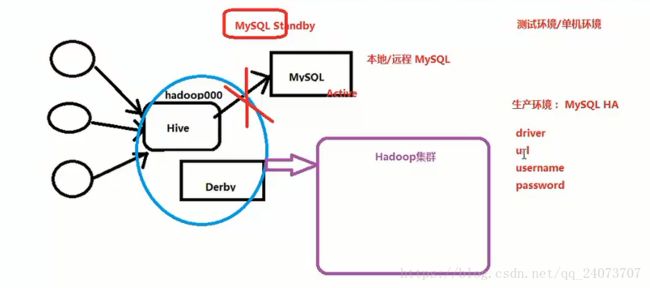
Hive VS RDBMS 关系和区别 异同点
1、Hive关注的是大数据的数据库仓库的统计和分析,跑一个Hive作业跑个7~8个小时是正常的,关注点不同,处理的场景不一样
2、关系型数据库,节点数量是有限制的,Hive是构建在Hadoop之上的,可以支持成千上万的节点的,而且是分布式计算的
3、关系型数据库里面是有事物的 insert/update Hive是没有事物的,都批次执行的,都是离线导入一个批次的数据。
总结:
Hive适用于离线计算,所以它的延迟性和实时性差别很大。MySQL讲究实时性和事物,一个insert或者一个update就要commit,更新数据,Hive处理的数据都是这些数据已经和业务没有直接关联的,停机的数据,进行离线批量的操作。
Hive环境的搭建
若泽数据-J哥:hadoop-2.8.1 Apache Hadoop
生产环境建议使用: CDH HDP (兼容性非常好)大数据平台里面会用到非常非常多的组件,也会遇到非常多的兼容性的问题,Jar包冲突,所以不介意很多组合使用Apache版本,建议使用 CDH HDP
[若泽大数据机器结构]
机器目录结构相关: hadoop/hadoop
hadoop000(192.168.199.151)
hadoop001
hadoop002
.........
/home/hadoop/
software 存放安装软件
hadoop-2.6.0-cdh5.7.0.tar.gz
hive-1.1.0-cdh5.7.0.tar.gz
data 存放测试数据
source 存放源代码
hadoop-2.6.0-cdh5.7.0-src.tar.gz
lib 存放相关开发的jar
commons-lang3-3.5.jar
hive-1.0.jarhive-train.jar
scala-train-1.0jar
spark-2.2.0-bin-2.6.0-cdh5.7.0tgz
spark-train-1.0.jar
train-scala-1.0.jar
train-scala-1.0-jar-with-dependencies.jar
app 软件安装目录
apache-flume-1.6.0-cdh5.7.0-bin
apache-maven-3.3.9
hadoop-2.6.0-cdh5.7.0
hive-1.1.0-cdh5.7.0
jdk1.8.0_144
jdk1.8.0_91
kafka_2.11-0.9.0.0
nginx-1.6.2
scala-2.11.8
spark-2.2.0-bin-2.6.0-cdh5.7.0
sqoop-1.4.6-cdh5.7.0
zookeeper-3.4.11
zookeeper-3.4.5-cdh5.7.0
tmp 存放HDFS/Kafka/ZK数据目录
maven_repo maven本地仓库
/home/hadoop/maven_repo [hadoop@hadoop-01 conf]$ pwd
vi /home/hadoop/app/apache-maven-3.3.9/conf/setting.xml
/home/hadoop/maven_repo shell 存放上课相关的脚本
mysql:root/root
mysql> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('root');
mysql> FLUSH PRIVILEGES;
CDH版本选择:
选择统一的cdh5.7.0尾号
hadoop-2.6.0-cdh5.7.0.tar.gz
hive-1.1.0-cdh5.7.0.tar.gz
wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.
tar.gztar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app
1)创建目录:
[hadoop@hadoop-01 ~]$ mkdir app data lib maven_repo shell software source tmp
查看目录详情
[hadoop@hadoop-01 ~]$ ll
total 32
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:07 app
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:04 data
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:07 lib
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:12 maven_repo
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:27 shell
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:04 software
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:04 source
drwxrwxr-x. 2 hadoop hadoop 4096 May 31 17:27 tmp
2)上传tar.gz文件:
[hadoop@hadoop-01 ~]$ cd software
[hadoop@hadoop-01 software]$ rz
[hadoop@hadoop-01 software]$ll
total 459260
-rw-r--r--. 1 hadoop hadoop 42610549 Jun 2 2018 hadoop-2.6.0-cdh5.7.0-src.tar.gz
-rw-r--r--. 1 hadoop hadoop 311585484 Jun 2 2018 hadoop-2.6.0-cdh5.7.0.tar.gz
-rw-r--r--. 1 hadoop hadoop 116082695 Jun 2 2018 hive-1.1.0-cdh5.7.0.tar.gz
3)解压:
[hadoop@hadoop-01 software]$ tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app/
[hadoop@hadoop-01 software]$ tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/
4)添加HIVE_HOME到系统环境变量:
[hadoop@hadoop-01 app]$ vi ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
[hadoop@hadoop-01 app]$ source ~/.bash_profile
5)Hive配置修改
[hadoop@hadoop-01 conf]$ cp hive-env.sh.template hive-env.sh
vi hive-env.sh
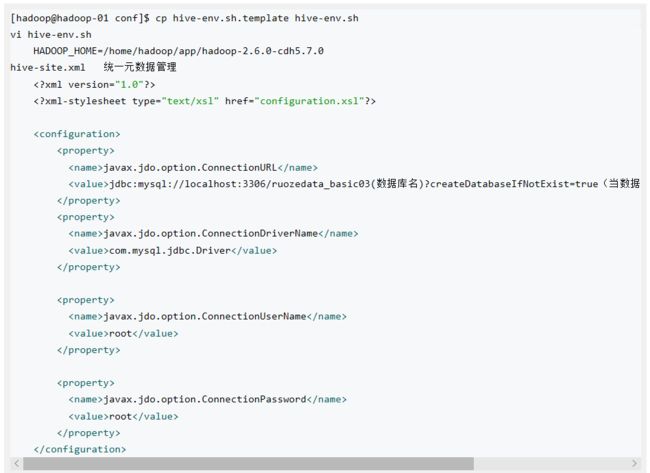
7)拷贝MySQL驱动包到$HIVE_HOME/lib
拷贝 mysql-connector-java-5.1.27-bin.jar
[hadoop@hadoop-01 ~]$ cd $HIVE_HOME
[hadoop@hadoop-01 hive-1.1.0-cdh5.7.0]$ cd lib
[hadoop@hadoop-01 lib]$ rz mysql-connector-java-5.1.27-bin.jar
[hadoop@hadoop-01 lib]$ ll
-rw-r--r--. 1 hadoop hadoop 872303 Dec 19 17:22 mysql-connector-java-5.1.27-bin.jar
如果没有拷贝MySQL驱动包,启动hive会报错:
The specified datastore driver ("com.mysql.jdbc.Driver") was not foundintheCLASSPATH.
Please check yourCLASSPATHspecification,
and the name of the driver.
8)权限问题
创建表失败:
FAILED: Execution Error,
return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
MetaException(message:For direct MetaStore DB
connections, we don't support retries at the client
level.)
思路:找日志
日志在哪里:$HIVE_HOME/conf/hive-log4j.properties.template
hive.log.dir=${java.io.tmpdir}/${user.name}
hive.log.file=hive.log
问题:能不能改,如何改?
日志错误:
ERROR [main]: Datastore.Schema (Log4JLogger.java:error(115)) - An exception was thrown while adding/validating class(es) :
Specified key was too long; max key length is 767 bytes
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Specified key was too long; max key length is 767 bytes
解决:
alter database ruozedata_basic02 character set latin1;
启动Hive

以下网上摘录:
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的。那么,到底什么是Hive,我们先看看Hive官网Wiki是如何介绍Hive的(https://cwiki.apache.org/confluence/display/Hive/Home):
The Apache HiveTM data warehouse software facilitates querying and managing large datasets residing in distributed storage. Built on top of Apache HadoopTM, it provides:
(1)、Tools to enable easy data extract/transform/load (ETL)
(2)、A mechanism to impose structure on a variety of data formats
(3)、Access to files stored either directly in Apache HDFSTM or in other data storage systems such as Apache HBaseTM
(4)、Query execution via MapReduce
上面英文的大致意思是:Apache Hive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在Apache Hadoop之上,主要提供以下功能:它提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL);是一种可以存储、查询和分析存储在HDFS(或者HBase)中的大规模数据的机制;查询是通过MapReduce来完成的(并不是所有的查询都需要MapReduce来完成,比如select * from XXX就不需要;在Hive0.11对类似select a,b from XXX的查询通过配置也可以不通过MapReduce来完成,具体怎么配置请参见本博客《Hive:简单查询不启用Mapreduce job而启用Fetch task》)。
从上面的定义我们可以了解到,Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理;那么,我们如何来分析和管理那些数据呢?
Hive定义了一种类似SQL的查询语言,被称为HQL,对于熟悉SQL的用户可以直接利用Hive来查询数据。同时,这个语言也允许熟悉 MapReduce 开发者们开发自定义的mappers和reducers来处理内建的mappers和reducers无法完成的复杂的分析工作。Hive可以允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:User Defined Functions(UDF)、User Defined Aggregation Functions(UDAF)、User Defined Table Generating Functions(UDTF)。
今天,Hive已经是一个成功的Apache项目,很多组织把它用作一个通用的、可伸缩的数据处理平台。
当然,Hive和传统的关系型数据库有很大的区别,Hive将外部的任务解析成一个MapReduce可执行计划,而启动MapReduce是一个高延迟的一件事,每次提交任务和执行任务都需要消耗很多时间,这也就决定Hive只能处理一些高延迟的应用(如果你想处理低延迟的应用,你可以去考虑一下Hbase)。同时,由于设计的目标不一样,Hive目前还不支持事务;不能对表数据进行修改(不能更新、删除、插入;只能通过文件追加数据、重新导入数据);不能对列建立索引(但是Hive支持索引的建立,但是不能提高Hive的查询速度。如果你想提高Hive的查询速度,请学习Hive的分区、桶的应用)。
Hive的数据存储
在让你真正明白什么是hive 博文中我们提到Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop分布式文件系统中。Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。
Hive中主要包含以下几种数据模型:Table(表),External Table(外部表),Partition(分区),Bucket(桶)(本博客会专门写几篇博文来介绍分区和桶)。
1、表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
2、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
3、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp 表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse /dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
4、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
下面为抽象图:

二、Hive的元数据
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如Mysql、Derby中。我们可以通过以下的配置来修改Hive元数据的存储方式

Hive架构在Hadoop生态圈中已经是老生常谈。尽管如此,很多资料并没有将Hive模块之间的关系描述的十分清楚,本人也在管理Hive数据仓库时绕了不少弯路。所以我们仍要再谈Hive架构,希望将积累的经验总结出一套完整而又易懂的Hive架构,借此为行业新人开路,为大数据运维排忧。
Hive是典型C/S模式。Client端有JDBC/ODBC Client和Thrift Client两类。Server 端则分为如下几个部分:
CLI
Thrift Server
Metastore
WUI
Driver
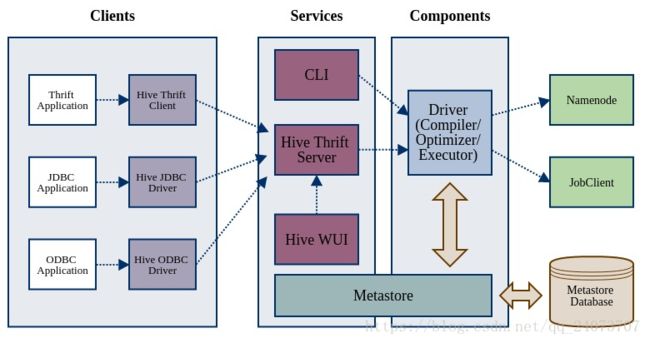
其他资料要么把Hive架构分为Clients/Services两个部分,要么全部称之为组件。为了更好地理解Hive,我重新调整一下组织结构,如上图所示。Hive的模块分为:
Clients:远程访问Hive的应用客户端;
Services:需要独立部署的Hive服务;
Components:独立功能的Hive组件。
下面且听我细细分解。
Clients
Thrift Client
Thrift客户端采用Hive Thrift Server提供的接口来访问Hive。官网已经公开了Thrift服务的RPC,有兴趣的同学可以了解一下。
如果不想重新编写Thrift客户端,Hive也提供了封装好Thrift RPC的Python Client和Ruby Client。
Thrift Client的优点在于,程序员不再依赖Hive环境来访问Hive数据仓库。
JDBC Client
Hive官方已经实现了JDBC Driver(hive-jdbc-*.jar)。如果你希望通过Java访问Hive,请参照官网JDBC Client Sample Code。
Hive 0.14以后,Hive将自带的Beeline重构成一个命令行界面的JDBC Client。之前,Beeline类似于Hive CLI的运行模式。
Beeline解决了CLI无法避免的并发访问冲突。
ODBC Client
目前Hive暂没有提供ODBC Driver支持。
Services
CLI(命令行界面)
CLI是和Hive交互的最简单/最常用方式,你只需要在一个具备完整Hive环境下的Shell终端中键入hive即可启动服务。
我们之所以将CLI归为Services,是因为它可以直接调用Driver来工作。不妨把CLI看成一个命令行界面的单机版Hive服务,用户可以在CLI上输入HQL来执行创建表、更改属性以及查询等操作。不过Hive CLI不适应于高并发的生产环境,仅仅是Hive管理员的好工具。
Hive Thrift Server
Hive Thrift Server是基于Thrift 软件框架开发的,它提供Hive的RPC通信接口。目前的HiveServer2(HS2)较之前一版HiveServer,增加了多客户端并发支持和认证功能,极大地提升了Hive的工作效率和安全系数。
在运维HS2的时候,我们还需要注意以下一些细节:
HS2启动加载hive-site.xml文件配置时,只会加载HS2相关参数。也就是说,你在hive-site.xml里 面设置的Hive任务参数并不会对Clients生效;
Hive Clients的用户权限取决于启动HS2进程的用户;
利用hive.reloadable.aux.jars.path参数可以不用重启HS2而热加载第三方jar包(UDF或SerDe)。
WUI (Web User Interface)
WUI并不属于Apache Hive,它是Hive生态圈的一项服务,目前熟知的有Karmasphere、Hue、Qubole等项目。WUI是B/S模式的服务进程,Server一端与Hive Thrfit Server交互,Brower一端供用户进行Web访问。
目前绝大多数的数据分析公司都采用了Cloudera公司的开源项目Hue作为Hive WUI。后续文章也会着重提及Hue的运维,本文不做详细解说。有关Hue的内容大家可以详见Hue官网。
Components
Driver
Driver在很多Hive架构描述里都划分到Services中,这给我初入Hive带来了一些困扰。我认为Driver并不是服务,而是在输入HQL后才会被调用的一项组件,在这里将其归纳到Components部分。每一个Hive服务都需要调用Driver来完成HQL语句的翻译和执行。通俗地说,Driver就是HQL编译器,它解析和优化HQL语句,将其转换成一个Hive Job(可以是MapReduce,也可以是Spark等其他任务)并提交给Hadoop集群。
Metastore
Metastore是Hive元数据的存储地。在功能上Metastore分为两个部分:服务和存储,也就是架构图中提到的Metastore及其Database。
官方提供了服务和存储部署的三种模式,我们一一介绍之。
内嵌模式
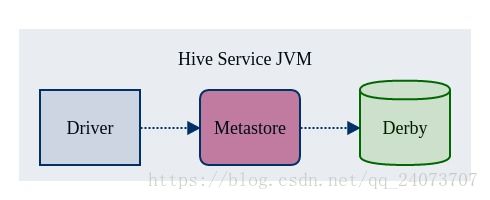
内嵌模式是Hive Metastore的最简单的部署方式,使用Hive内嵌的Derby数据库来存储元数据。但是Derby只能接受一个Hive会话的访问,试图启动第二个Hive会话就会导致Metastore连接失败。
Hive官方并不把内嵌模式当做默认的Metastore模式。我们把官方解释翻译成了大白话,“内嵌模式自个儿玩玩就行,投入生产概不负责”。需要尝试内嵌模式的同学,可以手动修改hive-site.xml中的embedded.metastore.configruation参数并重启相应的Hive服务。
本地模式

本地模式是Metastore的默认模式(懒人专用模式)。该模式下,单Hive会话(一个Hive 服务JVM)以组件方式调用Metastore和Driver。
我们可以采用MySQL作为Metastore的数据库。下面列出部署细节:
在hive-site.xml中设置MySQL的Connection URL、用户名和密码以及ConnectionDriverName;
将MySQL的JDBC驱动Jar文件放到Hive的lib目录下。
远程模式
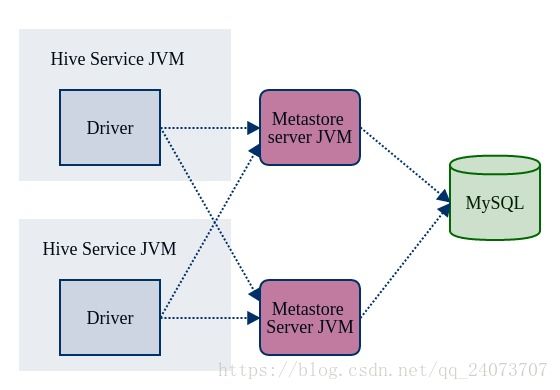
Remote Metastore
远程模式将Metastore分离出来,成为一个独立的Hive服务(Metastore服务还可以部署多个)。这样的模式可以将数据库层完全置于防火墙后,客户就不再需要用户名和密码登录数据库,避免了认证信息的泄漏。
远程模式的配置如下:
