本文作者为图普科技工程师,英文版本地址为:https://medium.com/towards-data-science/an-overview-of-resnet-and-its-variants-5281e2f56035
关键词:机器学习 深度学习 计算机视觉 数据科学 走向数据科学
从AlexNet[1]在2012年的LSVRC分类大赛中取得胜利之后,“深度残差网络[2]”可以称得上是近年来计算机视觉(或深度学习)领域中最具开创性的工作了。ResNet的出现使上百甚至上千层的神经网络的训练成为可能,并且训练的成果也是可圈可点的。
利用ResNet强大的表征能力,不仅是图像分类,而且很多其他计算机视觉应用(比如物体检测和面部识别)的性能都得到了极大的提升。
自从ResNet在2015年震惊学术界产业界后,许多研究界的专家人员就开始探究其背后的成功之道了,研究人员也对ResNet的结构做了很多改进。这篇文章分为两部分,在第一部分我会为那些对ResNet不熟悉的读者们重温一下这个创新型的工作,而在第二部分我则会简单介绍最近我读过的一些关于ResNet的解读及其变体的论文。
重温ResNet
根据无限逼近定理(Universal Approximation Theorem),我们知道,只要有足够的容量,一个单层的“前馈神经网络”就已经足以表示任何函数了。但是,这个层可能会非常庞大,所以网络很容易会出现过拟合的问题。对此,学术界有一个常见的做法——让我们的网络结构不断变深。
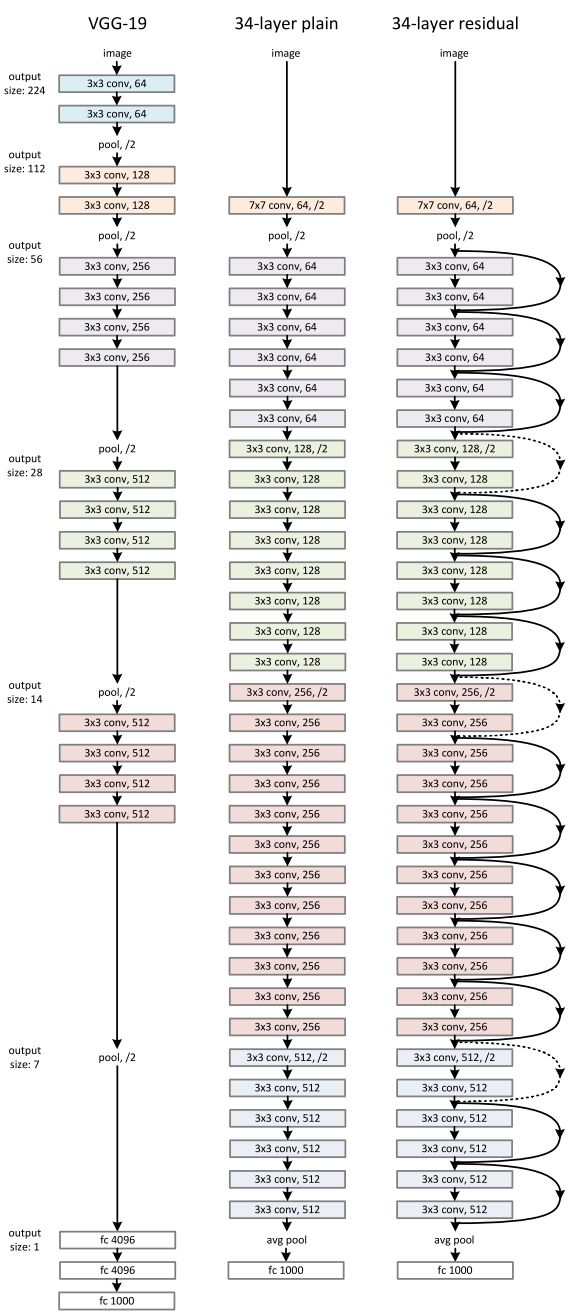
自AlexNet以来,state-of-the-art的CNN结构都在不断地变深。VGG[3]和GoogLeNet[4]分别有19个和22个卷积层,而AlexNet只有5个。
然而,我们不能通过简单地叠加层的方式来增加网络的深度。梯度消失问题的存在,使深度网络的训练变得相当困难。“梯度消失”问题指的是即当梯度在被反向传播到前面的层时,重复的相乘可能会使梯度变得无限小。因此,随着网络深度的不断增加,其性能会逐渐趋于饱和,甚至还会开始下降。

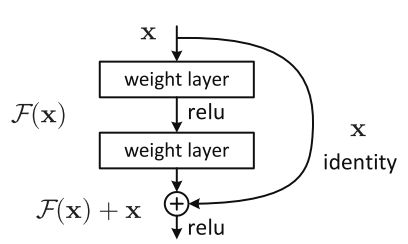
[2]的作者认为,增加网络的层不应该降低网络的性能,因为我们可以将“恒等变换(identity mapping)”简单地叠加在网络上,而且所得到的输出架构也会执行相同的操作。这就暗示了更深层的模型的训练错误率不应该高于与之对应的浅层模型。他们还作出了这样的假设:让堆叠的层适应一个残差映射,与让它们直接适应所需的底层映射相比要简单一些,上图所示的残差块能够明确地使它完成这一点。
ResNet并不是第一个利用shortcut connection的,Highway Network[5]引入了“gated shortcut connection”,其中带参数的gate控制了shortcut中可通过的信息量。类似的做法也存在于LSTM[6]单元里,在LSTM单元中也有一个forget gate来控制着流入下一阶段的信息量。因此,ResNet可以被看作是Highway Network的一个特例。
然而实验结果显示,Highway Network的表现并不比ResNet要出色。这个结果似乎有些奇怪,因为Highway Network的解空间(solution space)中包含了ResNet,所以它的性能表现按理来说应该要比ResNet好的。这就表明保持这些“梯度高速路”的畅通可能比追求更大的解空间更重要。
照着这一想法,文章的作者们进一步完善了残差块,并且提出了一个残差块的pre-activation变体,梯度可以在这个变体中通过shortcut无阻碍地传播到前面的任何一层。实际上,利用[2]中的原始残差块,训练后1201层ResNet的性能比110层的ResNet的性能要差。

[7]的作者们在其论文中通过一些实验表明,他们现在能够训练一个1001层的深度ResNet,使其性能优于跟它对应的浅层ResNet。结果证明,他们的训练成果卓有成效,也正是因为这样,ResNet才能在各种各样的计算机视觉任务中迅速成为最受欢迎的网络结构之一。
ResNet的最新变体及其新解读
随着ResNet在研究界的不断普及,关于其架构的研究也在不断深入。在接下来的内容中,我将首先介绍一些以ResNet为基础的新网络架构,然后介绍一篇论文,这篇论文通过小型网络集合的角度来解读ResNet。
ResNeXt
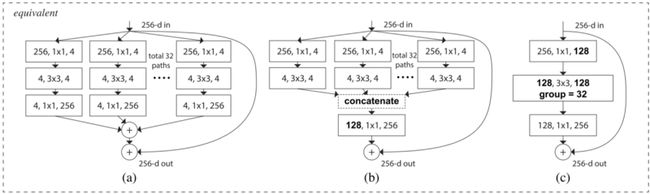
[8]的作者在文章中提出了ResNet的一种变体,代号为ResNeXt。下图是其基本构件:

这看起来可能很熟悉,因为它跟[4]中的Inception模块非常相似。在这个变体中,不同路径输出的合并是通过相加来实现的,除此之外,它们都遵循了“分割-转换-合并”范例,而在[4]中它们却是深度串联(depth concatenated)的。另外一个区别在于,在[4]中,每一个路径互不相同,而在这个架构中,所有的路径都遵循了相同的拓扑结构。
作者们在文中引入了一个叫做“基数(cardinality)”(独立路径的数量)的超参数,提供了一种调整模型能力的新思路。实验表明,通过扩大基数值,我们能够更加高效地提升模型的表现。作者们表示,与Inception相比,这个全新的架构更容易适应新的数据集或任务,因为它只有一个简单的范例和一个超参数需要调整,而Inception需要调整很多超参数(比如每个路径卷积核的大小)。
这个全新的结构有三个等价形式:
DenseNet
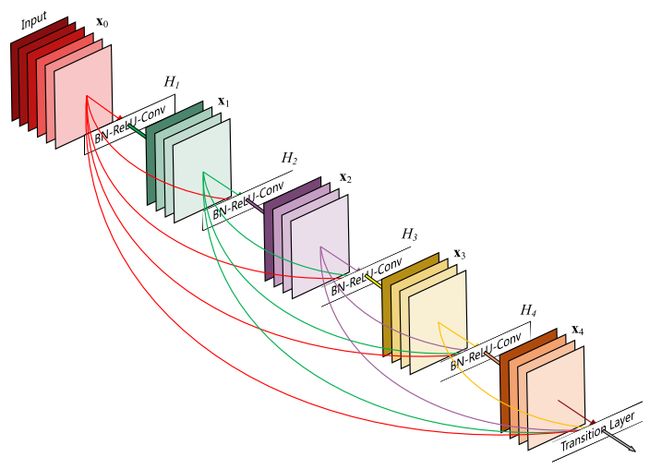
[9]的作者提出了一个叫做DenseNet的新网络结构,这个结构进一步使用了shortcut connections,将所有的层互相连接起来。在这个新架构中,每一层的输入都包含了所有较早的层的feature maps,而且它的输出被传递至每个后续层。这些feature maps通过depth concatenation在一起。


深度随机的神经网络
ResNet的强大性能在很多应用中已经得到了证实,尽管如此,ResNet还是有一个不可忽视的缺陷——更深层的网络通常需要进行数周的训练——因此,把它应用在实际场景下的成本非常高。为了解决这个问题,[10]的作者们引入了一个“反直觉”的方法,即在我们可以在训练过程中任意地丢弃一些层,并在测试过程中使用完整的网络。
作者们用了残差块作为他们网络的构件,因此,在训练中,如果一个特定的残差块被启用了,那么它的输入就会同时流经恒等表换shortcut(identity shortcut)和权重层;否则输入就只会流经恒等变换shortcut。在训练的过程中,每一个层都有一个“生存概率”,并且都会被任意丢弃。在测试过程中,所有的block都将保持被激活状态,而且block都将根据其在训练中的生存概率进行调整。
从形式上来看,H_l是第l个残差块的输出结果,f_l是由l第l个残差块的权重映射所决定的映射,b_l是一个Bernoulli随机变量(此变量的值只有1或0,反映出一个block是否是被激活的)。具体训练过程如下:

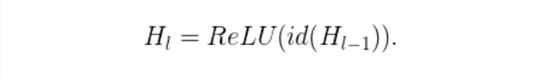
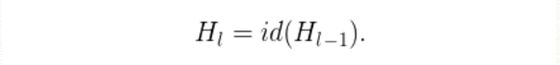

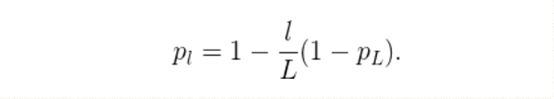

实验表明,同样是训练一个110层的ResNet,以任意深度进行训练的性能,比以固定深度进行训练的性能要好。这就意味着ResNet中的一些层(路径)可能是冗余的。
作为小型网络集合的ResNet
[10]一文的作者们提出了一个训练一个深度网络的“反直觉”方法,即在训练中任意地丢弃网络的层,并在测试中使用整个网络。Veit等人[12]介绍了一个更加“反直觉”的发现:我们可以删除经过训练后的ResNet中的部分层,同时保持相当不错的网络性能。这样一来ResNet架构就变得更加有趣了,因为在Veit等人的论文中,作者对VGG网络做了同样的操作,移除了一个VGG网络的部分层,而VGG网络的性能出现了显著的退化。
为了使训练过程更清晰易懂,Veit等人首先介绍了一个ResNet的分解图。当展开这个网络架构以后,我们就能很清楚地发现,一个有着i个残差块的ResNet架构有2**i个不同的路径(因为每一残差块会提供两个独立的路径)。
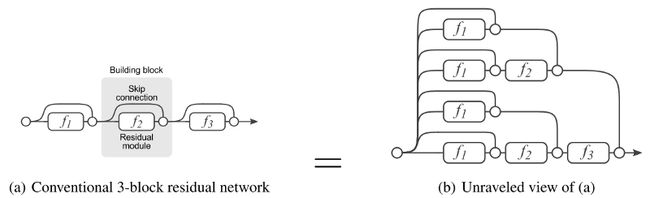
通过实验,作者们还发现了ResNet中的路径有着多模型集成的行为倾向。他们在测试时删除不同数量的层,检查网络性能与删除层的数量是否相关。结果显示,网络的表现确实有着整体聚集的倾向,具体如下图所示:
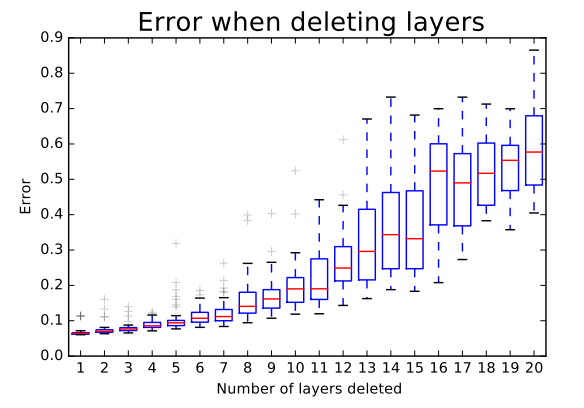
很明显,所有可能路径长度的分布都与一个Binomial分布相关,如下图的(a)所示。大部分的路径都流经了19到35个残差块。

我们现在可以将每一路径长度与其期望的梯度大小相乘,看每一路径长度在训练中起到多大的作用,就像(c)图。令人惊讶的是,大多分布都来自于9到18的路径长度,但它们都只包含少量的总路径,如(a)图。这是一个非常有趣的发现,因为这暗示着ResNet无法解决过长路径的梯度消失问题,ResNet的成功实际上源自于它缩短了它的有效路径(effective path)的长度。
总结
在本文中,我重新回顾了ResNet结构,简要地介绍了隐藏在其背后的成功秘密。之后我还介绍了几篇论文,有些提出了非常有趣的ResNet变体,有些对ResNet作了非常具有洞察力的解读。我希望这篇文章能够帮助你理解这项开创性的工作。
本文中的所有数据均来自参考文献。
参考文献
[1]. A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems,pages1097–1105,2012.
[2]. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[3]. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556,2014.
[4]. C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 1–9,2015.
[5]. R. Srivastava, K. Greff and J. Schmidhuber. Training Very Deep Networks. arXiv preprint arXiv:1507.06228v2,2015.
[6]. S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, Nov. 1997.
[7]. K. He, X. Zhang, S. Ren, and J. Sun. Identity Mappings in Deep Residual Networks. arXiv preprint arXiv:1603.05027v3,2016.
[8]. S. Xie, R. Girshick, P. Dollar, Z. Tu and K. He. Aggregated Residual Transformations for Deep Neural Networks. arXiv preprint arXiv:1611.05431v1,2016.
[9]. G. Huang, Z. Liu, K. Q. Weinberger and L. Maaten. Densely Connected Convolutional Networks. arXiv:1608.06993v3,2016.
[10]. G. Huang, Y. Sun, Z. Liu, D. Sedra and K. Q. Weinberger. Deep Networks with Stochastic Depth. arXiv:1603.09382v3,2016.
[11]. N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever and R. Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. The Journal of Machine Learning Research 15(1) (2014) 1929–1958.
[12]. A. Veit, M. Wilber and S. Belongie. Residual Networks Behave Like Ensembles of Relatively Shallow Networks. arXiv:1605.06431v2,2016.