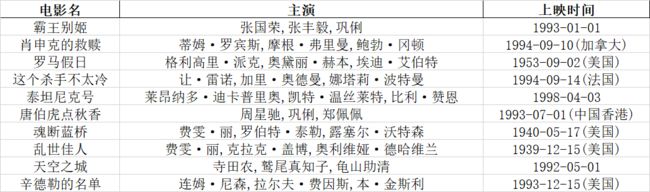
本次主要爬取Top100电影榜单的电影名、主演和上映时间, 同时保存为excel表个形式, 其他相似榜单也都可以依葫芦画瓢
首先打开要爬取的网址https://maoyan.com/board/4, 在不断点击下一页的过程中, 我们可以发现网址的变化是有规律的
https://maoyan.com/board/4?offset=0
https://maoyan.com/board/4?offset=10
https://maoyan.com/board/4?offset=20不同的页数, 变化的只有offset后面的数字, 且以10的倍数增长
使用的python库
1. requests -> 请求页面
2. re -> 匹配想要获取的内容
3. pandas -> 使内容看起来更有结构化, 同时帮助我们将内容保存为文件开始编写爬虫程序
- 获取网页源码
base_url = 'https://maoyan.com/board/4?offset='
# 伪造一个请求头, 这个网上有很多
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'
}
def get_every_page(url):
result = requests.get(url, headers=headers)
# 响应成功则返回源代码内容
if result.status_code == requests.codes.ok:
return result.text
return None
- 分析源码特征, 编写正则表达式, 获取主要内容
20

![指环王3:王者无敌]()
9.
2


从返回的源码中可以发现, 电影的信息都集中在
# filmname = []
# actor = []
# stime = []
html = get_every_page(url)
if html:
# 获取电影信息
# 同时这里需要注意的重点是, 一定不要忘记了修饰符re.S, 否则什么也匹配不出来!
data = re.findall('(.*?)<.*?">(.*?)', html, re.S)
# data中的每一个都是一个元组 输出每一个元组的信息(以某一页为例)
('霸王别姬', '\n 主演:张国荣,张丰毅,巩俐\n ', '上映时间:1993-01-01')
('肖申克的救赎', '\n 主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿\n ', '上映时间:1994-09-10(加拿大)')
('罗马假日', '\n 主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特\n ', '上映时间:1953-09-02(美国)')
('这个杀手不太冷', '\n 主演:让·雷诺,加里·奥德曼,娜塔莉·波特曼\n ', '上映时间:1994-09-14(法国)')
('泰坦尼克号', '\n 主演:莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩\n ', '上映时间:1998-04-03')
('唐伯虎点秋香', '\n 主演:周星驰,巩俐,郑佩佩\n ', '上映时间:1993-07-01(中国香港)')
('魂断蓝桥', '\n 主演:费雯·丽,罗伯特·泰勒,露塞尔·沃特森\n ', '上映时间:1940-05-17(美国)')
('乱世佳人', '\n 主演:费雯·丽,克拉克·盖博,奥利维娅·德哈维兰\n ', '上映时间:1939-12-15(美国)')
('天空之城', '\n 主演:寺田农,鹫尾真知子,龟山助清\n ', '上映时间:1992-05-01')
('辛德勒的名单', '\n 主演:连姆·尼森,拉尔夫·费因斯,本·金斯利\n ', '上映时间:1993-12-15(美国)')因为输出的信息格式差异很大, 我们再来统一一下格式
# data = re.findall('(.*?)<.*?">(.*?)', html, re.S)
# 去除空格和多余的字符, 分别提取出电影名, 主演和上映时间
for i in data:
filmname.append(i[0].strip())
actor.append((i[1].strip())[3:])
stime.append(i[2][5:].strip())
- 将结果保存为文件
将内容生成为DataFrame对象, 再保存为文件
tdict = {'电影名': filmname, '主演': actor, '上映时间': stime}
tdict = pd.DataFrame(tdict, index=[i for i in range(1, 101)])
tdict.to_excel('Top100电影排行榜.xlsx', encoding='utf-8')
print(tdict)
- 完整代码
import requests
import re
import pandas as pd
base_url = 'https://maoyan.com/board/4?offset='
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'
}
def get_every_page(url):
result = requests.get(url, headers=headers)
if result.status_code == requests.codes.ok:
return result.text
return None
def main():
filmname = []
actor = []
stime = []
for i in range(0, 110, 10):
url = base_url + str(i)
html = get_every_page(url)
if html:
data = re.findall('(.*?)<.*?">(.*?)', html, re.S)
for i in data:
filmname.append(i[0].strip())
actor.append((i[1].strip())[3:])
stime.append(i[2][5:].strip())
tdict = {'电影名': filmname, '主演': actor, '上映时间': stime}
tdict = pd.DataFrame(tdict, index=[i for i in range(1, 101)])
tdict.to_excel('Top100电影排行榜.xlsx', encoding='utf-8')
print(tdict)
main()
- 检验成功
打开我们的生成的Top100电影排行榜表格, 结果完美输出nice!
(截取Top10)