编译器构造
一、 编译器简介
前面谈到静态链接器构造的基本流程,最后提到所构造的链接器若要能正常工作的前提是需要构造一个能生成符合链接器输入文件格式的编译器,本文构造一个符合这种具体格式要求编译器。但是编译器的直接编译的结果一般是汇编语言文件,这种文件是不能满足上述静态链接器的需求的,因此在它们之间还需要一个汇编语言程序将汇编语言转换为二进制文件作为链接器的输入。恰如图1-1所示,

图 1-1 静态编译步骤
上次引用这张图是为了说明静态编译器的整体结构,而这次我们侧重于编译程序的构造的流程,在具体展开编译器构造的讨论之前,我们先简单介绍一下编译器的基本知识。
编译从本质上讲就是语言翻译程序,它是把一种语言(称作源语言)书写的程序翻译为另一种语言(称作目标语言)的等价程序。源语言作为编译器的输入,必须让编译器“知道”自己的语法结构——文法,这样编译器才能正确处理语言的结构。所以编译器设计的第一步应该是源语言文法定义。
编译器要处理源语言文件(源文件),必须扫描文件内容,提取出文件内的语法基本单元,比如标识符,关键字,界符等,这一步在编译中称为词法分析,通过这一步,编译器能获得源文件表达的所有语言单位。
接下来,编译器需要分析这些语言单位的组合的合法性以及整体结构,这里编译原理提供了很多成熟的分析算法,这步成为语法分析,语法分析将合法的程序转换为一个逻辑上的语法树形式,方便后边的处理。
另外,由于程序设计语言虽然是结构上是上下文无关的文法,但是实际应用中程序中每个语句并不是独立的,那么如何反应这种联系的存在,语义处理的工作就显得非常必要,它验证了语法模块之间的关联的合法性。
通过以上的步骤,编译器就能判断源程序的合法性,如果是合法程序,编译器就会进行最后一步关键的工作——代码生成,这一步在现代编译器中实现方式多样,例如gcc会先生成中间代码,经过优化后再生成汇编语言,但是本文为了简化编译的流程,直接从语法树过渡到代码生成,按照语法树结构产生源文件对应的汇编代码。
贯穿整个编译流程中,符号表具有很重要的作用,它记录编译过程中许多关键的数据结构,方便编译器存取符号相关信息。最后,错误处理模块会在合适的地方报告编译的错误信息。

图 1-2 直接编译步骤
为了和前述的静态链接器结构保持兼容,这里编译器的设计结构需要作特殊说明。链接器需要多个目标文件作为输入,因此,编译器生成的汇编文件就应该是多个,每个汇编文件会映射为一个目标文件。这样,编译器就不能采用前边所述的直接编译生成一个孤立文件的方式,图1-2,而是采用多文件分别处理的方式进行。由于之前实现了一个直接编译方式的编译器,所以必须对编译器结构进行修改以满足链接器的需要。
既然是对单个的源文件进行编译,就必须要求编译器能处理引用的外部变量和函数,这里主要集中在extern变量和函数声明的语法结构上。为了清晰的阐述编译器的设计过程,下边就按照上述编译器设计的基本步骤阐述每个具体细节,图1-3展示了编译器的设计结构。

图 1-3 编译器结构设计
二、 文法定义
一个程序设计语言是一个记号系统,它的完整定义包含语法和语义两个方面。语法规定了语言的书写规则,而语义定义了语言上下文之间的联系。因此,语言的形式化定义必须通过语法规则来表达,而语法规则就是所谓的文法。
Chomsky于1956年建立了形式语言的描述,他把文法分为四种类型,即0型、1型、2型、3型。这四种文法的类型的范围是依次缩减的,其中2型文法(亦称为上下文无关文法)能很好的表达现代程序设计语言的结构,所以,一般程序设计语言都满足2型文法的规则。
作为编译器处理的核心对象,高级语言的结构直接关系着编译系统的结构。本系统处理的高级语言主体是C语言的子集 ,另外对标准C语言的语法进行了适当的删减和扩充。
自定义高级语言基本特性:
(1)类型:支持int、char、void基本类型和复杂的string类型。
(2)表达式:支持四则运算,简单关系运算和字符串连接运算。
(3)语句:赋值、while循环、if-else条件分支、函数调用、return、break、continue、输入in>>、输出out<<语句。
(4)声明和定义:变量、函数声明定义,外部变量声明extern。
(5)其它:支持多文件、默认类型转换、单行/多行注释等。
自定义语言尽可能接近C语言的格式,以使得编译器的重点放在处理高级语言的过程上,而不过多关心复杂的语言细节,下边给出了自定义的语言的文法定义,见表2-1。
表 2-1 文法规则
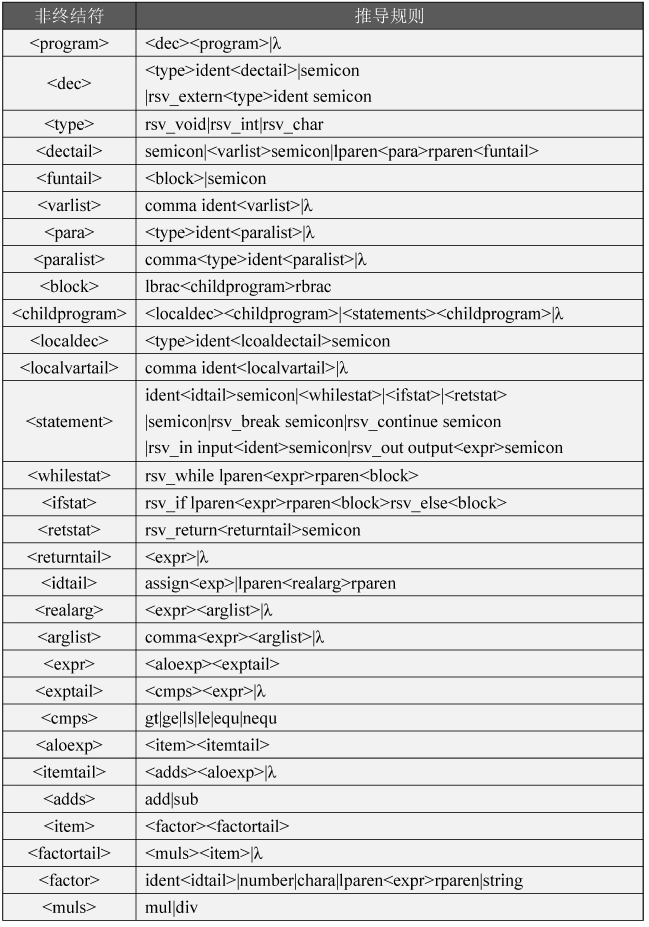
文法定义中^表示空符,<>内表示非终结符,其他为终结符,稍后在词法分析中针对此具体说明。
三、 词法分析
词法分析是编译的第一个阶段,它的任务是从左向右逐个字符地对源程序进行扫描,产生一个个单词序列,用于语法分析。执行词法分析的程序称为词法分析程序或者扫描程序。
在词法分析过程中,最关键的是对词法记号的描述。一般情况下,编译系统使用正则文法来描述词法的规则,而对正则文法识别的工具就是有限自动机。解析正则文法的有限自动机有时候可能不够简洁,这样就需要把不确定的有限自动机(NFA)转化为确定的有限自动机(DFA)。通过有限自动机把词法记号识别出来,就完成了词法分析的工作。
词法分析的主要目的就是从源文件中获取合法的词法记号,主要功能如下:
(1)扫描输入文件,消除注释、无效空格、TAB、回车符。
(2)识别标识符、关键字、常量、界符等,产生词法记号。
(3)识别词法错误(记号过长、意外字符等)。
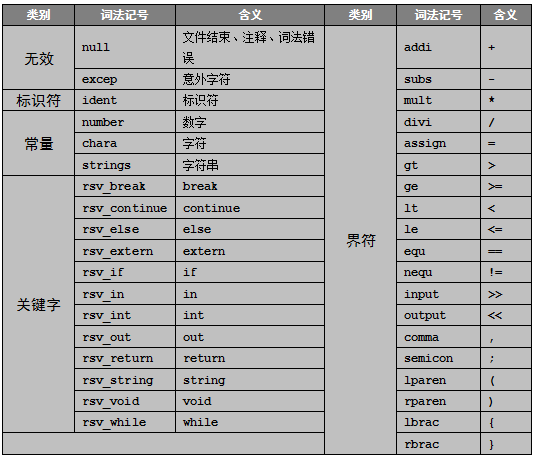
词法分析器一般包括扫描器和解析器两部分,扫描器从文件中读入字符,解析器将扫描出来的字符转换为词法记号。本系统定义的所有词法记号如表3-1所示:
表 3-1 词法记号
3.1 扫描器
扫描器从源文件按字节读入字符数据,将一组字符放入缓冲区。当需要获取字符的时候,从缓冲区中读取,用这种方式可以提高字符读取的效率,代码如下。
{
if(chAtLine>=lineLen) // 超出索引,行读完,>=防止出现强制读取的bug
{
chAtLine= 0; // 字符,行,重新初始化
lineLen= 0;
lineNum++; // 行号增加
ch= ' ';
while(ch!= 10) // 检测行行结束
{
if(fscanf(fin, " %c ",&ch)==EOF)
{
line[lineLen]= 0; // 文件结束
break;
}
line[lineLen]=ch; // 循环读取一行的字符
lineLen++;
if(lineLen==maxLen) // 单行程序过长
{
// 不继续读就可以,不用报错
break;
}
}
}
// 正常读取
oldCh=ch;
ch=line[chAtLine];
chAtLine++;
if(ch== 0)
return - 1;
else
return 0;
}
扫描器算法流程如图3-1所示,
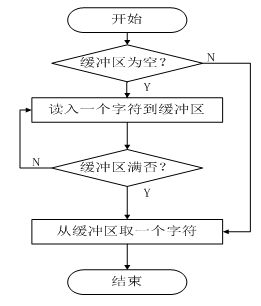
图 3-1 扫描器算法流程
从算法中可以看出,缓冲区对应line数组,每个调用getChar可以将一个字符读入变量ch,oldCh记录上一个字符,lineNum记录了行号方便定位错误位置。
3.2 解析器
解析器从扫描器缓冲区不断读入字符。将字符与表示语言词法规则的有限自动机匹配,若成功则产生词法记号,否则报告词法错误。
标识符的解析流程与有限自动机DFA映射关系如图3-2所示,根据有限自动机结构,若读入的字符改变了有限自动机的状态,则提供条件分支判断;若状态不变,则提供循环程序结构;若遇到终结符则表示识别该词法记号,停止该部分有限自动机的运行。继续获取字符,直到将所有的词法记号识别完为止。
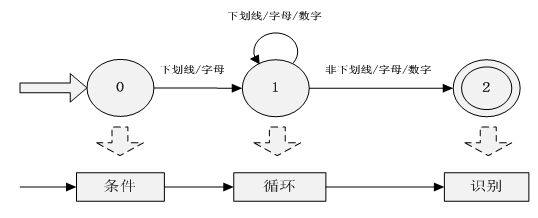
图 3-2 标识符解析流程与DFA映射关系
标识符识别代码如下:
{
while(ch== ' '||ch== 10||ch== 9) // 忽略空格,换行,TAB
{
getChar();
}
if(ch>= ' a '&&ch<= ' z '||ch>= ' A '&&ch<= ' Z '||ch== ' _ ') // _,字母开头的_,字母,数字串:标识符(关键字)
{
int idCount= 0; // 为标识符的长度计数
int reallen= 0; // 实际标识符长度
int f; // getChar返回标记
// 取出标识符
do
{
reallen++;
if(idCount
{
id[idCount]=ch;
idCount++;
}
f=getChar();
}
while(ch>= ' a '&&ch<= ' z '||ch>= ' A '&&ch<= ' Z '||ch== ' _ '||ch>= ' 0 '&&ch<= ' 9 ');
id[idCount]= 0; // 结尾
if(reallen>idLen) // 标识符过长
{
lexerror(id2long, 0);
}
checkReserved();
return f;
}
}
其他词法记号的识别方式如下:
(1)关键字识别。和标识符相同,不过在识别完成后要查询系统预留的关键字表,若查询结果不为空则作为关键字处理。
(2)单行注释识别。读取//两个字符,直到行结束(换行符\n)。
(3)多行注释识别。读取/*两个字符后,直到出现*/结束,中间忽略所有字符。这里多行注释识别简化了,因为无法识别包含*的注释段。
(4)数字识别。从读入第一个数字字符开始直到非数字字符结束。
(5)串识别。从读入双引号开始,直到出现下一个分号为止,中间的所有符号都作为串的内容处理。
(6)字符识别。从读入单引号开始,读取下一个字符作为字符内容,再识别下一个符号是否匹配单引号,否则产生词法错误。
(7)其他界符。单字符界符直接识别即可,双字符界符需读入连续两个字节匹配后才认为识别成功。
通过以上的词法记号识别算法可以识别当前自定义语言的所有词法记号。
3.3 异常处理
在词法分析时,若出现意外,则返回无效的词法记号,然后继续分析。词法错误处理的原则是出现词法错误不影响词法分析的进行。返回无效词法记号时称为词法分析出现意外(即异常,并不一定是错误)。总共有以下几种情况:
(1)处理完注释,注释不能作为有效的词法记号,虽然能正常识别。
(2)出现词法错误。返回无效词法记号,继续词法分析,识别后续正常的词法记号。
(3)文件结束:文件结束后返回-1作为符号,此符号是无意义的记号,但是标识编译的结束条件。
(4)意外字符:文件中出现预期以外的字符时当作异常处理。
(5)有限自动机异常终止。例如识别字符时,在单引号和一个字符后没有出现另一个单引号,此时抛出异常。
由于词法分析的这种错误处理机制,在进行语法分析时必然会读取无效词法记号,此时需要一个过滤器将无效字符过滤掉再进行语法分析。过滤器不是词法分析器的必须结构,可以将其作为语法分析的预处理过程。所有的词法错误如表4-2所示:
表 3-2 词法错误

四、 语法分析
文法描述了程序语言的构造规则,语法分析就是通过对源程序扫描解析出来的词法记号序列识别是否是文法定义的正确的句子。一般情况下语法分析分为两种形式,一种是自顶向下的语法分析方法,另一种是自底向上的语法分析方法(具体内容参考编译原理教材)。本系统采用最容易实现的LL(1)的递归下降子程序分析算法。
在一遍编译器的结构中,语法分析是整个编译器的核心部分,几乎所有的模块都依赖于语法分析模块。主要功能如下:
(1)将过滤后词法记号和文法规则进行匹配。
(2)识别语法模块。
(3)出错时能进行错误恢复。
(4)正常时更新符号表内容,并产生语义动作。
由于词法分析产生的词法记号有时候是异常符号,再进行正式语法分析之前,必须对这些符号进行过滤。
4.1 过滤器
除了过滤无效的词法记号功能外,过滤器还有一个重要的作用是允许在语法分析器获取词法记号的时候暂停读取符号一次。这种方法本质上违背了LL(1)分析算法的初衷,因为LL(1)只允许超前查看一个词法记号。但是有了这种“回退一次”机制,LL(1)可以多向前查看一个字符作为预分析,然后再暂停一次,虽然只能暂停一次。LL(1)只能分析正常的语法,当语法出错需要恢复的时候就无能为力了,本文的过滤器算法能够实现错误修复功能。
过滤器的工作流程如图4-1所示:
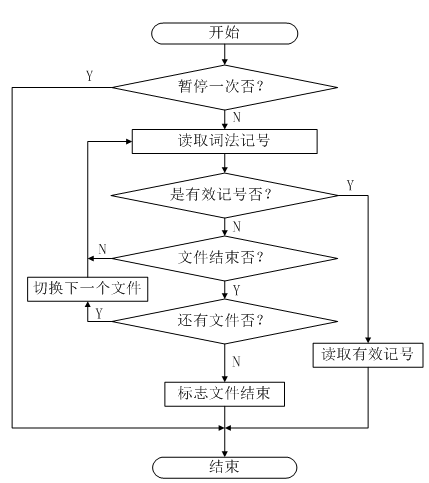
图4-1 过滤器工作流程
对应代码如下:
int nextToken()
{
if(wait== 1) // 处理BACK
{
wait= 0; // 还原
return 0;
}
int flag= 0;
while( 1)
{
flag=getSym();
if(sym== null||sym==excep) // 无效符号掠过
{
if(flag==- 1) // 文件结束
{
oldtoken=token;
token= null;
return - 1;
}
}
else // get effective symbol
{
oldtoken=token; // 上一个符号
token=sym; // 当前符号
return 0;
}
}
}
4.2 递归下降子程序
语法分析是编译器的核心,而语法分析算法LL(1)则是语法分析器的核心。一般情况下随意构造的文法有可能不满足LL(1)的要求,因此需要对文法做出修改,使之满足LL(1)的要求。编译教材里给出两种基本的修正方式:合并左公因子和消除左递归。构造出的满足LL(1)文法上述已经给出,下边需要将该文法转化为语法分析程序。如图4-2展示了一个while语句的识别子程序。
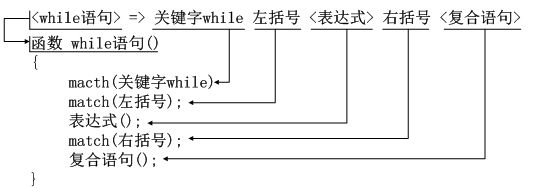
图4-2 递归下降子程序与文法映射关系
可以看出,LL(1)文法和递归下降子程序映射关系很明确:将文法规则中的非终结符转化为子程序定义或者调用,而终结符转化为词法记号的匹配。
可以证明,这种映射方式可以正确的识别LL(1)定义的语言。但是当源程序有错误的时候,这种直接识别方式会有很大的弊端,因此需要对其进行改进。
4.3 错误处理
当词法记号不能被文法规则匹配的时候就会产生语法错误,否则就对正确的文法模块产生语义动作。但是,出现语法错误时不能停止语法分析的进行,以保证能及时发现更多的语法错误。因此,更不能因为前边的语法错误导致后边“更多”正确的语法“出错”。基于此,错误修复算法是语法分析的另一个重点和难点。
错误恢复原理的形式化定义为:
设y是已读入的符号串,L(G)为定义的语言,T是超前记号,y∈L(G),yT!∈L(G)表示T的插入导致语句出错,基于此有四种修复方式:
(1)修改y:不推荐使用该方式,因为和LL(1)分析过程冲突。
(2)在y和T之间插入记号v使得 yvT∈L(G)。
(3)修改T为 V,使得 yV∈L(G)。
(4)删除T,测试T的下一个记号Z是否使得yZ∈L(G)否则重复以上步骤。能解决一部分语法错误,但是可能会忽略很多有用的词法记号。
采用方法(2)、(3)能恢复两大类型的语法错误:一种是符号丢失错误——对应(2),需要回退一个词法记号(过滤器操作);一种是符号内容错误——对应(3),修改该词法记号并跳过它一次;如图4-3所示:

图 4-3 基本错误恢复实例
对应代码如下:
{
if(token==semicon) // 空声明
{
return;
}
else if(token==rsv_extern) // 外部变量声明
{
type();
nextToken();
if(!match(ident)) // 标识符不匹配,极有可能是没有标识符,回退
{
synterror(identlost,- 1);
BACK
}
else // 声明标识符成功
{
}
nextToken();
if(!match(semicon))
{
if(token==rsv_extern||token==rsv_void||token==rsv_int||token==rsv_char||token==rsv_string)
{
synterror(semiconlost,- 1); // 丢失分号
BACK
}
else
{
synterror(semiconwrong, 0);
}
}
}
else
{
type();
nextToken();
if(!match(ident)) // 标识符不匹配,极有可能是没有标识符,回退
{
synterror(identlost,- 1);
BACK
}
else // 声明标识符成功,还不能确定是变量还是函数,暂时记录作为参数传递
{
dec_name+=id;
}
dectail(dec_type,dec_name);
}
}
由于目前还是没有绝对很有效的的错误恢复算法,针对这个问题,本系统站在使用者的角度来考虑,采用对出现在通常情况下人为导致的较高概率的错误进行处理,从而可以取得数学期望上的最大效率恢复的可能。
由此总结错误修复的算法流程如图4-4所示(图中文法符号表示终结符或者非终结符):
超前读入的词法记号按照语法规则与欲得到的记号进行匹配,若成功则继续分析,否则查看该记号是否是文法规则中在下一个文法符号的First集中,如果在则表示丢失欲得到的符号,否则就按照符号不匹配处理。
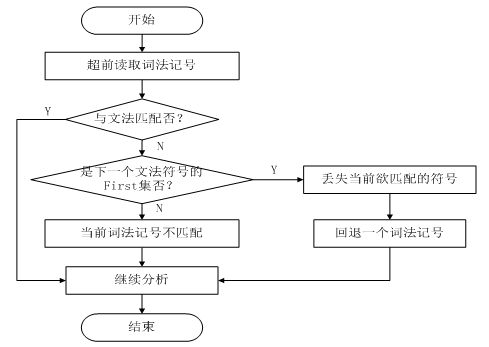
图 4-4 错误恢复算法流程
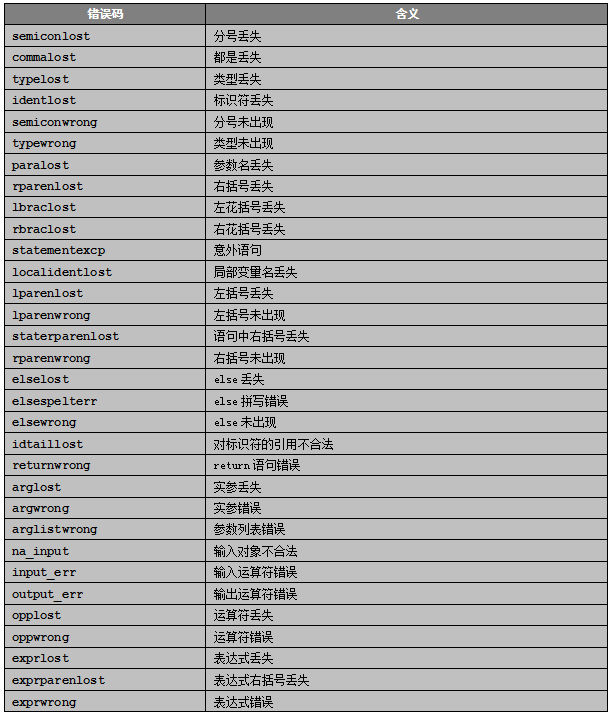
本系统能识别的语法错误如表4-1所示:
表 4-1 语法错误
五、 符号表
符号表是编译过程中保存程序信息的数据结构,它从语法分析模块获取所需的信息,为语义处理和代码生成模块服务。主要功能如下:
(1)保存变量、函数的信息记录。
(2)开辟串空间,保存静态字符串。
(3)管理局部变量的可见性。
(4)处理变量、函数的声明和定义。
5.1 数据结构
符号表相关的数据结构如下:
1.变量记录数据结构定义如下:
{
symbol type;
string name;
union
{
int intVal;
char charVal;
int voidVal;
int strValId;
};
int localAddr;
int externed;
};
(1)type:记录变量的类型,值是枚举类型symbol的rsv_int、rsv_char、rsv_void、rsv_string。
(2)name:记录变量的名字。
(3)匿名联合类型:记录变量的初值,如果没有初值初始化为0,最关键的是strValId字段,它标志着字符串类型变量的存储位置。strValId为-2时表示字符串为全局定义的字符串,存储在数据段中;strValId为-1时表示字符串是局部定义的字符串或者是临时结果字符串,存储在堆栈段中;strValId为大于0的正整数时表示常量字符串存储在串空间的ID。
(4)localAddr:表示局部变量的栈中位置相对于ebp的偏移量,若localAddr为0表示改变量是全局变量。
(5)externded:表示变量是否是外部变量。
2
.函数记录数据结构定义如下:
{
symbol type;
string name;
vector
vector
int defined;
int flushed;
int hadret;
void addarg();
int hasname( string id_name);
void pushlocalvar();
int getCurAddr();
void flushargs();
void poplocalvars( int varnum);
int equal(fun_record&f);
var_record*create_tmpvar(symbol type, int, int);
};
函数记录数据结构的字段说明如下:
(1)type:函数的返回类型,和变量记录相同。
(2)name:函数名。
(3)args:指向参数类型链表的指针。
(4)localvars:指向局部变量记录链表的指针。
(5)defined:指示函数是否定义。
(6)flushed:指示函数的参数缓存的信息是否写入了符号表。
(7)hasret:指示函数在末尾是否有return语句。
(1)addarg():为函数头声明的时候将参数变量信息写入缓冲区。
(2)hasname(string):测试在函数作用域内是否有参数指定名字的变量声明,包含参数名字。
(3)pushlcoalvar():将局部变量的信息压入局部变量链表,并写入符号表。
(4)getCurAddr():取得当前分析代码时刻堆栈指针相对于ebp的偏移。
(5)flushargs():将参数缓存的参数信息写入符号表。
(6)poplocalvars(int&):从局部变量链表后边弹出参数指定数目的变量信息,同时在符号表删除变量信息。
(7)equal(fun_record&f):判断参数指定的函数的声明是否和本记录的声明合法匹配。
(8)create_tmpvar(symbol type,int hasVal,int &var_num):为常量类型创建一个临时变量,参与表达式运算或者参数传递。
3
.符号表数据结构记录所有的符号信息,包括变量和函数符号的信息,另外还增加了一定的扩展信息,数据结构定义如下:
{
hash_map< string, var_record*, string_hash> var_map;
hash_map< string, fun_record*, string_hash> fun_map;
vector< string*>stringTable;
vector
public:
int addstring();
string getstring( int index);
void addvar();
void addvar(var_record*v_r);
var_record * getVar( string name);
int hasname( string id_name);
void delvar( string var_name);
void addfun();
void addrealarg(var_record*arg, int& var_num);
var_record* genCall( string fname, int& var_num);
void over();
void clear();
};
符号表数据结构的字段说明如下:
(1)var_map:变量记录哈希表。
(2)fun_map:函数记录哈希表。
(3)stringTable:串空间。
(4)real_args_list:函数调用实参变量记录链表。
(1)addstring():向串空间添加一个常量串,id从0自增。
(2)getstring():根据串的索引获取串内容。
(3)addvar():向符号表添加一个变量记录信息。
(4)getVar(string):根据变量名字获取变量声明的记录信息。
(5)hasname(string):测试指定的名字是否和当前作用域的变量的符号名重复,函数名称不需要测试。
(6)delvar(string):删除指定名称的变量。
(7)addfun():向函数记录哈希表添加一条函数记录,同时检查函数的声明和定义的合法性。
(8)addrealarg(var_record*arg,int& var_num):向实参列表中添加一个实参变量记录。
(9)genCall():产生函数调用的代码。
(10)over():产生数据段信息。
(11)clear():清空符号表信息。
4
.全局对象
var_record tvar
:记录当前分析的变量的声明定义信息。
fun_record tfun
:记录当前分析的函数的声明定义信息。
Table table:符号表引用对象。
5.2 局部变量作用域管理
局部变量作用域管理算法执行流程如图5-1所示:

图5-1 局部变量作用域管理流程
函数定义时,编译器先将函数记录信息插入符号表,再将局部变量的定义依次插入符号表,并且记录函数内插入变量的个数,等到函数定义结束的时候将刚才插入的变量依次从符号表删除,最后清除缓冲区的变量记录,更新符号表。另外,在表达式解析的过程中会产生临时的局部变量,对其也当作正常的局部变量进行处理即可。
根据上述的变量处理规则,可以实现变量作用域的正确管理。根据5-2这个实例可以更加清晰的看到这一点。由此可以得出结论:
(1)全局变量登记后不会退出符号表。
(2)局部变量记录在域结束后退出符号表。
(3)临时变量同局部变量,但不能被程序直接访问。
(4)域会对其内部声明的变量计数,以便结束时弹出其记录。
(5)不同作用域的变量声明必然不能相互访问。
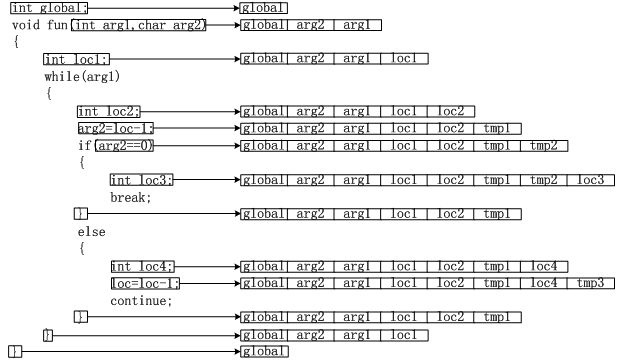
图 5-2 变量作用域管理实例
六、 语义处理
(1)引用符号表内容,检查语义的合法性。
(2)引导代码生成例程。
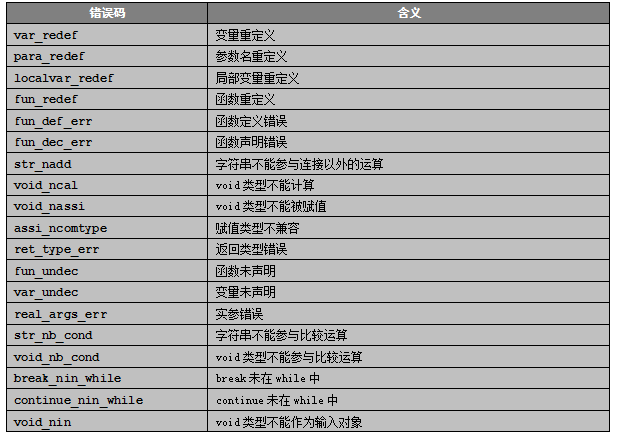
所有的语义错误如表6-1所示:
图 6-1 语义错误
6.1 变量、函数声明的合法性
extern 关键字是对外部变量的声明。extern声明可以重复出现,以保证每个单独的文件都能引用别的文件的全局变量,对extern变量可以只是声明但不使用。
{
if(synerr!= 0) // 有语法错误,不处理
return;
if(var_map.find(tvar.name)==var_map.end()) // 不存在重复记录
{
var_record * pvar= new var_record(tvar);
var_map[tvar.name]=pvar; // 插入tvar 信息到堆中
}
else // 存在记录,看看是不是已经声明的外部变量
{
var_record * pvar=var_map[tvar.name];
// 刷新变量记录信息
delete var_map[tvar.name];
var_map[tvar.name]=pvar; // 插入tvar 信息到堆中
semerror(var_redef);
}
}
和变量声明处理方式类似,函数定义的语义检查做类似处理,不同的是函数检查的时候还要注意参数的合法性匹配,而且对于函数声明,需要函数定义进行替换声明记录,具体代码如下。
void Table::addfun()
{
if(synerr!=0)//有语法错误,不处理
return;
if(fun_map.find(tfun.name)==fun_map.end())//不存在记录
{
fun_record * pfun=new fun_record(tfun);
fun_map[tfun.name]=pfun;//插入tfun 信息到堆中
//函数定义生成代码
if(pfun->defined==1)
{
tfun.flushargs();
genFunhead();
}
}
else//函数声明过了
{
fun_record * pfun=fun_map[tfun.name];//取得之前声明的函数信息
//验证函数声明
if(pfun->equal(tfun))
{
//参数匹配,正常声明
if(tfun.defined==1)//添加函数定义
{
if(pfun->defined==1)//已经定义了
{
//重复定义错误,覆盖原来的定义,防止后边的逻辑错误
semerror(fun_redef);
//函数形式完全相同,不需要更改函数记录,刷新参数即可
tfun.flushargs();
}
else
{
//正式的函数定义
pfun->defined=1;//标记函数定义
tfun.flushargs()
//函数定义生成函数头代码
genFunhead();
}
}
return ;
}
else
{
//插入新的定义声明
fun_record * pfun=new fun_record(tfun);
delete fun_map[tfun.name];//删除旧的函数记录
fun_map[tfun.name]=pfun;//插入tfun 信息到堆中
//参数声明不一致++
if(tfun.defined==1)//定义和声明不一致
{
semerror(fun_def_err);
tfun.flushargs();
}
else//多次声明不一致
{
semerror(fun_dec_err);
}
}
}
}
6.2 break、continue语句的位置
根据语法规则,break和continue语句只能出现在循环体内部,然而语法定义中把这两种语句作为正常语句处理,所以需要在语义处理中对他们的位置进行合法性检查。
在出现循环语句的时候,为该循环设置一个唯一的标识ID,将ID的引用传递给循环体的复合语句模块,即使出现循环嵌套,复合语句的也总能获得最内层的循环的ID。在复合语句中,若出现break或者continue语句时,检测该ID是否为0。若ID为0,说明没有循环语句为复合语句传递参数,报告语义错误;否则,接收的ID即循环体的ID,表示break或者continue语句合法,由于循环体生成代码时的标号名称为“@whileID”或者“@whileID_exit”,所以,此时也为break语句和continue语句提供了跳转地址的信息。
6.3 return语句返回值类型
根据语法规则,return语句可以出现在函数体的任何位置,在检测到return语句时,产生函数退出的代码。但是,在函数体内部可能会出现多层的复合语句,而在函数的第一级作用域内没有return语句,从而导致函数生成的代码没有退出语句。
所以,为了保证程序的正常执行,必须在出现return语句的同时,检测作用域的级别,若为1则正常,否则就是内部复合语句的return,此时函数记录的hasret字段不能置为1。同时,还要return语句返回值和函数定义的类型匹配,本系统要求它们严格匹配,不进行默认的转换。
另外,return语句生成的代码中会强制恢复堆栈指针,因此不会导致程序堆栈空间崩溃。
6.4 函数调用语句实参列表的合法性
{
var_record*pRec=NULL;
if(errorNum!= 0) // 有错误,不处理
return NULL;
if(fun_map.find(fname)!=fun_map.end()) // 有函数声明,就可以调用
{
fun_record*pfun=fun_map[fname];
// 匹配函数的参数
// 实参列表是共用的,因此需要动态维护
if(real_args_list.size()>=pfun->args->size()) // 实参个数足够时
{
int l=real_args_list.size();
int m=pfun->args->size();
for( int i=l- 1,j=m- 1;j>= 0;i--,j--)
{
if(real_args_list[i]->type!=(*(pfun->args))[j])
{
semerror(real_args_err);
break;
}
else // 匹配
{
}
}
// 产生函数返回代码
if(pfun->type!=rsv_void) // 非void函数在函数返回时将eax的数据放到临时变量
{ pRec=tfun.create_tmpvar(pfun->type, 0,var_num); // 创建临时变量
if(pfun->type==rsv_string) // 返回的是临时string,必须拷贝
{
var_record empstr;
string empname= "";
empstr.init(rsv_string,empname);
pRec=genExp(&empstr,addi,pRec,var_num);
}
}
// 清除实际参数列表
while(m--)
real_args_list.pop_back();
}
else
{
semerror(real_args_err);
}
}
else
{
semerror(fun_undec);
}
return pRec;
}
6.5 赋值语句的类型转换
七、 代码生成
代码生成的主要功能如下:
(1)根据相应的语义动作产生代码
(2)结合运行时存储实现对应语义的翻译
7.1 表达式
本系统的表达式规则全是双目运算,所以表达式处理的原则是根据两个操作数的类型和操作符计算出结果临时变量的类型,然后将结果的引用返回,供包含表达式的语句使用。
在表达式的计算中要考虑类型转换的问题:
(1)void类型不参加任何运算。
(2)任意非void类型和string类型的+(连接)运算结果都是string类型,而且string类型只能参加+运算,其它运算都是非法的。
(3)在表达式计算中,char类型默认转换为int类型参与运算。
(4)int类型可以参与所有的运算。
1.变量访问规则
基本类型变量存储形式简单,全局变量在数据段,根据数据段生成规则,可以用变量名直接寻址([@var_name]);局部变量在堆栈段,根据变量记录字段的localAddr可以得到变量地址相对于ebp指针的偏移,所以寻址为基址寻址[ebp+localAddr],当然输出的时候要注意localAddr的符号。
string类型因为使用了辅助数据栈,访问方式较复杂。辅助数据栈是用来专门存储局部字符串内容而专门构建的。因为字符串长度无法在编译的时候进行跟踪,将临时字符串的内容存储在系统栈中将导致在字符串内容进栈之后变量无法确定自己的地址,即相对于ebp的偏移量。所以将字符串内容存储在辅助数据栈里,而其地址作为双字存储在系统栈中。标准编译器一般对复杂数据类型会专门开辟堆空间进行存储,但是由于本编译器复杂数据类型只有string类型,相对简单,所以就不用堆而用栈存储。
全局string变量是固定在数据段中长度为255字节的区域,通过变量名@str_name可以访问该区域的首地址,通过@str_name_len可以获得串的长度。
对于字符串常量,则是根据它在文字池中的ID来访问的,@str_ID获得首地址,@str_ID_len获得长度。
局部string被倒序地压入辅助数据栈中,通过[ebp+localAddr]得到的是string内容在辅助数据栈的基址,而且该地址指向内存区域的内容为string的长度,以该内容减去长度的值为基址,按照递增的方式对内存访问string长度个区域就能获得string的内容。局部string的存储访问原理如图7-1所示:

图 7-1 string类型变量访问规则
2.四则运算
若表达式形式为:oprand1 + oprand2,且是基本类型的运算,那么,通过变量的访问规则可以获得oprand1和oprand2的内容,分别存放在eax和ebx中,然后使用add eax,ebx指令将表达式计算出来,最后将eax的内容写入临时变量的内容中。其它的四则运算则类似,只是把运算指令分别修改为sub、imul、idiv。
3.关系运算
与四则运算类似,除了在eax,ebx存储操作数的内容外,还要使用cmp eax,ebx指令进行比较,然后还需要根据运算符的含义使用恰当的jcc跳转命令,而跳转分支执行的语句是对eax进行写1或者写0操作。最后再把eax值写入临时变量中作为关系表达式结果。
4.字符串连接
如果操作数中出现了string类型,本系统限定string只能参与连接运算,运算结果会同时使用堆栈和辅助数据栈,为了方便临时结果字符串压入辅助数据栈,先把oprand2的内容压入辅助数据栈,再把oprand1的内容压入辅助数据栈。
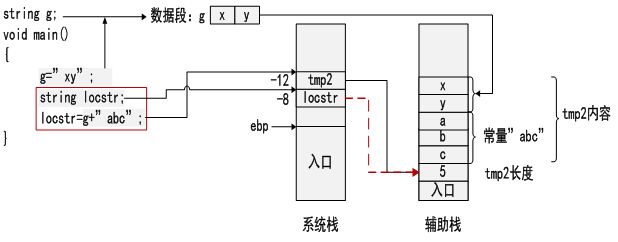
图7-2 string连接运算
在把oprand2内容压入辅助数据栈之前需要先压入一个字节的数据,数据内容为oprand2的长度,它是用来存储结果字符串的长度的。长度被压入后需要将其内存地址写入到结果临时变量在系统栈的内存中去,以用来访问该结果。因此在压入oprand1的时候需要先读取长度,和oprand1的长度相加后再写回,最后在压入oprand1的内容。这样结果字符串就能正确地被访问了。字符串连接方式可以参照图7-2。
另外需要注意的是字符串连接的操作数类型和存储方式可能不尽相同,所以对操作数的访问要遵循变量的访问规则。如果操作数不是字符串类型,那么就需要对其默认转换。对数字要通过除10取余的方式将数字位倒序压入辅助数据栈,对字符则是把其看作一个长度的字符串常量进行连接即可。
7.2 赋值语句
赋值语句会对变量类型检查,首先,void类型不能参与赋值运算;其次,要对赋值变量的类型默认转换为赋值对象的类型。
翻译赋值语句时,编译器先访问赋值对象的类型,如果赋值对象是全局string类型,则先把赋值表达式的内容转换为临时字符串,再把字符串的内容拷贝到全局string对应的数据段中,修改其长度。如果被赋值对象是局部string类型,则直接把临时字符串的地址替换为局部string的地址。
如果赋值对象是基本非void类型,则把赋值变量的内容写入到赋值对象地址对应的内存。
7.3 循环、分支语句
编译到循环语句时,系统会为循环语句设置一个唯一的标识ID,然后根据该ID生成循环开始标签(形如@while_ID)。继而记录循环开始前堆栈指针,再对循环条件表达式进行翻译,为表达式结果产生比较跳转指令,为0则跳转到循环结束位置。接着对循环体的复合语句的代码翻译,然后生成跳转到循环开始标签的指令。最后恢复运行时堆栈状态,生成循环退出标签(形如@while_ID_exit)。若在循环体内遇到break语句,编译器根据循环ID生成跳转到循环结束标签的指令,若遇到continue语句,编译器会生成跳转到循环开始标签的指令。当然,在跳转之前,要根据循环开始记录的堆栈指针恢复堆栈状态。
编译遇到分支语句时,编译器先保存if开始前的栈指针,然后对条件表达式的内容翻译,产生为0 跳转到else的指令。然后对if的复合语句翻译,恢复栈指针,生成跳转到else结束位置的指令。接着编译器先生成else开始标签,恢复if因为表达式计算修改的栈指针,再生成else复合语句指令,恢复栈指针,生成else结束标签。
针对循环、分支代码辅助栈的变化情况,参照图7-3。

图 7-3 循环分支语句运行时存储规则
7.4 函数定义、return语句
函数定义的代码分为函数头部和函数尾部,所有函数定义的翻译都需要生成进栈代码和出栈代码,即函数头部和函数尾部。
函数头部代码在Intel指令集中可以用enter指令代替,它的功能和指令组push ebp 、mov ebp,esp 等价。函数尾部代码也可以用指令leave代替,它和指令组mov esp,ebp pop ebp 等价,最后还要有ret指令让函数返回。之所以这么做就是防止对push,pop指令的误操作导致函数栈的崩溃,只要ebp不被修改,函数总能正确地返回。
另外,由于添加了辅助数据栈的因素,编译器还要额外的为这个栈进行恢复操作,以和系统栈同步。所以在编译器默认数据中有两个32bit的变量保存着辅助数据栈的“esp”、“ebp”。在函数头部和尾部的操作与系统栈类似。
依照gcc的代码生成规则,return语句会把返回值保存在eax寄存器中。对于基本类型,只需要将变量的值mov到eax即可。但是对于string变量还要做一步处理,由于全局string和局部string存储结构的差别,在返回字符串类型之前,要把全局string的内容压入辅助数据栈,按照局部string类型返回。但是这么做必须在函数调用的时候把字符串及时拷贝出来,因为return返回后函数的栈指针会发生变化,数据有可能被刷新。
除了把返回值写入eax,return语句还需要把函数的尾部代码加上以保证函数能正确返回。
7.6 函数调用
函数调用翻译步骤如下:
(1)生成实参的表达式计算指令。
(2)生成实参进栈代码。
(3)使用call指令产生函数调用。
(4)恢复参数进栈之前的栈指针。
(5)若函数返回值是string类型,需要拷贝string的内容。
实参列表保存在符号表的链表对象中,在调用函数之前,需要倒序遍历实参列表,访问实参临时变量内容,将内容压入系统栈中,并对栈指针字节的变化计数。产生调用指令后,需要恢复栈指针,把esp加上刚才的计数值就能恢复栈的状态,另外还要根据实参列表的个数弹出实际参数记录,保证实参列表的动态平衡。
7.7 输入、输出
本系统没有系统库的支持,所以I/O的代码需要自己来实现。系统调用Linux的int 0x80中断转到系统调用例程,根据传递的系统调用号执行输入输出。
对于输入语句,系统先调用Linux的3号系统调用把输入的字符串拷贝到临时缓冲区中,然后根据输入对象的类型将合法的数据拷贝到输入对象的内存中。如果输入对象是string类型,编译器就把输入缓冲区的内容按照赋值语句的规则拷贝到输入对象;如果输入对象是基本类型,编译器就把缓冲区的数据转换为基本类型,再把值拷贝到输入对象。
对于输出语句,系统先把表达式的结果强制转换为string类型,然后将该临时string通过调用Linux的4号系统调用进行标准输出。
7.8 数据段
数据段的信息全部在符号表中,所以符号表是数据段翻译的关键。
符号表的变量记录哈希表保存着所有定义的全局变量,通过遍历变量记录哈希表把变量信息写入数据段。例如变量说明:int a ; 写入数据段格式为 @var_a dd 0\n 。其中??是编译器为变量名加的前缀,由于变量是int类型,需要四个字节存储,所以使用dd定义。另外编译器没有对变量的初始化和变量定义严加区分,所以,所有全局变量一律初始化为0。对于全局string变量,写入数据段需要特殊处理。例如变量声明:string g;生成数据段格式为:
@str_g_len db 0
全局字符串除声明了
255字节的存储空间外还生成了辅助变量存储实际字符串的长度。
串空间保存了所有字符串常量,用它可以生成文字池。标准编译器会把字符串常量保存在字符串表中,段名.strtab。本系统为了使段结构统一,将字符串常量输出到数据段中,例如串“a\nb”,它在串空间的ID假如为3,生成格式如下:
@str_3_len equ 3
针对字符串常量的特殊字符,在生成的时候不能直接输出,必须将特殊字符的ASCLL码写入目标文件以使得汇编器能正常识别特殊字符。
对于外部变量,本系统自定义了一种规则:同样生成数据段对应的记录,不过初始值需要改为1,以通知汇编器这是一个外部变量。
7.9 公共模块
该编译器将程序公共的模块抽取出来单独生成一个汇编文件common.s,供其他的汇编文件使用。该文件数据段.data包括系统必须的存储结构,如输入缓冲区和辅助数据段。
输入缓冲区输出格式为:
@buffer_len dd 0
辅助数据栈信息输出格式为:
@s_ebp dd 0
另外,文件输出了.bss段,该段包含了辅助数据栈空间,使用.bss段,这样做可以节省不少磁盘空间,其格式为:
@s_base:
公共模块的.text段有点类似C语言的crt,不过功能很简单,就是保留一些函数和调用主函数main。保留的函数有@ str_2long用于提示字符串过长,@procBuf用于处理输入缓冲区。主函数调用格式为:
_start:
call main
mov ebx, 0
mov eax, 1
int 128
至此,代码生成工作的主要内容阐述完毕。
八、 编译实例
这里使用一个汉诺塔的程序测试一下编译器的效果,其源代码main.c如下:
int main()
{
int n;
out<< " 输入盘子个数: ";
in>>n;
hanoi( " A ", " B ", " C ",n);
return 0;
}
void hanoi( string a, string b, string c, int n)
{
if(n== 0)
{
return;
} else{}
hanoi(a,c,b,n- 1);
out<< " Move "+n+ " :\t[ "+a+ " --> "+c+ " ]\n ";
hanoi(b,a,c,n- 1);
}
使用本编译器编译,编译命令为./cit main.c hanoi -s。运行效果如下:
命令格式如下:

图8-1 编译器命令
编译过程如下:
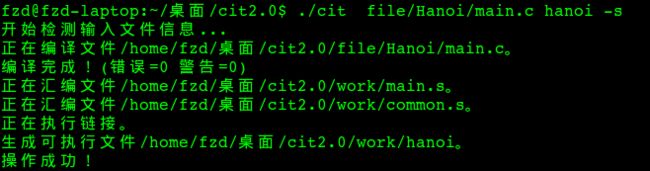
图8-2 编译过程
执行一下,这里提前看看自己的生成的可执行文件(汇编过程以后会介绍):

图8-3 运行效果
如果需要查看具体的编译信息,只需要打开对应的编译开关即可。
例如词法分析信息:
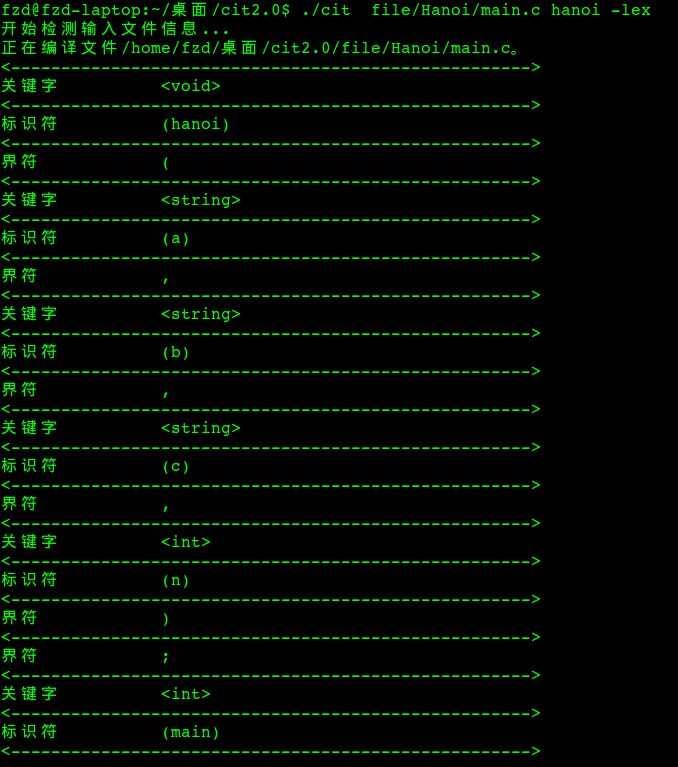
图8-3 词法分析
语法分析信息:
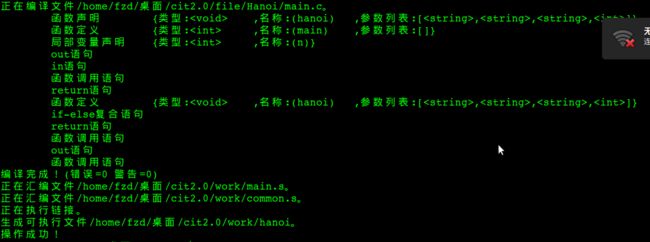
图8-4 语法分析
语义处理信息:
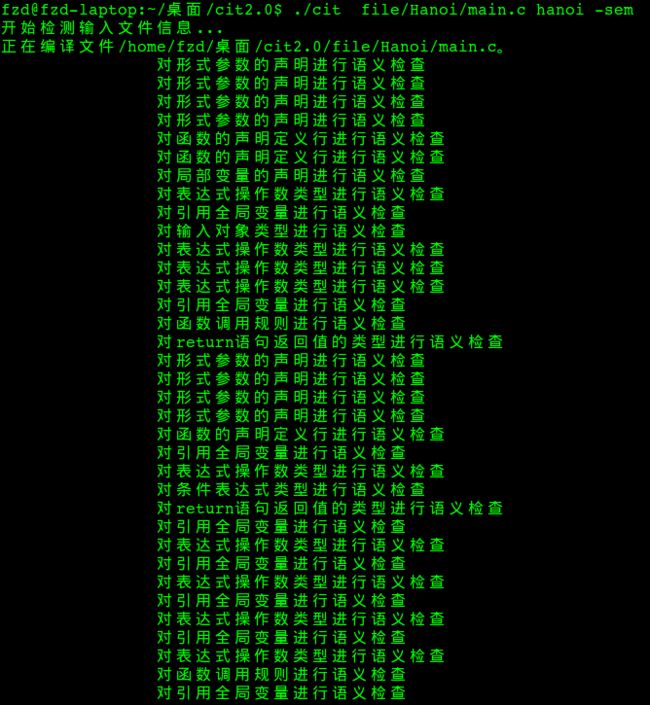
图8-5 语义处理
符号表信息:

图8-6 符号表
代码生成信息:
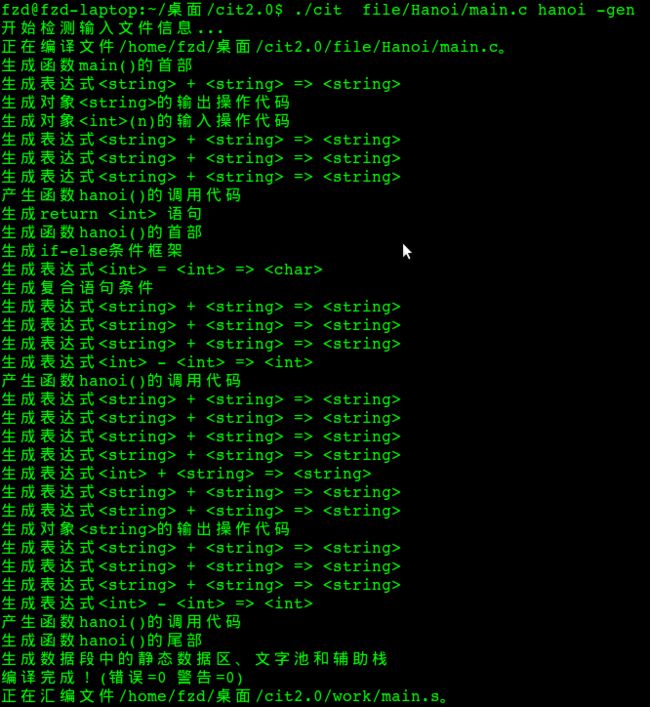
图8-7 代码生成
生成的汇编文件为common.s和main.s代码如下:
common.s文件:
@str2long:
mov edx,@str_2long_data_len
mov ecx,@str_2long_data
mov ebx, 1
mov eax, 4
int 128
mov ebx, 0
mov eax, 1
int 128
ret
@procBuf:
mov esi,@buffer
mov edi, 0
mov ecx, 0
mov eax, 0
mov ebx, 10
@cal_buf_len:
mov cl,[esi+edi]
cmp ecx, 10
je @cal_buf_len_exit
inc edi
imul ebx
add eax,ecx
sub eax, 48
jmp @cal_buf_len
@cal_buf_len_exit:
mov ecx,edi
mov [@buffer_len],cl
mov bl,[esi]
ret
global _start
_start:
call main
mov ebx, 0
mov eax, 1
int 128
section .data
@str_2long_data db " 字符串长度溢出! ", 10, 13
@str_2long_data_len equ 26
@buffer times 255 db 0
@buffer_len db 0
@s_esp dd @s_base
@s_ebp dd 0
section .bss
@s_stack times 65536 db 0
@s_base:
main.s文件:
main:
push ebp
mov ebp,esp
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
mov ebx,[@s_ebp]
push ebx
mov [@s_ebp],esp
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
; 函数头
push 0
push 1
; 为@tmp_string_1产生输出代码
push - 1
; ----------生成常量string@tmp_string_1的代码----------
mov eax,[@s_esp]
mov [@s_esp],esp
mov esp,eax
mov eax,@str_1_len
…………
hanoi:
push ebp
mov ebp,esp
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
mov ebx,[@s_ebp]
push ebx
mov [@s_ebp],esp
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
; 函数头
push 0
push 0
mov eax,[ebp+ 20]
mov ebx,[ebp- 4]
cmp eax,ebx
je @lab_base_cmp_28
mov eax, 0
jmp @lab_base_cmp_exit_29
@lab_base_cmp_28:
mov eax, 1
@lab_base_cmp_exit_29:
mov [ebp- 8],eax
mov eax,[ebp- 8]
cmp eax, 0
je @if_1_middle
mov ebx,[@s_ebp]
mov [@s_esp],ebx
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
pop ebx
mov [@s_ebp],ebx
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
mov esp,ebp
pop ebp
ret
mov esp,ebp
jmp @if_1_end
@if_1_middle:
mov esp,ebp
mov esp,ebp
@if_1_end:
push - 1
; ----------生成动态stringa的代码----------
mov eax,[@s_esp]
mov [@s_esp],esp
mov esp,eax
mov ebx,[ebp+ 8]
mov eax, 0
…………
; 函数尾
mov ebx,[@s_ebp]
mov [@s_esp],ebx
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
pop ebx
mov [@s_ebp],ebx
mov ebx,[@s_esp]
mov [@s_esp],esp
mov esp,ebx
mov esp,ebp
pop ebp
ret
section .data
@str_1 db " 输入盘子个数: "
@str_1_len equ 21
@str_2 db " A "
@str_2_len equ 1
@str_3 db " B "
@str_3_len equ 1
@str_4 db " C "
@str_4_len equ 1
@str_5 db " Move "
@str_5_len equ 5
@str_6 db " : ", 9, " [ "
@str_6_len equ 3
@str_7 db " --> "
@str_7_len equ 5
@str_8 db " ] ", 10
@str_8_len equ 2
section .bss
九、 总结
通过以上的叙述,比较详细的介绍了一个编译器的实现流程和具体所牵涉的细节,相信对想了解编译器内部结构的人有所帮助。不过,由于本编译器的结构是面向之前所介绍的静态链接器的,因此生成的汇编代码属于自定义范畴,因此不会和gcc等主流软件兼容,那么如何测试生成代码的正确性呢?后边就准备介绍如何自己构造一个汇编器,将这些汇编代码转换为二进制文件,使用静态链接器链接为可执行文件后,执行一下便能知道结果是否正确了!