大家或许知道,Python 为了提高内存的利用效率,采用了一套共用对象内存的分配策略。
例如,对于那些数值较小的数字对象([-5, 256])、布尔值对象、None 对象、较短的字符串对象(通常 是 20)等等,字面量相等的对象实际上是同一个对象。
# 共用内存地址的例子
a = 100
b = 100
s = "python_cat"
t = "python_cat"
id(a) == id(b) # 结果:True
id(s) == id(t) # 结果:True我很早的时候曾写过一篇《Python中的“特权种族”是什么?》,把这些对象统称为“特权种族”,它们是 Python 在内存管理机制上使用的优化技巧。
前不久,我还写了一篇《Python 内存分配时的小秘密》,也是介绍内存管理的技巧。
这两篇文章有所区别:旧文主要涉及了内存共用与对象驻留的机制,而新文介绍的是内存分配、动态扩容以及内存回收的相关机制。
它们令我不由自主地想到两个词:共享经济与供需平衡。
如果你没有读过那两篇文章,我强烈建议你先回看一下,然后再看看我的联想是否有道理:那几类特权种族对象其实是在共享内存,表面上的不同对象,其实是在循环利用;至于供需平衡也好理解,创建某些对象时,按照预期的诉求去分配内存,在扩容时则灵活调节,达到了供需之间的平衡。
透过现象看本质,Python 可以很有趣。
但是,Python 的有趣之处还不止于此,本文要继续分享另一种内存管理机制,在某种程度上,它实现了共享经济与供需平衡的融合,我们从中可揭开 Python 的另一重身份……
1、不可变对象的共享经济
上面列出的"特权种族"都是不可变对象(而“供需平衡”主要出现于可变对象),对于这些不变的对象,当出现多处使用时,共用一个对象似乎是种不错的优化方法。
我曾有一种猜想:Python 的不可变对象都可能是特权种族。
我没有试图去完全证实它,本文只想考察其中一种不可变对象:元组。它是不可变对象,那么,是否有共用对象的机制呢?
下面把它跟列表作一下对比:
# 空对象的差别
a = []
b = []
c = ()
d = ()
print(id(a)==id(b)) # 结果:False
print(id(c)==id(d)) # 结果:True由此可见,两个空列表是不同的对象,而两个空元组其实是同一个对象。这至少说明了,空元组在内存中只有一个,它属于已提到的特权种族。
将实验延伸到集合与字典,它们是可变对象,你会发现结果跟列表一样,存在多个副本,即不是特权种族。我就不举例了。
由上述的实验结果,还能引出两个问题,但是它们偏离了本文主题,我不打算深入辨析,简单列一下:
- 除了空元组,还有什么样的元组是“特权种族”?(PS:从元素的数量、类型、元素自身的大小考虑,就我小范围试验,还没发现。所以,空元组是独特的唯一?)
- 编译期与运行期有所区别,这在之前写字符串的 intern 机制时(《Intern机制的软肋》)也分析过。(PS:print(id([]) == id([])),结果为 True,与上例先赋值再比较不同。)
2、可变对象的共享经济
空元组体现了共享经济,但由于它是不可变对象,所以不存在动态扩容,就只体现了极少的供需平衡。
作为对照,列表等可变对象充分表现了供需平衡,却似乎没办法体现共享经济。
比如说,我们把一个列表想象成一个可自增的杯子(毕竟它是某种容器),再把它的元素想象成不同种类的液体(水、可乐、酒……)。
那么,我们的问题是:两杯东西是否可以共享为一个对象呢?或者说,有没有可能共享那只杯子呢?这样就可以节省内存(在那篇讲小秘密的文章中展示过:“空杯子”占用的内存可不少),提升效率啦。
对于第一个问题,答案为否,验证过程略。对于第二个问题,在上一节中,我们已验证过两个空杯子(即空列表),答案也为否。
但是,第二个问题还有其它的可能!下面让我们换一种实验方法:
# 实验版本:Python 3.6.1
a = [[] for i in range(4)]
print(id(a))
for i in range(len(a)):
print(f'{i} -- {id(a[i])}')
# a[i] = 1 # PS:可去除注释,再执行一次,结果的顺序有差别
del a
print("after del")
b = [[] for i in range(4)]
print(id(b))
for i in range(len(b)):
print(f'{i} -- {id(b[i])}')以上代码在不同环境中,执行结果可能有所差异。我执行的一次结果如下:
2012909395656
0 -- 2012909395272
1 -- 2012909406472
2 -- 2012909395208
3 -- 2012909395144
after del
2012909395656
0 -- 2012909395272
1 -- 2012909406472
2 -- 2012909395208
3 -- 2012909395144分析结果可知:列表对象在被回收之后,并不会彻底消除,它的内存地址会传递给新创建的列表,也就是说,新创建的列表其实共享了旧列表的内存地址!
再结合前面的例子,我们可以说,先后静态创建的两个列表会分配不同的内存地址,但是,经过动态回收之后,先后创建的列表可能是同一个内存地址!(注意:这里说的是“可能”,因为在新列表创建前,若有其它地方也在创建列表,那后者可能夺去先机。)
延伸到其它基本的可变对象,例如集合与字典,也有同样的共享策略,其目的显而易见:循环利用这些对象的“残躯”,可以避免内存碎片,提高执行性能。
共享一只杯子,总比重新创造一只杯子,要更高效便捷,对吧?
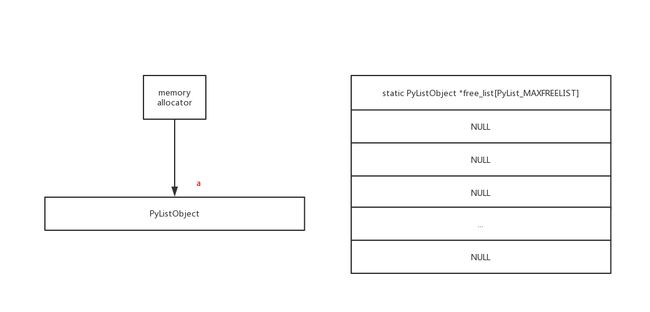
Python 解释器在实现这个机制时,使用了一个叫做free_list 的全局变量,其工作原理是:
- 当创建新的对象时,则检查 free_list 内是否有可用对象,有则取出使用,没有则创建
- 当这些对象被析构时,则检查 free_list 是否有剩余空间,有则存入其中
- 某类对象存入 free_list 时,只保留“躯壳”,而清空其内部所有的元素(即只共享杯子,不共享杯中物)

图片来源:https://dwz.cn/QWD6RxOx
好了,现在我们可以说,列表、集合与字典这些可变对象,它们都不是前文所说的特权种族,但是,在它们背后都藏着循环使用的共享思想,这一点却是相通的。
Python 解释器在内存管理上真是煞费苦心啊,在那些司空见惯的基本对象上,它施加了诸多的小魔法,在我们毫不觉察的时候,它们有条不紊地运作,而当我们终于见识清楚后,就不得不感叹它的精妙了。
Python 算得上是一个精打细算的“经济学家”了。
回顾全文,最后作一个小结:
- 较小的数字、较短的字符串、布尔值与空元组等不可变对象,它们存在着“共享经济”的机制,提升了内存的使用效率
- 列表、集合与字典等可变对象,它们存在着预分配及超额分配等“供需平衡”的机制,提升了内存的分配效率
- 列表等对象还存在着共享“容器外壳”的机制,循环利用空闲资源,综合提升程序性能
PS:本文写作过半时,我觉得应该把它写入“喵星来客”系列,但思前想后,最终作罢了(主要是懒)。它们的思辨力及洞察力是一脉相承的,若你喜欢本文的话,我推荐阅读“喵星来客”系列(其中两篇):
Python对象的身份迷思:从全体公民到万物皆数
Python对象的空间边界:独善其身与开放包容

公众号【Python猫】, 本号连载优质的系列文章,有喵星哲学猫系列、Python进阶系列、好书推荐系列、技术写作、优质英文推荐与翻译等等,欢迎关注哦。