
前言
Java 5 是Java 历史上非常重要的一个版本,它提供了泛型、for-each、自动装箱和拆箱、枚举、可变参数、静态导入、注解以及本文的主角java.util.concurrent包(后文简称为J.U.C)。说起J.U.C不得不提它的作者Doug Lea,Doug Lea是对Java世界最具影响力的人之一。我们必须要感谢Doug Lea在Java 5中提供了他里程碑式的杰作J.U.C,它的出现让使用Java进行并发编程有了更多的选择和更好的工作方式。本文是作者自己对J.U.C相关API使用的理解与总结,不对之处,望指出,共勉。
全貌

J.U.C主要包括 : 可选的非阻塞解决方案 、显示锁、原子类、更好的线程安全的容器 、线程池和相关的工具类 。
浅析
J.U.C提供的东西还是比较多的,由于篇幅有限,下文只对一些常见、常用的类做一浅析,要想更全面深入的了解J.U.C还需自行查找相关书籍、资料或者阅读源码。
TimeUnit
首先介绍一下TimeUnit这个贯穿整个J.U.C的枚举,说到此枚举我不得不对Doug Lea的巧妙设计发出由衷的赞叹,它的出现使Java并发编程中对于时间的控制更加人性化和可读。Java中关于时间、日期的API一直饱受诟病,直到Java 8新日期、时间API的出现才有了较大改善。
public class TimeUnitTest {
public static void main(String[] args) throws InterruptedException {
//睡眠13分钟
TimeUnit.MINUTES.sleep(13);
//Thread.sleep(780000);//这样写你知道是多久吗?
//Thread.sleep(13*60*1000);//这样写会稍微好些
//睡眠1小时
TimeUnit.HOURS.sleep(1);
//Thread.sleep(3600000);
TimeUnitTest test = new TimeUnitTest();
Thread thread = new Thread(() -> test.work());
//10秒内Join
TimeUnit.SECONDS.timedJoin(thread,10);
//thread.join(10000);
}
public synchronized void work() {
System.out.println("Begin Work");
try {
//等待30秒后,自动唤醒继续执行
TimeUnit.SECONDS.timedWait(this, 30);
//wait(30000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Work End");
}
}
Lock
在Java 5 之前只能使用synchronized关键字实现的隐式锁来保证线程安全,由于其底层实现过“重”(详见前文),性能较差且缺乏灵活性(线程要么得到锁,要么阻塞,没有其他的可能性),所以Java 5 提供了性能更好、灵活性更高的显示锁(加锁、解锁都可以显式的控制)供开发者使用。下面是Lock接口的简介。
//获取锁
void lock();
//获取锁,且当前线程可被中断
void lockInterruptibly() throws InterruptedException;
//尝试获取锁,获取到锁返回true, 否则false
boolean tryLock();
//在一定时间内持续尝试(阻塞)获取锁,获取到锁返回true,超时还未获取到返回false。
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
//释放锁
void unlock();
//在当前锁上创建一个条件对象,用于对线程进行更灵活的控制,Condition的用法和Object的wait、notify、notifyAll比较类似。
Condition newCondition();
标准用法(伪代码)
Lock lock = ...;
...
lock.lock();//获得锁
try{
// doSomething..
} finally{
lock.unlock(); /释放锁(finally是释放资源的最佳位置)。
}
...
Lock lock = ...;
...
//if(lock.tryLock(10,TimeUnit.SECONDS)) {//尝试在10秒内获取锁
if(lock.tryLock()) {//尝试获取锁
try{
//doSomething..
}finally{
lock.unlock(); //释放锁
}
}else {//如果不能获取锁
//doSomething..
}
...
ReentrantLock是该接口的默认实现,从名字也可以看出它是一个可重入的锁,作用和synchronized关键字类似,但性能、灵活性要更高一点。下面是一个简单的使用测试。
public class ReentrantLockTest {
private final Lock lock = new ReentrantLock();
private String content = "Old";
public void write() {
lock.lock();
//由于ReentrantLock是可重入锁,所以可以重复的加锁。
//lock.lock();
//lock.lock();
System.out.println(Thread.currentThread() +" LOCK");
try {
try {
//模拟方法需要执行100毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
content = "New";
System.out.println(Thread.currentThread() +" Write content to: " + content);
} finally {
System.out.println(Thread.currentThread() +" UNLOCK");
lock.unlock();
//进行多少次加锁操作,也需要对应多少次解锁操作。
//lock.unlock();
//lock.unlock();
}
}
public void read() {
lock.lock();
System.out.println(Thread.currentThread() +" LOCK");
try {
try {
//模拟方法需要执行100毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() +" Read content is: " + content);
} finally {
System.out.println(Thread.currentThread() +" UNLOCK");
lock.unlock();
}
}
public static void main(String[] args) {
final ReentrantLockTest test = new ReentrantLockTest();
// 使用Java 8 lambda 简化代码
new Thread(() -> test.write()).start();
new Thread(() -> test.read()).start();
new Thread(() -> test.read()).start();
/**
不使用锁的输出:
Thread[Thread-1,5,main] Read content is: Old
Thread[Thread-2,5,main] Read content is: Old
Thread[Thread-0,5,main] Write content to: New
使用锁后:
Thread[Thread-0,5,main] LOCK
Thread[Thread-0,5,main] Write content to: New
Thread[Thread-0,5,main] UNLOCK
Thread[Thread-1,5,main] LOCK
Thread[Thread-1,5,main] Read content is: New
Thread[Thread-1,5,main] UNLOCK
Thread[Thread-2,5,main] LOCK
Thread[Thread-2,5,main] Read content is: New
Thread[Thread-2,5,main] UNLOCK
**/
}
}
由于ReentrantLock无论是读还是写操作,每次都只能有一个线程可以获得锁,读操作多时性能较差,所以J.U.C提供了ReadWriteLock接口来进行改善,它将读和写操作分开,分成两个锁来分配给线程,从而使得多个线程可以同时进行读操作。下面是该接口的简介。
//读写锁允许同时多个线程读, 或最多一个线程写
public interface ReadWriteLock {
//获得读锁
Lock readLock();
//获得写锁
Lock writeLock();
}
ReentrantReadWriteLock是该接口的默认实现,下面用其来代替ReentrantLockTest中的ReentrantLock看一下效果。
public class ReentrantReadWriteLockTest {
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private String content = "Old";
public void write() {
lock.writeLock().lock();
System.out.println(Thread.currentThread() +" LOCK");
try {
try {
//模拟方法需要执行100毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
content = "New";
System.out.println(Thread.currentThread() +" Write content to: " + content);
} finally {
System.out.println(Thread.currentThread() +" UNLOCK");
lock.writeLock().unlock();
}
}
public void read() {
lock.readLock().lock();
System.out.println(Thread.currentThread() +" LOCK");
try {
try {
//模拟方法需要执行100毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() +" Read content is: " + content);
} finally {
System.out.println(Thread.currentThread() +" UNLOCK");
lock.readLock().unlock();
}
}
public static void main(String[] args) {
final ReentrantReadWriteLockTest test = new ReentrantReadWriteLockTest();
// 使用Java 8 lambda 简化代码
new Thread(() -> test.write()).start();
new Thread(() -> test.read()).start();
new Thread(() -> test.read()).start();
/**
输出:
Thread[Thread-0,5,main] LOCK
Thread[Thread-0,5,main] Write content to: New
Thread[Thread-0,5,main] UNLOCK
Thread[Thread-1,5,main] LOCK
Thread[Thread-2,5,main] LOCK
Thread[Thread-1,5,main] Read content is: New
Thread[Thread-2,5,main] Read content is: New
Thread[Thread-1,5,main] UNLOCK
Thread[Thread-2,5,main] UNLOCK
**/
}
}
从上面的运行结果可以看到两个线程可以同时获得读锁,执行read()方法内的代码。
Lock接口定义了Condition newCondition();方法用于获得Condition接口的实例以便对线程进行更灵活的控制。下面是该接口的简介。
// 使当前线程在接到信号或被中断之前一直处于等待状态,相当于Object的wait()方法
void await()
// 使当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
boolean await(long time, TimeUnit unit)
// 使当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
long awaitNanos(long nanosTimeout)
// 使当前线程在接到信号之前一直处于等待状态。
void awaitUninterruptibly()
// 使当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态。
boolean awaitUntil(Date deadline)
// 对一个等待线程发出唤醒信号。
void signal()
// 对所有等待线程发出唤醒信号。
void signalAll()
Condition内方法的用法与Object内wait()、notify()、notifyAll()方法的用法(详见前文)类似,Object提供的这些方法需要与synchronized关键字修搭配使用,而Condition内的方法则需要与Lock搭配使用。下面是一个简单的使用测试,可以与前文使用wait()、notifyAll()的使用例子(查看源码)做一下比较。
public class ConditionTest {
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
public void work() {
lock.lock();
try {
try {
System.out.println("Begin Work");
condition.await();
System.out.println("Begin End");
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
lock.unlock();
}
}
public void continueWork() {
lock.lock();
try {
condition.signalAll();
} finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
ConditionTest test = new ConditionTest();
new Thread(() -> test.work()).start();
//等待3000毫秒后唤醒,继续工作。
Thread.sleep(3000);
test.continueWork();
}
}
Lock基本上可以用来代替synchronized,下面是关于它俩的一些区别与总结。
-
Lock是接口,synchronized是Java关键字。 -
synchronized使用完或遇到异常会自动释放锁,而Lock需要使用者释放,所以最好放在finally代码块内,避免“死锁”。 -
synchronized是非公平锁,而Lock的实现可以选择使用公平锁或非公平锁(公平锁分先来后到顺序,即等待时间较久的线程优先获得锁,非公平锁则不分先来后到的顺序,随便抢)。
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
-
Lock与synchronized实现的锁都是可重入锁。 -
Lock更具灵活性,但用法相对synchronized略显复杂。 - 在竞争资源不激烈的使用场景下
Lock与synchronized性能类似,而当竞争资源非常激烈时(即有大量线程同时竞争)Lock的性能要远优于后者。
Atomic
原子性问题是Java并发编程要考虑的问题之一,比如类似i++这样的自增操作在多线程并发时是难以保证操作是原子性的,下面是对该问题的一个测试。
public class AtomicityProblemTest{
public static int sharedValue;
//每次将sharedValue的值增加10
public static void increment() {
for (int i = 0; i < 10; i++) {
sharedValue++;
}
}
public static void main(String[] args) throws InterruptedException {
int maxThreads = 10000;
for (int i = 0; i < maxThreads; i++) {
Thread thread = new Thread(() -> increment());
thread.start();
}
Thread.sleep(3000);//等待所有子线程执行完成
Assert.assertEquals(sharedValue, 10000 * 10);
//Exception in thread "main" java.lang.AssertionError: expected:<99980> but was:<100000>
}
}
在Java 5之前只能使用synchronized关键字来解决,在Java 5之后除了可以通过Lock来实现外,J.U.C还提供了众多Atomic开头的类供使用,它们对常用的Java数据类型进行了原子性封装,比如AtomicInteger类。
public class AtomicIntegerTest {
public static AtomicInteger sharedValue = new AtomicInteger();
//每次将sharedValue的值增加10
public static void increment() {
for (int i = 0; i < 10; i++) {
sharedValue.incrementAndGet();
}
}
public static void main(String[] args) throws InterruptedException {
int maxThreads = 10000;
for (int i = 0; i < maxThreads; i++) {
Thread thread = new Thread(() -> increment());
thread.start();
}
Thread.sleep(3000);//等待所有子线程执行完成
Assert.assertEquals(sharedValue.get(), 10000 * 10);
//Assert Pass
}
}
CountDownLatch
CountDownLatch是J.U.C提供的一个线程同步辅助类,作用和Thread.join()有些类似。CountDownLatch内部维护了一个计数器,在创建实例时需要定义其初始值。当一个线程调用await()方法后将进行等待,直到计数器为零,每执行一次countDown()方法可以将计数器的值减一。下面是一个简单的使用测试(使主线程等待所有子线程执行完后再执行自己的代码),前文关于Thread.join()也有类似的测试(查看源码)。
public class CountDownLatchTest {
static CountDownLatch latch = new CountDownLatch(3);//创建并设置计数器初始值为3
static void work() {
System.out.println(Thread.currentThread().getName() + " Work End");
latch.countDown();//计数器值-1
}
public static void main(String[] args) throws InterruptedException {
new Thread(() -> work()).start();
new Thread(() -> work()).start();
new Thread(() -> work()).start();
latch.await();//当前线程(主线程)等待计数器值为0,才会执行
System.out.println("Main Thread Work End");
/**
输出:
Thread-0 Work End
Thread-1 Work End
Thread-2 Work End
Main Thread Work End
*/
}
}
CyclicBarrier
CyclicBarrier也是J.U.C提供的一个线程同步辅助类,直译过来就是“环形栅栏”的意思,它可以将一定数量的线程阻塞在“环形栅栏”内,达到临界值后打开“栅栏”让这些线程继续执行,下面这个可能不太恰当的使用测试足以描述它的作用。
public class CyclicBarrierTest {
//定义一个barrier并设置parties,当线程数达到parties后,barrier失效,线程可以继续运行,在未达到parties值之前,线程将持续等待。
static CyclicBarrier barrier = new CyclicBarrier(3,()-> System.out.println("栅栏:“这么多猪,我恐怕扛不住了”"));
static void go() {
System.out.println("小猪[" + Thread.currentThread().getName() + "] 在栅栏边等待其他小猪");
try {
barrier.await();//等待数+1
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("猪到齐了,小猪[" + Thread.currentThread().getName() + "] 与其他小猪一起冲破栅栏");
}
public static void main(String[] args) {
new Thread(() -> go()).start();
new Thread(() -> go()).start();
new Thread(() -> go()).start();
/**
输出:
小猪[Thread-0] 在栅栏边等待其他小猪
小猪[Thread-1] 在栅栏边等待其他小猪
小猪[Thread-2] 在栅栏边等待其他小猪
栅栏:“这么多猪,我恐怕扛不住了”
猪到齐了,小猪[Thread-2] 与其他小猪一起冲破栅栏
猪到齐了,小猪[Thread-0] 与其他小猪一起冲破栅栏
猪到齐了,小猪[Thread-1] 与其他小猪一起冲破栅栏
*/
}
}
Semaphore
Semaphore(信号量),用控制线程对资源的访问,线程要想访问资源需申请获得许可,使用完毕需要释放许可,以便其他线程访问。比如下面这个可能不恰当的使用测试,假设卫生间是一个资源,同时只能被三个人使用,便可以设置信号量的许可数为三,每个人要想使用卫生间首先需要获得许可,使用完毕后需释放许可。
public class SemaphoreTest {
public static void main(String[] args) {
WC wc = new WC();
new Thread(() -> wc.use()).start();
new Thread(() -> wc.use()).start();
new Thread(() -> wc.use()).start();
new Thread(() -> wc.use()).start();
new Thread(() -> wc.use()).start();
/**
输出:
Thread-1 正在使用卫生间
Thread-2 正在使用卫生间
Thread-0 正在使用卫生间
Thread-0 使用完毕
Thread-2 使用完毕
Thread-1 使用完毕
Thread-3 正在使用卫生间
Thread-4 正在使用卫生间
Thread-4 使用完毕
Thread-3 使用完毕
*/
}
}
class WC {
private Semaphore semaphore = new Semaphore(3);//最大线程许可量
public void use() {
try {
//获得许可
semaphore.acquire();
System.out.println(Thread.currentThread().getName() +" 正在使用卫生间");
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName() +" 使用完毕");
} catch (InterruptedException e) {
e.printStackTrace();
} finally{
//释放许可
semaphore.release();
}
}
}
BlockingQueue

BlockingQueue,是J.U.C提供的更好的线程安全容器之一,BlockingQueue是一个在并发环境下非常好用的工具,在调用put()方法向队列中插入元素时,如果队列已满,它会让插入元素的线程等待队列腾出空间;在调用take()方法从队列中取元素时,如果队列为空,取出元素的线程就会阻塞。 在多线程环境中,通过它可以很容易实现数据共享,解决生产者-消费者模型这类问题。下面展示如何通过BlockingQueue来优美的实现生产者-消费者模型(查看其他实现源码)。
public class ProducerConsumerModelBlockQueueImpl {
public static void main(String[] args) {
final int maxSize = 10;//产品最大库存量
BlockingQueue buffer = new LinkedBlockingQueue(maxSize);
ExecutorService es = Executors.newFixedThreadPool(5);
//两个生产者
es.execute(new Producer(buffer));
es.execute(new Producer(buffer));
//三个消费者
es.execute(new Consumer(buffer));
es.execute(new Consumer(buffer));
es.execute(new Consumer(buffer));
es.shutdown();
/**
输出:
...
生产者[pool-1-thread-1]生产了一个产品:MAC
消费者[pool-1-thread-3]消费了一个产品:MAC
消费者[pool-1-thread-4]消费了一个产品:MAC
消费者[pool-1-thread-4]消费了一个产品:MAC
消费者[pool-1-thread-4]消费了一个产品:MAC
生产者[pool-1-thread-2]生产了一个产品:MAC
生产者[pool-1-thread-2]生产了一个产品:MAC
生产者[pool-1-thread-2]生产了一个产品:MAC
...
*/
}
//产品
static class Product {
private String name;
public Product(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
}
//生产者
static class Producer implements Runnable {
private BlockingQueue buffer;
public Producer(BlockingQueue buffer) {
this.buffer = buffer;
}
public void run() {
while (true) {
Product product = new Product("MAC");
try {
buffer.put(product);
System.out.println("生产者[" + Thread.currentThread().getName() + "]生产了一个产品:" + product);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//消费者
static class Consumer implements Runnable {
private BlockingQueue buffer;
public Consumer(BlockingQueue buffer) {
this.buffer = buffer;
}
public void run() {
while (true) {
try {
System.out.println("消费者[" + Thread.currentThread().getName() + "]消费了一个产品:" + buffer.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
推荐阅读:Java中的阻塞队列
CopyOnWriteArrayList

CopyOnWriteArrayList,也是J.U.C提供的更好的线程安全容器之一,它与Collections.synchronizedList(List“简单粗暴”的实现方式不同(使用synchronized对整个容器加锁),CopyOnWriteArrayList是通过进行写操作时创建副本来避免并发访问引起的问题,也就是说任何写操作都会创建一个List的副本,操作完之后将List的引用指向该副本。也就意味着之前已有的迭代器读操作不会碰到意料之外的修改。这种方式对于不要求严格读写同步的场景非常有用,因为它提供了更好的性能。但是也有短板,在写操作频繁时大量的副本会占用较多的内存,典型的拿空间换时间,需要使用者自己来做出取舍。
推荐阅读:Java中的CopyOnWrite容器
ConcurrentHashMap

ConcurrentHashMap,也是J.U.C提供的更好的线程安全容器之一,它与HashTable 或Collections.synchronizedMap(Map“简单粗暴”的实现方式不同(使用synchronized对整个容器加锁),ConcurrentHashMap通过巧妙的内部设计,可以做到进行读操作时不用加锁,进行写操作的时候能够将锁的粒度保持地尽量地小,只需要锁住对应分段的哈希桶即可,而不用对整个容器加锁。
推荐阅读:深入分析ConcurrentHashMap
Callable & Future & Executor
J.U.C提供了一个全新的线程任务接口Callable,它类似于Runnable接口,可以创建一个线程任务,不同的地方在于Callable在执行完毕之后可以将执行结果通过Future返回。同时J.U.C还提供了线程执行工具与线程池,这使得Java并发编程变得更加优雅,线程池的出现也能更好的利用线程资源,这和网络连接池、数据库连接池的初衷是一致的。下面是一个简单的使用测试。
public class ExecutorTest {
public static void main(String[] args) {
//创建固定线程数的线程池
ExecutorService es = Executors.newFixedThreadPool(2);
//执行传统Runnable任务
es.execute(new RunnableTask());
//执行Callable任务并获得任务结果Future
Future future = es.submit(new CallableTask());
try {
System.out.println("Calculate Completed Sum:" + future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
//关键线程池
es.shutdown();
/**
输出:
pool-1-thread-1 Started By Runnable
pool-1-thread-2 Started By Callable
Calculate Completed Sum:2
*/
}
}
class CallableTask implements Callable {
@Override
public Object call() throws Exception {
System.out.println(Thread.currentThread().getName() + " Started By Callable");
//求和
return 1 + 1;
}
}
class RunnableTask implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Started By Runnable");
}
}
上述代码中的Executors是一个创建线程池的工具,它提供了一些静态工厂方法,用于创建常用的线程池,下面是对一些常用的方法的说明。
- newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的大小超过了处理任务所需要的线程,那么就会回收空闲(60秒不执行任务)的线程,如果小于处理任务所需要的线程则会创建新线程,该线程池最大线程数为Integer.MAX_VALUE。 - newFixedThreadPool(int nThreads)
创建固定大小的线程池,如果任务数大于线程数,任务将会被放置在阻塞队列中,该阻塞队列容量为Integer.MAX_VALUE。 - newSingleThreadExecutor()
创建一个单线程的线程池,将任务放在阻塞队列中一个一个执行。 - newScheduledThreadPool(int corePoolSize)
创建一个用于支持定时以及周期性执行任务的的线程池, 可以指定核心线程数,但最大线程数为Integer.MAX_VALUE。
使用Executors创建线程池,在线程数较少或已知的情况下使用还是非常方便的,如果线程数较大且未知,比如使用线程池来处理秒杀这类业务的时候还是慎用,因为其大部分方法提供的线程池最大线程数、阻塞队列容量为Integer.MAX_VALUE,可能会造成OOM。建议在生产中使用时,还是根据业务自行配置比较好,下面对其主要构造器参数做一个简单的介绍。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue)
- corePoolSize
核心线程数,当执行任务时会创建线程,一旦创建则常驻线程池内(不受keepAliveTime参数影响)。 - workQueue
线程工作队列,执行任务时如果核心线程都忙,则将任务放置于工作队列中等待。 - maximumPoolSize
最大线程数,如果执行任务时线程工作队列也满了但线程池内线程数未达到该值会创建新的线程(受keepAliveTime参数影响)来执行该任务,否则抛出异常java.util.concurrent.RejectedExecutionException,拒绝执行。 - keepAliveTime
空闲线程存活时间,超过该时间的空闲线程将被销毁。
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
BlockingQueue workQueue = new LinkedBlockingQueue<>(5);//工作队列容量5
int corePoolSize = 1;//核心线程数1
int maximumPoolSize = 2;//最大线程数2
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, 1, TimeUnit.MILLISECONDS, workQueue);
executor.execute(new TestTask());//执行任务,创建一个核心线程
executor.execute(new TestTask());//核心线程忙,放入队列,队列内任务数+1
executor.execute(new TestTask());//核心线程忙,放入队列,队列内任务数+1
executor.execute(new TestTask());//核心线程忙,放入队列,队列内任务数+1
executor.execute(new TestTask());//核心线程忙,放入队列,队列内任务数+1
executor.execute(new TestTask());//核心线程忙,放入队列,队列内任务数+1
System.out.println("WorkQueue Size:" + workQueue.size());//WorkQueue Size:5,队列满
executor.execute(new TestTask());//核心线程忙,队列也满了,继续新的线程执行任务
System.out.println("PoolSize Size:" + executor.getPoolSize());//PoolSize Size:2,达到最大线程数
executor.execute(new TestTask());//继续执行任务,则抛出异常,拒绝服务
executor.shutdown();
/**
输出:
WorkQueue Size:5
PoolSize Size:2
Exception in thread "main" java.util.concurrent.RejectedExecutionException:
Task juc.TestTask@45ee12a7 rejected from java.util.concurrent.ThreadPoolExecutor@330bedb4
[Running, pool size = 2, active threads = 1, queued tasks = 5, completed tasks = 0]
*/
}
}
class TestTask implements Runnable{
@Override
public void run() {
try {
TimeUnit.DAYS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Fork/Join框架
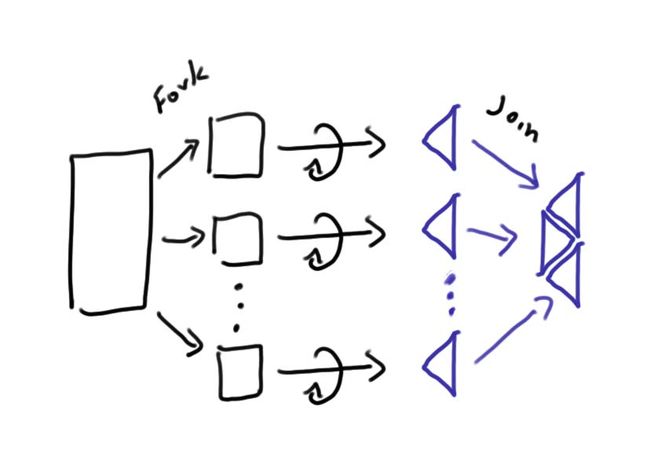
Fork/Join框架是Doug Lea 在Java 7为J.U.C增添的一位新成员,直译过来就是拆解/合并框架,它通过使用分治法(divide-and-conquer)的思想,将一个大的问题拆解为若干个小问题,最后再将所有小问题的解合并起来得到大问题的解。Fork/Join框架主要的目的是为了更好的利用现代多核CPU的运算能力。下面的测试代码使用了Fork/Join框架来计算1到10000的和,当然对于如此简单的任务根本不需要使用Fork/Join框架,因为分支和合并本身也会带来一定的开销,仅作演示而用。
public class ForkJoinTest {
static class Sum extends RecursiveTask {
private static final int THRESHOLD = 10;//可直接求解的临界值
private final long from;
private final long to;
Sum(long from, long to) {
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
long sum = 0;
if ((to - from) < THRESHOLD) {//达到直接求解的临界点,直接进行计算
for (long i = from; i <= to; i++) {
sum = sum + i;
}
} else {//递归分解计算
long mid = (from + to) >>> 1;//取中间值
//以中间值为界将计算任务分解执行
Sum left = new Sum(from, mid);
left.fork();
Sum right = new Sum(mid + 1, to);
right.fork();
//合并计算结果
sum = left.join() + right.join();
}
return sum;
}
}
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future result = forkJoinPool.submit(new Sum(1, 10000));
System.out.println("Sum:" + result.get());//Sum:50005000
}
}
如果你想了解更多有关Fork/Join框架的信息,我推荐你去看看Oracle官网上的一篇文章 Fork and Join: Java Can Excel at Painless Parallel Programming Too!,里面有一个使用例子很有意思,它通过Fork/Join框架来快速计算出某个单词在你电脑磁盘海量文件中出现的频率。
查看本文相关源码
参考
- The Java® Virtual Machine Specification - Java SE 8 Edition
- 深入浅出 Java Concurrency
- 关于Java并发编程的总结和思考
- A Java Fork/Join Framework - Doug Lea
查看《浅析Java并发编程》系列文章目录