Github地址
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Development | 开发 | 1330 | 1660 |
| Analysis | 需求分析(包括学习新技术) | 400 | 600 |
| Design Spec | 生成设计文档 | 60 | 50 |
| Design Reveiw | 设计复审 | 10 | 15 |
| Coding Standard | 代码规范(为开发的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 60 | 50 |
| Coding | 具体编码 | 600 | 700 |
| Code Review | 代码复审 | 60 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 25 |
| Tot | 合计 | 1390 | 1725 |
我负责做的是代码查重的工作,从暑假有开始了解一下这些,但是时间不足,就没有开始做,只是有构想一下大概流程,以及学一下python,之前只会用C++,越用越觉得python好。。。。python
目录
0.代码查重的思想
1.预处理
2.lcs匹配
3.改进匹配算法
4.二分图匹配
5.解决批量代码的方法
6.时间复杂度
7.最终感言
0.思想
我用的是字符串匹配的想法,A文件中的一行,能和B文件匹配上的某一行匹配上后,将B文件的这一行做上标记,这样A中其他的行就不会在与这一行再匹配上,最后,算总共能匹配的行数占总行数的多少,便是代码的重复率
1.预处理
首先,所有的注释等无用的信息,我都先用正则去除掉了,代码的注释、所有的空格、中括号,因为不同人的代码习惯不一样,有些人为了看着方便会多加一些空格,还有中括号的位置也不一样,例如:
while(1){
if( x == 1 )
break;
}while(1)
{
if(x==1)
break;
}这样,代码在匹配的时候,就不容易因为这些无关的信息影响匹配的准确度
2.lcs匹配
一开始我准备直接用最长上升子序列来匹配(lcs),两行字符串,如果有超过parms的相同部分,那么就可以说这两行代码是一样的,而后实验发现,这样一部分的行只需要换一个变量名,就可以使我的匹配度急剧下降,例如:
明显,这两份代码基本是一样的,可是用lcs的方法的话,只能把头文件这些完全一样的代码查重,而之后的就发现不了,重复率只有6/12,仅为50%,这样的结果明显是不符合我们的期望的,如果随意降低parms的值,会导致匹配的准确度急剧下降,使两个不一样的句子也被认为使一样的,而且比较短的句子也依旧无法被认定为一样,显然这需要改进。
3.改进匹配算法
查阅了挺多的东西后,找到这一篇博客然后。。。艰难的去学字符串匹配的Levenshtein距离和Jaro-Winkle距离,后面应用了这两种方法去匹配,即使在parms为0.9的情况下,然后!!。。。
额,还挺不错,继续试一下其他的代码,但是发现我其中有引用部分别人的代码,发现他们中间很多参数设置的不合理,然后他们去的是,匹配行数/min(A的行数,B的行数),额这种我在实验的时候,发现许多完全不一样的代码,也会有很高的匹配度。。。例如
匹配度居然高达。。。。
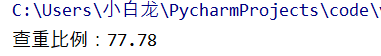
唉,真不知道他们怎么处理的,问题这么大你们没发现?,难道实验的时候没有考虑这些情况吗??手动(黑人问号.jpg)
还有一些其他不合理的参数设置就不提了,中间把代码修修改改,设置合理的parms,以及实验各种可能出现的抄袭代码,以及代码可能出现的情况,中间一一解决,现在至少出现的大部分代码都是匹配准确度都是比较高了,至少在我看来。
例如刚刚那个
4.二分图匹配
在每行匹配好了的情况下,用二分图匹配,进行A文件和B文件的行与行之间的匹配,额,C++写的话因为之前有学,所以这个不难,然后用python来写的话查了查,问题也不大(python真好用!!,真短)。
最后将匹配的行数与总行数之间的取值进行除法运算就好了。
算法篇结束
5.解决批量代码的方法(未完)
我的代码一开始是使用文件读入的方式的,但是想了想,先需要把所有文件下下来丢在一个文件夹里,命名在确定一下下。。。。真的是麻烦。
之后直接把同学门的代码直接爬取下来,只需要他们在自己的仓库里统一新建一个文件,然后把代码都丢里面就好了,例如这样的
这样我就可以直接把代码弄下来,可以直接搞定,可是和老师说了一下。。。。明哲大佬说不太行???额老师还问有没有更好的方法。。这已经是我能想到的最好的方法了,然后老师让明哲把同学的代码都下下来给我,也行吧,到时候再看看怎么弄,反正只是修改一下循环就好了。等候差遣!
6.时间复杂度分析
大概班上一百多个人,每两个人匹配一下,1E4时间,加上lcs匹配时间是Nlog(N),但是这个是一行的长度,大概每行算二十个字符左右吧,1E6,加上二分图匹配,O(VE)的时间,总行数×能匹配的行数,估计一下,一千行代码,能匹配,每行匹配100行,1E5,总时间复杂度1E11。。。跑ACM爆炸。。唉,习惯性,大概python一秒算1E7,。。。怎么要两个多小时。。。。。。。。吐血.jpg,应该没什么事吧,这个是比较差的情况,大不了就让他跑,又不是没时间。。。。(破罐子破摔,外加理直气壮)
7.最终感言
其实这次这个花的时间还是挺长的,中间个人发生挺多事情的,被搞得很烦,一度情绪很低落,加上万事开头难,一开始都不知道怎么下手,找又都没怎么找到有用的资料,有一些有用的,比如改进算法这一篇,又不提供代码。。。。难受!而且,助教群里。。。大佬们都开始了,都已经弄出了一些成果,而我什么都没有,我太菜了(眼泪流下来),一直都是花了时间,但是却没什么成效。
还好,后面一点点开始之后,然后个人的事情也解决了,心情直线上升,能专心做这个,把最垃圾的版本敲出来之后,后面的进展就顺利多了,然后也学了挺多东西的吧,比如很多python的使用规则,以及爬取网页代码,读取文档和excel文档等等,虽然可能很多别人都已经会了,可是自己通过学习,也掌握之后,其实还是挺开心的,有成就感。虽然自己还是很菜,要加油呀。