原文链接:http://xueshu.baidu.com/s?wd=paperuri%3A%286f32e0834ddb27b36d7c5cda472a768d%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fabs%2F1311.2524&ie=utf-8&sc_us=7755102487057457737
http://blog.csdn.net/wangsidadehao/article/details/54237567
题目:丰富的特征层次结构,用于精确的对象检测和语义分割(2014)
摘要
在标准的PASCAL VOC 数据集上测量的对象检测性能在过去几年已经稳定。最佳性能的方法通常是一个复杂的混合系统,它通常将多个低级图像特征与高级上下文组合起来。在本文中,我们提出了一个简单和可扩展的检测算法,相对于以前在VOC2012上的最佳结果(实现mAP 53.3%),在平均精度上(mAP)提高了30%以上。我们的方法结合了两个关键的要素:(1) 将高容量的卷积神经网络(CNN)应用到自下而上的候选区域方法中,来定位和分割对象;(2)当标记的训练数据稀缺时,对于一个辅助任务来说,使用一个有监督的预训练好的模型,加上在特定域上进行微调后,会产生一个显著的性能提高。因为我们将候选区域(region proposal)和卷积神经网络(CNN)结合在一起,我们称我们的方法叫R-CNN:带有CNN特征的区域(Region with CNN features),我们也将R-CNN与OverFeat进行了比较,OverFeat是一个最近提出的基于类似CNN架构的滑动窗口检测器。我们发现R-CNN在200类的ILSVRC2013检测数据集上的结果比OverFeat好很多。完整系统的源代码可以从下面获得:http://www.cs.berkeley.edu/˜rbg/rcnn.
1. 引言
特征很重要。在过去10年的时间里关于各种视觉识别任务的进展大量基于SIFT和HOG的使用。但是如果我们观察在经典的视觉识别任务(PASCAL VOC目标检测)上的性能表现,通常认为在2010-2012年期间进展缓慢,在这期间只是通过建造一些集成系统和在一些成功方法上做一些小改动,收效甚微。
SIFT和HOG是逐块定向直方图,它是一种表示方法,我们大致可以与V1中的复杂细胞,灵长类动物视觉途径中的第一皮质区域相关联。但我们也知道识别发生在几个阶段的下游,这表明可能有分层的,多阶段的过程用于计算特征,这些特征甚至具有更多的视觉识别信息。
Fukushima的“neocognitron”是一种生物学启发的用于模式识别分层和转移不变的模型,是早期的对于这样一个过程的尝试。然而”neocognitron“缺少一个监督训练算法。Rumelhart et al. [33], LeCun et al. [26]的研究表明通过反向传播的随机梯度下降方法对于训练CNNs是非常有效的,它也是一种”neocognitron“模型的扩展。
CNNs在20世纪90年代被大量使用,但随着SVM的兴起,CNNs又不流行了。在2012年,Krizhevsky等人通过在ILSVRC上显示出了更高的图像分类精度,使得人们重新燃起了对CNN的兴趣。他们的成功源于在120万个标记图像上训练的大的CNN,并结合了一些在LeCun的CNN中使用的一些小技巧(例如,max(x,0)修正的非线性单元和”droupout”正则化)。在ILSVRC 2012研讨会期间,ImageNet结果的意义被激烈的讨论。中心问题可以归纳如下:在ImageNet上的CNN分类结果在多大程度上可以被推广到PASCAL VOC挑战的对象检测结果上?
我们通过弥合图像分类和对象检测之间的差距来回答这个问题。本文首次表明,与基于更简单的HOG类似的特征系统相比,CNN可以在PASCAL VOC上得到更加显著的目标检测表现。
与图像分类不同,检测需要在图像中定位(可能有许多)目标。一种方法是将定位看作回归问题。然而,Szegedy等人的工作,与我们自己的工作同时表明这种策略在实践中可能不好(在VOC2007中,他们提交的mAP是30.5%,而我们的方法实现的是58.5%)。一种替代方案是构建一个滑动窗口检测器。CNN已经以这种方式使用了至少二十年,通常是在限定的对象类别上,例如人脸和行人。为了保持高的空间分辨率,这些CNN通常仅具有两个卷积和池化层。我们也考虑采用一个滑动窗口的方法。然而,在我们的网络中具有5个卷积层的单元在输入图像上具有非常大的接收域(195195像素)和步幅(3232像素)。这使得在滑动窗口范例内的精确定位成为一个公开的技术挑战。
相反,我们通过在”使用区域识别“范式中进行计算来解决CNN定位问题,其已经成功应用于目标检测和语义分割。在测试时,我们的方法为输入图像生成大约2000个类别无关的候选区域,使用CNN从每个候选区提取固定长度的特征向量,然后使用特定类别的线性SVM对每个进行区域进行分类。我们使用一种简单技术(仿射图像扭曲-affine image warping)来对每一个候选区域计算一个固定大小的CNN的输入,而不虑彪区域的形状。图1给出了我们方法的概述,并突出了我们的一些结果。由于我们的系统将候选区域和CNN结合在一起,我们将方法缩写成R-CNN:带有CNN特征的区域(Region with CNN features)。
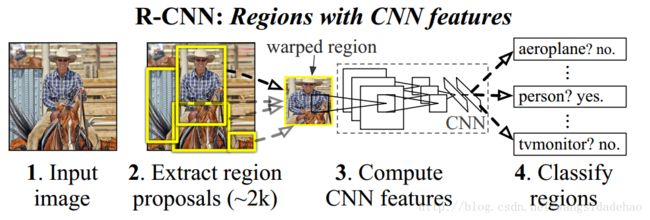
图1:目标检测系统概述我们的系统(1)接收一个输入图像,(2)抽取大约2000个从下到上的候选区域,(3)对于每一个大的候选区域使用一个大的CNN计算特征,然后(4)使用特定类的线性SVM对每一个区域进行分类。R-CNN在PASCAL VOC 2010 上实现了一个平均精度(mAP)53.7%。为了比较,[39]使用相同的候选区域方法实现了35.1%的mAP,但是使用了空间金字塔和视觉词袋方法。
在本文的这个更新版本中,我们通过在200类的ILSVRC2013检测数据集上运行R-CNN,提供了一种对R-CNN和最近提出的OverFeat检测系统的一种直接比较。OverFeat使用滑动窗口CNN进行检测,直到现在也是ILSVRC2013检测中性能最佳的方法。我们显示R-CNN显著优于OverFeat,R-CNN的mAP为31.4%,而OverFeat的mAP是24.3%。
检测中面临的第二个挑战是标记的数据很少,并且当前可用的量不足以训练大的CNN。该问题的常规解决方案是使用无监督进行预训练,随后是进行有监督的微调。本文的第二个主要贡献是显示在大型辅助数据集(ILSVRC)上进行有监督的预训练,然后是在小数据集(PASCAL)上进行特定领域的微调,这种方法在当数据不足时是学习大容量CNN的有效范例。在我们的实验中,用于检测任务的微调将mAP性能提高了8个百分点。微调之后,我们的系统在VOC2010上实现了mAP到54%,而高度调整后的,基于HOG的DPM的mAP为33%。我们也给读者指出了由 Donahue等人做的同时期的工作,他表明Krizhevsky的CNN可以当成一个黑盒使用(不用微调)来进行特征提取,在几个识别任务中产生优秀的表现,包括场景分类,细粒度子分类,和域适配(参考)。
我们的系统也很高效。唯一的特定类的计算也是合理的小的矩阵向量积和贪婪的非极大值抑制。该计算性质来自于所有类别中共享的性质,并且比先前使用的区域特征低两个数量集(参见[39])。
理解我们方法的失败模式也是改善它的关键,所以我们报告了从Hoiem等人[23]的检测分析工具得到的结果。作为这种分析的直接结果,我们证明一个简单的边界框回归方法显著地减少了误定位,这是主要的错误模式。
在讲述技术细节之前,我们注意到,因为R-CNN在区域上操作,所以很自然地将其扩展到了语义分割任务上。通过微小的修改,我们还在PASCAL VOC分割任务上实现了竞争性的结果,在VOC2011测试集上的平均分割精度47.9%。
2. 目标检测
我们的目标检测系统包括三个模块。第一个生成类无关的候选区域。这些候选区域定义了可用于我们的检测器的候选检测地集合。第二个模块是一个大的卷积神经网络,它从每个区域中抽取固定长度的特征向量。第三个模块是一些特定类别的线性SVM。在本节中,我们介绍每个模块的设计决策,描述其测试时间使用情况,详细了解其参数的学习方法,并在PASCAL VOC 2010-12和ILSVRC-2013上显示了检测结果。
2.1. 模块设计
候选区域。各种最近的论文提供了用于生成类无关候选区域的方法。例子包括:objectness[1],选择性搜索[39],类独立的候选对象[14],CPMC,多尺度组合分组,和Ciresan等人通过将CNN应用于规则间隔的方形剪裁来检测有丝分裂细胞,这是候选区域的一个特殊情况。R-CNN对于特定的候选区域方法是不可知的,我们使用选择性搜索来实现与先前的检测工作的控制比较。
特征提取。我们使用Krizhevsky等人描述的CNN的Caffe实现从每个候选区域中提取4096维特征向量。通过将减去平均值的227227的RGB图像通过5个卷积层和两个全连接层的前身传播来计算特征。我们引导读者参考[24,25]来获得更多的网络架构的细节。
为了计算候选区域的特征,我们必须首先将该区域中的图像转换成与CNN兼容的形式(其体系结构需要固定的227227像素尺寸的输入)。在我们任意形状区域的许多可能的变换中,我们选择最简单的。忽略了候选区域的大小或宽高比,我们会将其周围的紧密边界框中的所有像素扭曲到所需要的大小。在变形之前,我们扩大紧密边界框,使得在变形大小处,在原始框周围正好有p个像素的扭曲图像上下文(我们使用p=16)。图2展示了扭曲训练区域的随机采样。扭曲的替代方法会在附录A中讨论。

2.2. 测试时间检测
在测试时,我们在测试图像上运行选择性搜索抽取大约2000个候选区域(在所有的实验中,我们都使用选择性搜索的“快速模型”)。我们扭曲每一个候选图像,并且将它前向传播通过CNN为了去计算特征。然后,对于每个类,我们使用为该类训练的SVM对每个提取的特征向量求得分。给定图像中所有得分区域,我们对每个类独立地应用贪心的非最大值抑制,如果其具有与大于学习阈值较高得分的选择区域的IoU重叠,那么它就会拒绝一个区域。
运行时间分析。两个属性使用检测有效。首先,所有类别共享所有CNN参数。第二,当与其它常见方法(例如具有视觉词袋编码的空间金字塔)相比时,由CNN计算的特征向量是低维的。例如,在UVA检测系统中使用的特征比我们的特征大两个数量级(360K对4K维)。
这种共享的结果就是计算候选区域和特征所花费的时间(在一个GPU上是13s/图像,在CPU上是53s/图像)在所有类上平摊。唯一的特定类的计算是特征和SVM权重和非最大值抑制之间的点积。在实际中,图像的所有点积被分批成单个矩阵-矩阵的乘积。特征矩阵通常为20004096,SVM权重矩阵为4096N,其中N是类的数量。这个分析表明,R-CNN可以扩展到数千个对象类,而不用诉诸于近似技术,如哈希。即使有100K个类,在现代的多核CPU上产生的矩阵乘法也只需要10s。这种效率不仅仅是使用候选区域和共享特征的结果。由于其高维特征,UVA系统将减慢两个数量级,需要134GB的存储器仅仅存储100k的线性预测器,相比之下,我们的低维特征只有1.5GB。
将R-CNN与Dean等人近来使用的DPM和哈希的可扩展的检测方法的工作进行对比也是非常有趣的。他们在VOC 2007上报告了大约16%的mAP,当引入了10k个牵引类时, 每个图像的运行时间为5分钟。用我们的方法,10k个牵引类在一个CPU上大约运行1分钟,因为没有进行近似,mAP将保持在59%(第3.2节)。
2.3. 训练
监督预训练。我们有区别的在仅使用图像级注释的大型辅助数据集(ILSVRC212分类)上预训练CNN(边界框标签不可用于该数据)。预训练是用开源的Caffe CNN库来执行的。简而言之,我们的CNN几乎匹配了Krizhevsky等人的性能,获得了top-1错误率在ILSVRC2012分类验证集上2.2个百分点的增加。这种差异是由于训练过程的简化。
特征领域的微调。为了使我们的CNN适应新任务(检测)和新领域(扭曲的候选窗口),我们仅使用扭曲的候选区域继续CNN参数的SGD的训练。除了用随机初始化的(N+1)类分类层(其中N是对象类的数目,加上背景的1)来替换CNN的ImageNet特定的1000类分类层之外,CNN架构没有改变。对于VOC来说,N = 20,并且对于ILSVRC2013来说,N = 200。我们将所有候选区域与真实框重叠大于等于0.5的作为该框类的正例,其余的作为负例。我们以0.01的学习率(初始预训练率的1/10)开始SGD,这允许微调进行而不破坏初始化。在每一次的SGD迭代中,我们均匀地采样32个正窗口(在所有类上),和96个背景窗口以构造大小为128的小批量。我们将采样偏向正窗口,因为它们与背景相比非常少。
对象类别分类器。考虑训练一个二分类器去检测小汽车。很清楚,紧紧包围一个汽车的图像应该是一个正例。同样,明显的,与汽车无关的背景区域应该是一个负例。不清楚的是,怎样标注一个部分覆盖一辆汽车的区域。我们使用IoU重叠阈来重新解决这个问题,在这之下的区域就定义为负例。通过在验证集上的{0,0.1,…,0.5}的网络搜索来选择一个重叠阈0.3。我们发现小心地选择这个阈值是非常重要的。将它设置为0.5,正如[39]中一样,能够将mAP减少5个百分点。相似地,将它设置成0的话,能够将mAP减少4个百分点。正例仅仅被定义为每个类的真实边界框。一旦特征被提取出来,训练标签被应用上,我们就对每一个类优化一个线性SVM。由于训练数据太大,不适合内存,我们采用标准的hard negative mining方法。Hard negative mining快速收敛,并且在实际中,所有的图像仅通过一次,mAP就停止增加了。
在附录B中,我们讨论了为什么在微调和SVM训练中正例和负例的定义不同了。我们还讨论了训练检测SVM的权衡,而不是简单地使用来自微调CNN的最终SoftMax层的输出。
2.4. 在PASCAL VOC 2010-12上的结果
遵循PASCAL VOC 最佳实践[15],我们验证了VOC 2007数据集(第3.2节)中所有的设计决策和超参数。对于在VOC 2010-12数据集上的最后的结果,我们微调了VOC 2012训练上的CNN并且在VOC 2012 训练验证集上优化了我们的检测SVM。我们对于两个主要算法变量(有和没有边界回归)中的每一个都只向评估服务器提交测试结果一次。
表1展示了在VOC 2010上的完整结果。我们将我们的方法与4个强基线进行了对比,包括SegDPM,其将DPM检测器与语义分割系统的输出结合在一起,并且使用了额外的检测器上下文和图像分类器重新评分。最杰出的比较是来自Uijlings等人的UVA系统,因为我们的系统也使用了相同的候选区域算法。为了对区域进行分类,他们的方法构建了一个4个级别的空间金字塔,并且用密集采样的SIFT,扩展OpponentSIFT,和RGBSIFT描述符来填充他们,每个矢量都用4000个字的编码本来进行量化。使用一个直方图相交核的SVM进行分类。与它们的多特征,非线性核SVM方法相比,我们在mAP上实现了一个大的改进,从35.1%到 53.7% mAP,同时也快得多(第2.2节)。我们的方法在VOC 2011/12测试中达到了相似的性能(53.3%的mAP)。

表1:在2010测试集上检测平均精度(%),R-CNN与UVA和Regionlet最直接对比,因为所有的方法都使用选择性搜索候选区域。边界框回归会在C节描述。在提交的时候,SegDPM是在PASCAL VOC排行榜上表现最出色的。DPM和SegDPM使用了一种其它方法没有使用的上下文重新评估的方法。
2.5. 在ILSVRC2013检测上的结果
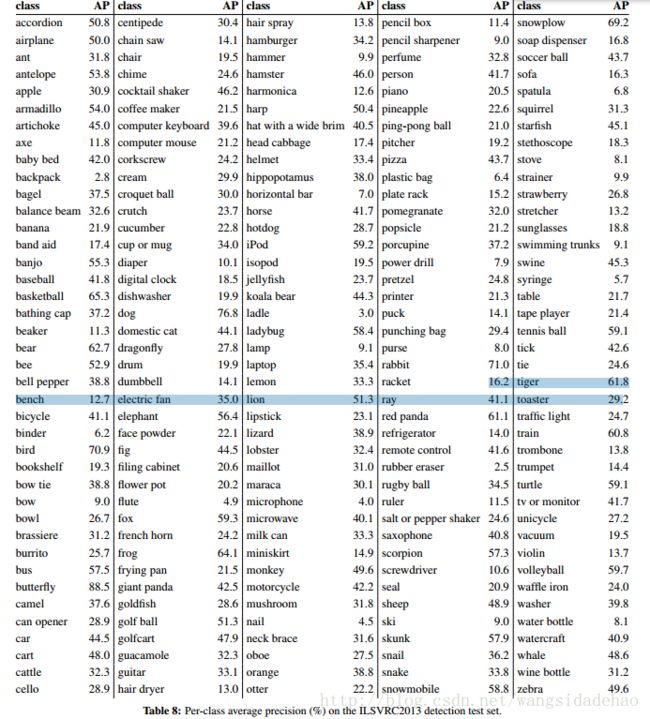
我们在200类ILSVRC2013检测数据集上运行R-CNN,使用于PASCAL VOC 上相同的系统超参数。我们遵循相同的规则,就是将测试结果提交给ILSVRC2013评估服务器仅仅俩次,一次带有边界框回归,另一次不带。图3比较了R-CNN与ILSVRC2013竞赛中的条目以及竞赛后的OverFeat结果。R-CNN实现了31.4%的mAP,显著超过了OverFeat的24.3%的次优结果。为了给出对类别分布的一个感觉,呈现了一个盒图,并且在论文的结尾处的表8里出现了类别AP的表格。大多数的竞赛提交(OverFeat, NEC-MU, UvAEuvision, Toronto A, and UIUC- IFP)都使用了卷积神经网络,指示在CNN如何应用于对象检测方面存在显著差异,导致了极大变化的结果。在第4节,我们概述了ILSVRC2013检测数据集,并提供了在运行R-CNN时我们做出的选择的详细信息。
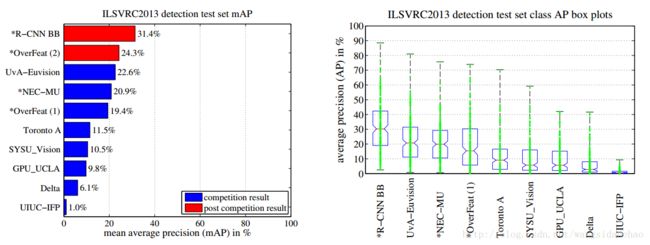
图3:(左)在ILSVRC2013检测测试数据集上的mAP。带的方法都是使用了外部训练数据(所有情况下都是从ILSVRC分类数据集中的图像和标签)。(右)每种方法的200个平均精度值的箱线图。*未显示竞争后的OverFeat结果的框图,因为每类的APs尚不可用(R-CNN的每类AP在表8中,也包含在上传到arXiv.org的技术报告源中;见R-CNN- ILSVRC2013-APs.txt)。红线标示中值AP,箱底和箱顶是25和75百分位数。虚线延伸到每种方法的最小和最大的AP值。每个AP被绘制成虚线上的一个绿点(最好用数字缩放)。
3. 可视化,消融,和误差模式
3.1. 可视化学习的特征
第一层的过滤器可以直接被可视化并且很容易理解。它们捕获有方向的边和相对的颜色。理解下面的层次是更具有挑战性的。Zeiler and Fergus在[42]中提出了一种视觉上有吸引力的反卷积方法。我们提出了一个简单(和互补的)非参数的方法,直接显示网络学习的内容。
这个想法就是在网络中单独出一个特定的单元(特征),并且使用它就好像它本身就是一个对象检测器。也就是说,我们在大量提出的候选区域(大约1千万)计算单元的activations,将候选区域从高的activation到低的activation进行排序,执行非最大值抑制,然后显示最高评分区域。我们的方法让选择的单元“说出自己”通过精确显示它所触发的输入。我们避免平均,以便看到不同的视觉模式,并且可以获得由单元计算的不变性的洞察。
我们从第5个池化层观察单元,其是网络第5和最后卷积层的最大池化的输出。第5个池化层的特征映射是
图4中的每一行显示了我们在VOC 2007 trainval上微调的CNN的一个

图4:6个
3.2. 消融研究
性能逐层,无需微调。为了理解哪一层对于检的测性能是重要的,我们对CNN的最后三层的每一个都在VOC 2007数据集上分析了结果。
我们首先从不在PASCAL上进行微调的CNN上查看结果,即所有的CNN的参数仅在ILSVRC2012上进行预训练。逐层分析性能(表2第1-3行)提示了
带有微调的逐层的性能。在VOC2007 trainval上调整了我们的CNN的参数之后,我们现在再来看一下结果。改善是显著的(表2中的4-6行):微调将mAP提高了8.0个百分点至54.2%。对于
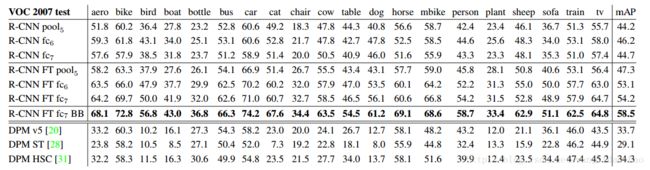
表2:在VOC 2007测试集上的检测的平均精度(%)。1-3行展示的是没有经过微调的R-CNN的性能。4-6行展示了在ILSVRC2012上预训练过,并且在VOC2007trainval上微调过的CNN的结果。7行包括一个简单的边界框回归(BB)阶段,其减少了定位错误(C节)。8-10行展示了DPM方法作为一个强基准线。第一个仅使用了HOG,然而接下来的2个使用了不同的特征学习方法来增强或替换HOG。
对比于最近的特征学习方法。最近有相对较少的特征学习方法在PASCAL VOC检测上进行尝试。我们看看基于可变形部件模型的两个最近的方法。作为参考,我们也包括了标准的基于HOG的DPM的结果。
第一种DPM特征学习方法DPM ST[28]用“草图标记”概率的直方图来增强HOG特征。直观来说,一个草图标记就是穿过图像块中心的轮廓的紧密分布。草图标记概率在每个像素处由随机森林计算,该森林被训练成将3535像素块分类成150个草图标志或背景中的一个。第二种方法,DPM HSC[31],用稀疏编码(HSC)的直方图代替HOG。为了计算HSC,使用100个77像素(灰度)原子的学习字典来解决每个像素处的稀疏码激活。所得激活以三种方式(全半波和两半波)来进行修正,空间池化,单元
所有的R-CNN变体都大大超过三个DPM基线(表2中的8-10行),包括使用特征学习的两个。与仅使用HOG特征的最新版的DPM相比,我们的mAP高出了20个百分点:54.2% 对 33.7%-相对改善了61%。HOG草图标记的结合超过了HOG自己2.5个mAP,而HSC改进超过HOG4个mAP(当内部与其私有DPM基线相比时-都使用非公开的实现的DPM,其比开源版本的性能要差一点)。这些方法各自实现mAP为29.1%和34.3%。
3.3. 网络结构
这篇文章的大部分结果都使用Krizhevsky等人的网络结构。然而,我们发现,结构的选择对于R-CNN检测性能有一个很大的影响。在表3中我们展示了使用Simonyan and Zisserman最近提出的16层深度网络的VOC 2007测试的结果。这个网络是近期ILSVRC 2014分类挑战中表现最佳的网络之一。网络具有由13个3*3卷积核组成的均匀结构,中间分散了5个最大池化层,最后跟着3个全连接层。对于OxfordNet,我们将此网络称为“O-Net”,对于TorontoNet的基线称为“T-Net”。为了在R-CNN中使用O-Net,为了在R-CNN中使用O-Net,我们从Caffe Model Zoo上下载了VGG_ILSVRC_16_layers模型的公开可用的预训练网络权重。然后,我们使用与T-Net相同的协议对网络进行了微调。唯一的不同就是根据需要使用较小的minibatches(24个示例)以适应GPU的内存。表3中的结果显示具有O-Net的R-CNN基本上优于具有T-Net的R-CNN,将mAP从58.5%增加到66.0%。然而,在计算时间方面存在相当大的缺点,其中O-Net的正向传播比T-Net长大约7倍。

表3:两个不同的CNN结构在VOC2007上测试集上目标检测的平均精度(%)。前两行是来自于表2,使用了Krizhevsky等人的结构(T-Net)。3,4行使用了最近由Simonyan
and Zisserman(O-Net)提出的16层的结构。
3.4. 检测错误分析
我们应用了Hoiem等人的优秀的检测分析工具,为了揭示我们方法的错误模式,了解微调如何改变他们,以及看看我们的错误模式与DPM的比较。分析工具的完整总结超出了本文的范围,我们鼓励读者咨询[23]了解一些更精细的细节(例如“归一化AP”)。由于分析最好在相关图的上下文中才会更受吸引,所以我们在图5和图6的标题内给出了讨论。
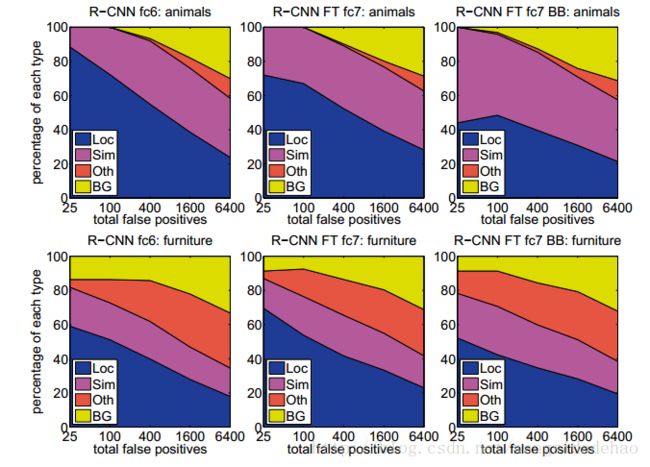
图5:排名最高的FP类型的分布。每幅图展示了FP类型的演变分布,因为更多的FP按照分数递减的顺序被考虑。每个FP分类成4种类型中的1种:Loc-poor定位(和正确类别的IoU重叠在0.1和0.5,或重复);Sim-与相似的类别混淆;Oth-与不同对象类别的混淆;BG-在背景上触发的FP。与DPM相比(参见[23]),我们的错误更多的是来自于差的定位,而不是与背景或其他对象类的混淆,表明CNN特征比HOG更有区别性。差的定位可能是由于我们使用自下而上的候选区域和从预训练CNN进行整体图像分类学习的位置不变性。第三列显示了我们的简单的边界框回归方法如何修复很多定位错误。
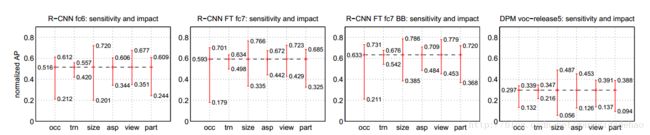
图6:对对象特征的敏感性。每个图展示出了六个不同对象特征(遮挡,截断,边界框区域,宽高比,视角,部分可见性)内的最高和最低的表现子集的平均(所有类)归一化AP。我们在图上展示了我们的方法(R-CNN),带有和不带有fine-tuning(FT)和边界框回归(BB),以及DPM 的voc-release5。总的来说,微调并不会降低敏感性(最大值和最小值之间的差值),但是对于几乎所有的特性,基本上改善了最高和最低性能子集。这表明微调不仅仅改善了长宽比和边界框区域的最代性能子集,因为人们可能基于我们如何扭曲网络输入来进行推测。相反,微调改变了所有类别的鲁棒性,包括遮挡,截断,视角,部分可见。
3.5. 边界框回归
基于错误分析,我们实现了一个简单的用于减少定位错误的方法。受在DPM中使用的边界框回归的启发,在给定了一个选择性搜索候选区域的
3.6. 定性结果
在文章最后的图8和图9上展示了ILSVRC2013上的定性的检测结果。每一个图像都是从

图8:对

图9:更加随机的选择的样本。看图8的标题以获得更详细的描述。建议放大来看。

图10:策划过的样例。每一张选择的图片,都是因为我们发现他们印象深刻,令人惊叹,非常有趣,或者使人开心。建议放大来看。

图11:更多策划过的样例。详情请看图10的标题。建议放大来看。
4. ILSVRC2013检测数据集
在第2节中,我们展示了在ILSVRC2013检测数据集上的结果。这个数据集和PASCAL VOC数据集有很少是一样的,需要选择怎样去用它。因为这些决定是不容易的,我们在本节中讨论。
4.1. 数据集综述
ILSVRC2013数据集被划分成3个集合:训练集(395,918),验证集(20,121),和测试集(40,152),每一个集合的图像的数量都在括号中。val和test的拆分是从相同的图像分布中绘制的。这些图像是类似于场景的,并且在复杂度上与PASCAL VOC的图像相似(物体的数量,混乱的数量,姿势的变化等等)。val和test拆分具有详细的注解,意味着在每个图像中,所有200类的所有实例都用边界框标记。相反,训练集是从ILSVRC2013分类图像分布中提取到的。这些图像具有更多变化的复杂性,单个居中物体的图像较多。不像val和test,训练图像没有完全标注(由于它们的数量较多)。在任意给定的图像中,这200类的实例有可能标注了也有可能没有标注。除了这些图像集合,每一个类都有一个额外的负例图像的集合。手动检查这些负例图像,以验证它们不包含他们关联类的任何实例。负例图像集合在本工作中没有被用到。关于ILSVRC是怎么收集和标注的更多的信息可以在[11,36]中查看到。
这些拆分的本质为训练R-CNN提供了大量的选择。训练图像不能用于hard negative mining,因为标注是不充分的。负例应该来自于哪里呢?训练图像具有与val和test不同的统计量。训练图像应该被使用吗?如果是,以什么程度呢?虽然我们没有完全评估大量的选择,基于以前的经验,我们提出了似乎是最明显的路径。
我们的一般策略就是大量依赖于val集,并且使用训练图像中的一些作为一个正例的辅助源。为了将val用于训练和验证,我们将它大致分成相等的大小“
4.2. 候选区域
我们遵循用于在PASCAL上检测的相同的候选区域的方法。对
4.3. 训练数据
对于训练数据,我们形成了一组图像和框,其包括来自
在R-CNN中在三个过程中需要训练数据:(1)CNN微调,(2)检测器SVM的训练,和(3)边界框回归训练。CNN微调使用与用于PASCAL VOC上的完全相同的配置,在
4.4. 验证和评估
在提交结果到评估服务器之前,我们使用上述训练数据验证了数据使用选择以及在
4.5. 消融研究
表4显示了不同数量的训练数据,微调和边界框回归的效果的消融研究。第一个观察到的是,在
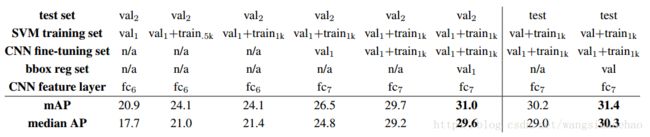
表4:ILSVRC2013消融研究,不同的数据使用选择,微调,和边界回归
4.6. 与OverFeat的关系
在R-CNN和OverFeat之间有一个有趣的关系:OverFeat可以看成是R-CNN的一个特殊的例子。如果要用正规的正方形区域的多尺度金字塔替换选择搜索候选区域,并且将每类的边界框回归改成单一的边界框回归,则系统则会非常类似(以某些潜在的重要的不同为模,如他们是怎么训练的:CNN检测微调,使用SVM等)。值得注意的是OverFeat比R-CNN具有显著的速度优势:基于[34]引用的每个图像2秒的数字,它快了大约9倍。该速度来自于OverFeat的滑动窗口(即候选区域)在图像不级别不扭曲的事实,因此在重叠窗口之间可以容易的共享计算。通过在任意大小的输入上以卷积的方式运行整个网络来实现共享。加快R-CNN应该可以以各种方法,并且作为未来的工作。
5. 语义分割
区域分类是用于语义分割的标准技术,允许我们容易地将R-CNN应用于PASCAL VOC 分割挑战中。为了促进与当前领先的语义分割系统(称为
用于分割的CNN特征。我们评估了三种计算CPMC区域特征的策略,所有的这些策略都是通过将该区域周围的矩形窗口扭曲成227227来开始的。第一个策略(full)忽略了区域的形状,并且直接在扭曲的窗口上计算CNN特征,正如我们为检测做的一样。然而,这些特征忽略了区域的非矩形形状。两个区域可能有非常相似的边界框,然而几乎没有重叠。因此,第二种策略(fg)仅仅在区域的前景掩码上计算CNN特征。我们用平均输入替换背景,使得背景区域在减去平均值后为零。第三种策略(
在VOC 2011上的结果。*表5显示了我们对VOC 2011验证集与

表5:在VOC 2011验证集上的分割平均准确性(%)。第一列展示了
在表6中,我们展示了在VOC 2011测试集上的结果,将我们的表现最好的方法,

表6:在VOC2011测试集上的分割准确性(%)。我们对比了两个强大的基线:[2]中的“Region and Parts”(R&P)方法,和[4]中的second-order pooling(
6. 结论
在最近几年,目标检测性能停滞不前。最好的系统是将多个低级图像特征与来自于目标检测器和场景分类器的高级上下文组合在一起的复杂集合。本文提出了一种简单的和可扩展的对象检测算法,与PASCAL VOC2012上的最佳以前的结果相比提供了30%的相对改进。
我们通过两个见解实现了这一表现。第一个是将高容量的卷积神经网络应用于自下而上的候选区域以便定位和分割对象。第二个就是当标记的训练数据不足时训练大的CNN的范例。我们表明,对于一个具有丰富数据集(图像分类)的辅助任务,带监督的预训练网络,并且为数据稀缺的(检测)的目标任务微调网络是非常有效的。我们推测,“监督的预训练/特定领域的微调”范例将对于各种数据稀缺的视觉问题都非常有效。
我们最后指出,我们通过使用计算机视觉和深度学习的经典工具(从底向上的候选区域和卷积神经网络)的组合实现了这些结果是非常重要的。这两者不是反对科学家探究的线,而是自然的和不可避免的伙伴。
附录
A. 目标建议转换
这项工作中用到的卷积神经网络需要一个固定的
第一个方法(“具有上下文的最紧密方框”)将每个候选对象包围在最紧凑的正方形内,然后将包含在该正方形中的图像(各向同性)绽放为CNN的输入大小。 图7的B列展示了这种改变。此方法的一个变种(“没有上下文的最紧凑的方形”)排除了原始候选对象周围的图像内容。图7的(C)列展示了这种改变。第二种方法(“warp”)将每个候选对象各向异性地缩放为CNN输入大小。图7的(D)列展示了这种扭曲转换。

图7:不同的候选对象转换。(A)相对于经变换的CNN的输入的具有实际大小的原始候选对象;(B)最紧密的带有上下文的方格;(C)不带有上下文的最紧密的方框;(D)扭曲;在每一列和候选示例中,顶行对应于上下文填充的
对于这些变换中的每一个,我们还考虑在原始的候选对象周围包括上额外的图像上下文。上下文填充量(
B. 正例对负例和softmax
两种设计选择值得进一步的讨论。为什么为微调CNN和训练对象检测SVM时定义的正例和负例是不同的?简单回顾一下定义,对于微调,我们将每一个候选对象映射到它具有最大的IoU重叠(如果有)真实实例上,并且如果IoU至少为0.5,就将它标记为匹配的真实类的正例。所有其它的候选区域都被标记为“背景”(即所有类别的负例)。相反的,对于训练SVMs,我们只把真实框作为它们各自类别和候选标签的正例,与一个类的所有实例的IoU少于0.3的作为该类的负例。落入灰色区域(超过0.3IoU重叠,但不是真实值)的候选区域被忽略。
从历史上来说,我们得出这些定义,因为我们开始通过由ImageNet预训练的CNN计算的特征训练SVM,因此在当时没有考虑微调。在该设置中,我们发现我们的用于训练SVM的特定的标签定义在我们评估的选项集(其中包括我们现在用于微调的配置)中是最佳的。当我们开始使用微调时,我们使用与SVM训练时使用的相同的正例和负例。然而,我们发现结果比使用我们现在的正例和负例的定义要差的多。
我们的假设是在正例和负例如何定义上面的不同并不是根本重要的,而是来自于微调数据有限这个事实。我们目前的方案引入了许多“抖动”方案(这些候选值具有0.5到1之间的重叠,但不是真实值),这将正例的数量扩展了大约30倍。我们推测当微调整个网络而避免过拟合的话,是需要这个大的集合的。然而,我们也注意到使用这些抖动样例也可能是次优的,因为这些网络没有微调以精确定位。
这也导致了第二个问题,为什么微调后训练SVM?简单地应用微调网络的最后一层(这是一种21路的softmax回归分类器)作为对象检测器是非常清晰的。我们尝试这么做了,发现在VOC 2007上的性能从54.2%mAP降到50.9%mAP。这种性能的下降可能是由于几种因素的结合,包括在微调中使用的微调的定义不强调精确定位,并且训练softmax分类器是在随机采样的负例上进行的,而不是在用于SVM训练使用的“hard negative”的子集中进行的。
该结果表明,在微调之后不训练SVM可能会获得接近相同水平的性能。我们推测通过一些额外的对微调的调整,剩余的表现差距可能会被关闭。如果是真的话,这将简化和加速R-CNN训练,而在检测性能上不会有损失。
C. 边界框回归
我们用一个简单的边界框回归阶段来提高定位性能。在使用一个特定类检测的SVM对每个选择性搜索候选值进行评分之后,我们使用特定类的边界框回归来预测用于检测的新边界框。这类似于在可变形部分模型[17]中使用的边界框回归。这两种方法主要的不同是,这里我们从CNN计算的特征,而不是从推断的DPM部分位置计算的几何特征回归。
我们训练算法的输入是一个N个训练对的集合
我们根据四个函数(
每一个函数
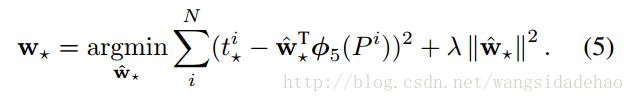
对于训练对(P,G)的回归目标
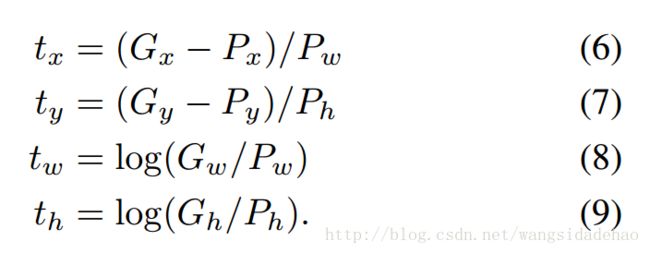
作为一种标准的正则化最小二乘问题,这可以以封闭形式有效地解决。
我们在实现边界框回归的时候发现了两个微妙的问题。第一个就是正则化是非常重要的:基于验证集,我们设置
在测试的时候,我们为每一个候选框打分,并且预测一次它的新检测窗口。原则上来说,我们可以迭代这个过程(即,为新得到的预测框重新打分,然后从它再预测一个新的边界框,以此类推)。然而,我们发现迭代没有改善结果。
D. 附加的功能可视化
图12为20个

图12:我们展示了在VOC2007测试中大约1000万个候选区域中的24个候选区域,其最强烈地激活20个单元中的每一个。每个剪辑都用
E. 每个类的分割结果
在表7中,我们展示了我们6个分割方法中的每一个(除了
F. 交叉数据集冗余分析
当在辅助数据集上进行训练时,一个问题是它与测试集之间可能存在冗余。即使对象检测和整个图像分类的任务有很大的不同,为了使这种交叉冗余不那么令人担忧,我们仍然进行了彻底的调查,量化了PASCAL测试图像包含在ILSVRC2012训练和验证集的程度。我们发现可能对那些有兴趣使用ILSVRC2012作为PASCAL图像分类任务的训练数据的研究人员有用。我们对重复(和近重复)图像执行了再次检查。第一个测试是基于flicker图像ID的精确匹配,这些ID包括在VOC 2007测试注释中(这些ID有意的为后续的PASCAL测试集保密)。所有的PASCAL图像,和约一半的ILSVRC图像,从flickr.com收集。这个检查证明了在4952有31个匹配(0.63%)。
第二个检测使用了GIST描述符匹配,在[13]中显示在大(>100万)图像集合中的近似图像检测中具有优异的性能。在[13]之后,我们计算了所有的ILSVRC2012trainval和PASCAL 2007测试图像的扭曲32*32像素版本上的GIST描述符。GIST描述符的欧氏距离最近邻匹配揭示了38个近似重复图像(包括通过flickrID匹配找到的31个)。匹配在JPEG压缩级别和分辨率略有变化,并且趋向较小程度的裁剪。这些发现表明重叠是小的,小于1%。对于VOC 2012来说,因为flickrID是不可用的,我们只使用了GIST匹配方法。基于GIST匹配,VOC 2012测试图像的1.5%是在ILSVRC 2012trainval中的。对于VOC 2012略高的比率可能是由于这两个数据集在时间上收集的比VOC 2007和ILSVRC 2012更接近。