先扯一会男人胯下那两个东西
今天,朋友找我问一个在 WebBrowser 里加载 HTML 页面乱码的问题,帮她处理过以后,她嘟囔了一句 “编码什么的我完全不懂啊”……
这里的她,已经有三年的工作经验,大大小小的项目也参与过几个,可是对于这个问题,还是似懂非懂。
不只是她,其实还有好多工作多年的朋友对这个问题还不甚理解,因为工作原因,只知道出现乱码以后改改配置文件,开发工具里设置一下就能解决,深层次的原因,还是不很理解,或者是没必要理解,也不想去理解。
前段时间就有一个朋友,有点装逼的朋友,接触编程十来年了,工作也有七八年了,现在在一个在当地小有一些名气的软件公司任技术经理。我们合作了一个小项目,他用 Java 负责云端,我用 C# 做客户端。我设计了一个 Lincenses 生成、校验的算法,主要是拿硬件ID、设备编号、授权日期这些参数生成一个16位的注册码,使离线版的客户端能够被系统管控。为了避免轻易被猜解,我加了随机混淆的机制。当我把这个 Licenses 算法的 Java 版代码给他的时候,他死活不相信是我写的,甚至至今,提起那个项目,他还说我“网上找的算法”……~~~无语~~~多大个事儿啊,也就把源数据的编码转来转去拼拼凑凑处理一下而已,但是,他不会~~~
也确实,大多数编码的问题开发环境都替我们解决了,只在项目布署的时候,或者多方通信的时候,才会考虑编码问题。所以,很多人对“编码”这个东西并没有多深刻的理解。
啥是编码?
要说起“编码”这玩意儿,事实上一直伴随我们左右,甚至可以说是一个“最熟悉的陌生人”,比如:“邮政编码”。
“编码”的概念,在百科上是这样解释的:“编码是信息从一种形式或格式转换为另一种形式的过程也称为计算机编程语言的代码简称编码。用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。编码在电子计算机、电视、遥控和通讯等方面广泛使用。编码是信息从一种形式或格式转换为另一种形式的过程。解码,是编码的逆过程。”
简单来讲,编码是信息从一种形式或格式转换为另一种形式的过程。
概念比较抽象,我们还拿邮政编码来举例。
邮局,那个神奇的、无孔不入、无所不达又无比大爷的神奇机构,他们为了提高邮件的投递效率,为了快速的区分像 “中华人民共和国新疆维吾尔自治区 伊犁哈萨克自治州 察布查尔锡伯族自治县 奥依亚依拉克乡 奥依亚依拉克村村民委员会 古且末国历史文化遗址 申报联合国教育科学文化组织 世界非物质文化遗产工作领导小组办公室” 这种奇葩的地址,他们把全中国每一个区域都编一个6位数字的编码。无论你地址再长,那怕长的能写一篇论文,也只用6位数字代替,这样经验丰富的分捡人员瞄一眼就能知道这个邮件是寄往哪里的。这个6位数字编码,就是邮政编码。也就是说,全国的每一个地区,都可以用一个6位数字的编码代替,这个6位数字,就是这个地区的“编码”。
编码,做为名词时,可以理解为一一对应的一种信息转换规则;做为动词时,可以理解为信息转换的过程。
除了邮政编码,我们身边还有很多各种各样的编码,比如:“身份证编码”,“毕业证编码”等等。
实际上,上面扯的那么多,都是蛋。扯出去了,再扯回来。
码农眼中的编码
在计算机世界里,所有数据最原子的单位是位,英文叫 bit。每一个 bit 可选值有 1 或 0 两个,可以理解成 True 或 False、有或无。这是二进制计算机系统的根本。计算机无论通信,还是存储,都是以二进制的方式表达信息。
老子说:太极生两仪,两仪生四象,四象生八卦,再生六十四卦,再生生万物,一直生,这个世界就出来了。。。
在计算机世界里,bit 生两仪,两仪生 256 卦,再生生万物,一直生,就有了今天这么丰富多彩的计算机世界。
bit 如果只有一个,屁用都木有。幸运的是,bit 可以有很多很多很多很多个,多的你数不过来。
1 个 bit,只能表示0 1、True False、有 无,可以表示一下下班了没?饿了没?困了没?死了没?没啥大用。
2 个 bit 合在一起,就可以有4个组合:00、01、10、11。多少有点用处了:假设一个小组有4个人,00表示张三,01表示李四,10表示王五,11表示赵六。这样两个bit的空间就可以表达一个人了。
3 个 bit 合在一起,就可以有 8 种组合。当然表示的可能性更大。
4 个 bit,就可以有16种组合。
。。。。。
8 个 bit 就可以有 256 种组合。可以表示 128 对情侣(256个),当然也可以表示 256 条单身狗。当然也可以表示100对情侣外加56个单身狗。
反正是随着 bit 的数量累加,计算机可以表示的信息越多,越丰富。
不过,纯粹的 bit 堆叠确实能表示很多种信息,但是,这些信息使用起来不方便。抽象的一堆编号,很难理解其中的意义。
于是,许多年前,美国那堆砖家立志要解决这个问题。他们抠着脚指头算了算,英文字母大小写区分后有 52 个,再加 10 个数字还有标点符号,再加一些数学运算符,再扒开脑洞,使劲的造,拼凑够了128个符号。128个符号才占7位啊,7位没8位好听,就再补一位吧。这样 8 个 bit 的值就能表示美国人使用的一个符号或字母,或者统称为字(字节 byte)。这样如果有16个bit的话,就可以表示两个字,几百个 bit 就能表示人能理解的一句话。(这一段是扯蛋话,不是正史)
这真是个好主意!
于是,一帮砖家开了个会,确定了这种分组方式。然后对这些字母和符号按他们自己的喜好排排序,确定了下来,就行成了今天我们看到的 ASCII 编码表。如下图:
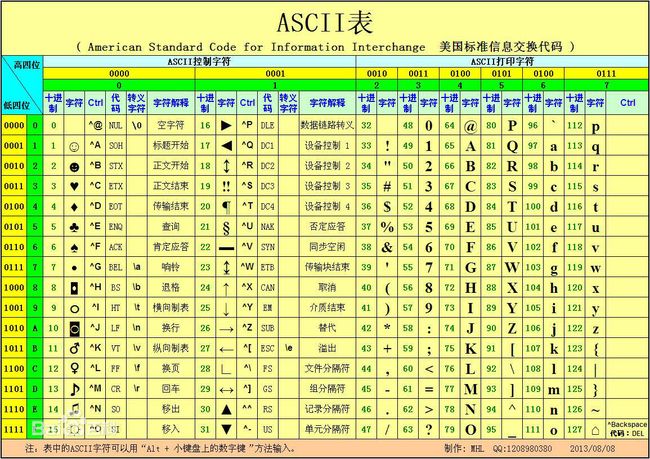
于是乎,无论是什么形式的一堆二进制数据,统统按照 8 个一组的方式进行截取,然后分别到 ASCII 表中找出对应的字符,就可以拼成一句美国人能理解的话。
说实话,这确实是一个很屌的发明。
再扯蛋一会儿
今天看了一个码农发春的段子,与今天的主题相关,大概内容如下:


做为曾经的单身狗,看到最后美好的结局本来挺欣慰的。但是当发现这条狗给一个艺术系的妹子发 ASCII 码的时候,不禁为妹子深(sao)沉(qing)的爱感到遗憾。这种作死狗就应该一辈子保持纯洁的童子身。
不过,扯回今天的话题:这个妹子熬了半夜,做的工作就是编码——将一组数据,编码成目标信息。
不过再说一句:这故事也太扯蛋了。
强行扯回主题
ASCII 码是美国标准信息交换码,只是一些拉丁字符及符号。它有一个非常缺心眼的地方:它只能表示256个符号。而人世间,符号何止几百个。
拿中文来说,有简体繁体之分,甚至一个字多种写法,加上各种生僻字,仅仅一个汉字就得好几万字符。ASCII 码远远不够用。
为了解决这个问题,有志之士们想了一个解决方案:一个8位不够,可以用两个 8 位甚至三个 8 位来表示一个字符,2 个 8 位的数据能表示 65536 个数据,3 个 8 位的数据能表示上千万的数据。。
不过,悲催的是:因为世界文化的多样性,好多人都开始使劲研究这些字符,每一帮人都觉得自己搞的很NB,然后发布一个标准。每一套编码都有自己的方式,而且互不兼容。仅仅常用的中文编码方式就有 Unicode、UTF-8、GB2312、GBK等。
这样的结局就是:非常容易出现乱码。比如一个汉字“中”,在编码 A 里,实际对应的值是1234;可是到编码 B 里,对应的值就是15352。
这 TM 就很尴尬了,当我保存一个“中”字的时候,我用的是 A 编码,这时候,磁盘上存的值是1234,然后下次取的时候忘了我用的是什么编码,就随便用 B 编码去解悉,而在 B 编码里,1234可能根本就没定义,或者定义的是一个别的字符。这样拿 1234 用 B 编码解悉完,看到的人就懵逼了。这就是我们常讲的“乱码”。
为了避免乱码,就需要对数据进行转码。转码就是拿着 1234 强行使用 A 编码解悉,这样就能得到我想要的“中”字。
最后:
其实,我们的计算机处理的都是二进制数值,所有的我们看到的文字,图像,视频,都是要经过转化才能展示给我们看的。编码是对这些数据的不同处理规则,规则匹配了,信息就准确,规则不匹配,信息就没办法还原。其实数据还是那些数据,数据没有对错。