命名实体识别
命名实体的提出源自信息抽取问题,即从报章等非结构化文本中抽取关于公司活动和国防相关活动的结构化信息,而人名、地名、组织机构名、时间和数字表达式结构化信息的关键内容,所以需要从文本中去识别这些实体指称及其类别,即命名实体识别和分类。
21世纪以后,基于大规模语料库的统计方法成为自然语言处理的主流,以下是基于统计模型的命名实体识别方法归纳:
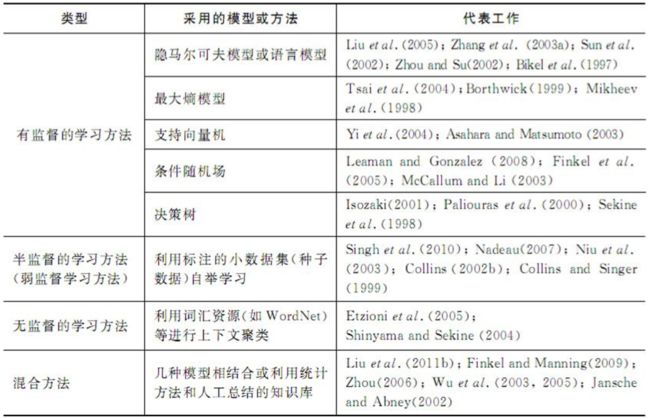
基于CRF的命名实体识别方法
基于CRF的命名实体识别方法简便易行,而且可以获得较好的性能,广泛地应用于人名、地名和组织机构等各种类型命名实体的识别,可以说是命名实体识别中最成功的方法。
其基本思路是,将给定的文本首先进行分词处理,然后对人名、简单地名和简单组织机构名进行识别,最后识别复合地名和复合组织机构名,复合指嵌套关系。
基于CRF的命名实体识别方法属于有监督的学习方法,因此需要利用已标注的大规模语料对CRF模型的参数进行训练。
在训练阶段,首先需要将分词语料的标记转化成用于命名实体序列标注的标记。接下来要做的事情是确定特征模板,特征模板一般采用当前位置的前后2~3个位置上的字串及其标记作为构成特征模型的符号。而且由于不同的命名实体一般出现在不同的上下文语境中,因此对于不同的命名实体(如中国人名、日本人名、欧美人名、俄罗斯人名)识别一般采用不同的特征模板。我们由特征得到特征函数,且不同的特征之间可以组合。
特征函数确定以后,剩下的工作就是训练CRF模型参数了。
基于多特征的命名实体识别方法
在命名实体识别中,无论采用哪一种方法,都是试图发现和利用实体所在的上下文特征和实体的内部特征,只不过特征的颗粒度有大(词性和角色级特征)有小(词形特征)的问题。考虑到大颗粒度特征和小颗粒度特征有互相补充的作用,应该兼顾使用的问题,多特征相融合的汉语命名实体识别方法被提出了。
该方法是在分词和词性标注的基础上进一步进行命名实体的识别,由词形上下文模型、词性上下文模型、词形实体词模型和词性实体词模型4个子模型组成的。
其中,词形上下文模型估计在给定词形上下文语境中产生实体的概率;词性上下文模型估计在给定词性上下文语境中产生实体的概率;词形实体模型估计在给定实体类型的情况下词形串作为实体的概率;词性实体模型估计在给定实体类型的情况下词性串作为实体的概率
系统性能表现主要通过准确率、召回率和F-测度3个指标来衡量。准确率和召回率在前面的文章中讲过了,这里说一下F-测度:

F-测度综合考虑了准确率和召回率。
词性标注
词性(part-of-speech)是词汇基本的语法属性,通常也称为词类。词性标注就是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,是中文信息处理面临的重要基础性问题。
基于统计模型的词性标注方法
我们可以基于HMM去实现词性标注方法,实现基于HMM的词性标注方法中,模型的参数估计是其中的关键问题,也就是HMM的第三个问题,当时我们讲可以随机地初始化HMM的所有参数,但是,这将使词性标注问题过于缺乏限制。
因此,通常利用词典信息约束模型的参数。假设输出符号表由单词构成(即词序列为HMM的观察序列),如果某个对应的『词汇-词性标记』没有被包含在词典中,那该词汇被标记为该词性标记的概率就为0;如果存在,那该词汇被标记为某词汇标记的概率为其所有可能被标记的所有词性个数的倒数:

然后我们根据训练语料给定词性标记生成词的概率,我们思考一下,如何根据训练语料来合理的估计模型概率,对于某词性标记j生成词wl的概率,分子我们用词wl出现的次数乘以该词汇被标记为该词汇标记的概率,分母是在训练语料范围内,所有词被标记为该词汇标记的概率乘以该词出现的次数。某词性标记j生成词wl的概率,也即下式:
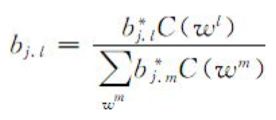
不仅考虑词出现次数的原因,个人理解,一是考虑到前面说过的,有些词是不能由特定词性标记输出的,所以其乘积为0,累加时就会被忽略;二是在估计模型参数时考虑到词本身所可能对应的词性标记的个数,在计算特定词性标记的生成概率时,给予对应词性标记少的词汇一定的优待,给予其一定的概率倾斜。
另外,还有一种方法是采用将词汇划分成若干等价类的策略,以类为单位进行参数统计,进而避免了为每个单词单独调整参数,大大减少了参数的总个数。
一旦初始化完成后,就可以按照HMM的前向后向算法进行训练。
还有一点要注意的是,由于不同领域语料的概率有所差异,HMM的参数也应随着语料的变化而变化。
这就涉及到一个问题,在对原有的训练语料增加新的语料以后,模型的参数就需要重新调整了。而根据经典HMM的理论,也就是上篇讲的HMM,已经训练过的语料就难以再发挥作用了,所以这里希望当有新语料进来时,新旧语料能够同时发挥作用。
只需要对HMM的前向后向算法做一些微调即可,我们还记得,前向后向算法需要根据初始化好的模型去计算转移概率的期望值,再根据期望值去估计模型参数,也即π、aij、bj(k),最终收敛,我们得到了训练完毕的π、aij、bj(k),但是这里我们不只保存π、aij、bj(k),我们还要保存前一步的结果,也就是那些期望值,这样,当新的语料引入时,我们将原来模型中保存的期望值与新语料训练的期望值相加,即得到了反映新旧语料期望值变量的值,通过计算即可得到新的模型。这样也就解决了旧语料的利用问题。
基于规则的词性标注方法
基于规则的词性标注方法是人们提出较早的一种词性标注方法,其基本思想是按兼类词(拥有多种可能词性的词)搭配关系和上下文语境建造词类消歧规则,早期的规则一般由人编写。
然而随着语料库规模的逐步增大,以人工提取规则的方式显然是不现实的,于是人们提出了基于机器学习的规则自动提取方法。如下图所示:
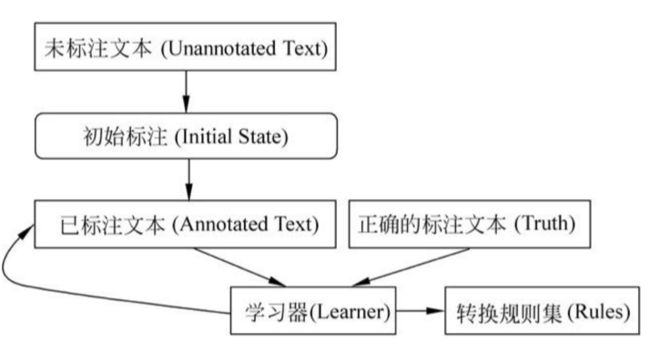
基于规则的错误驱动的机器学习方法的基本思想是,首先运用初始状态标注器标识未标注的文本,由此产生已标注的文本。文本一旦被标注以后,将其与正确的标注文本进行比较,学习器可以从错误中学到一些规则,从而形成一个排序的规则集,使其能够修正已标注的文本,使标注结果更接近于参考答案。
这样,在所有学习到的可能的规则中,搜索那些使已标注文本中的错误数减少最多的规则加入到规则集,并将该规则用于调整已标注的文本,然后对已标注的语料重新打分(统计错误数)。不断重复该过程,直到没有新的规则能够使已标注的语料错误数减少。最终的规则集就是学习到的规则结果。
这种方法的标注速度要快于人工,但仍然存在着学习时间过长的问题,改进方法是,在算法的每次迭代过程中,只调整受到影响的小部分规则,而不需要搜索所有的转换规则。因为每当一条获取的规则对训练语料实施标注后,语料中只有少数词性会发生改变,而只有在词性发生改变的地方,才影响与该位置相关的规则的得分。
统计方法与规则方法相结合的词性标注方法
有人提出了这样一种词性标注方法,其基本思想是,对汉语句子的初始词性标注结果,先经过规则排歧,排除汉语中那些最常见的、语言现象比较明显的歧义现象,然后再通过统计排歧,处理那些剩余的多类词并进行未登录词的词性推断,最后再进行人工校对,得到正确的标注结果。人工校对时可以发现系统中的问题,并进行改进。
但是上面这种方法存在一个很大的问题就是统计的可信度,我们不知道统计结果的可信度,总是需要人工校对所有的统计排歧结果,所以有人又提出了一种新的统计方法与规则方法相结合的词性标注方法。
新的方法通过计算词被标注为所有词性的概率,来对统计标注的结果给出一个可信度,这样对于所有的语料,先经过统计标注,然后对那些可信度小于阈值,或者说错误可能性高于阈值的统计标注结果,才进行人工校对和采用规则方法进行歧义消解。
词性标注的一致性检查与自动校对
在语料库建设中,词性标注的一致性检查和自动校对是不可缺少的重要环节。
一般情况下,语料库中出现的词性标注不一致现象主要由两种,一种情况是,词汇在词表中本来是非兼类词,只有一种词性标记,在语料中却被标注了不同的词性标记;另一种情况是,词汇在词表中本来就是兼类词,允许不同的词性标注,可在标注语料语境相同时出现了不同的词性标注。
第一种现象比较好解决,第二种现象可以采用基于聚类和分类的词性标注一致性检查方法,其基本观点是,同一个词在相似的上下文中应该具有相同的词性。所以,根据训练语料,可以对每个兼类词分别计算出词性标注相同时期上下文语境向量的平均值VA,然后计算该兼类词被标注成每个可能的词性符号时所在的上下文语境向量与相应的VA之间的关系,如果
与VA之间的距离大于了某个阈值H,则认为其可能出现了词性标注不一致。
然后是词性标注的自动校对方法,在计算机自动实现词性标注的语料中,错误情况一般分为两种,一种是,对于同样的情况,如果一个地方出错则通篇有错,一错到底。而另一种情况是,只有部分出错,这也就是前面的一致性问题之一,已经给出了解决方法。
而对于一错到底的情况,处理方法的基本思路实际上也相似,其基本思路是通过机器学习,从大规模训练语料中抽取每个兼类词在特定上下文语境中被标注的词性信息,形成一个词性校对决策表。这里用的不再是平均值了,对于被校对的标注语料,首先检测每个兼类词的上下文语境与决策表中的对应语境是否匹配,若匹配,则认为该校对语料中的兼类词的语境与决策表中的条件一直,那其兼类词的词性也应该一致。
句法分析
句法分析的基本任务是确定句子的语法结构或句子中词汇之间的依存关系。句法分析不是一个自然语言处理任务的最终目标,但它往往是实现最终目标的关键环节。
句法分析分为句法结构分析和依存关系分析两种。以获取整个句子的句法结构为目的的称为完全句法分析,而以获得局部成分为目的的语法分析称为局部分析,依存关系分析简称依存分析。
一般而言,句法分析的任务有三个:
- 判断输出的字符串是否属于某种语言
- 消除输入句子中词法和结构等方面的歧义
- 分析输入句子的内部结构,如成分构成、上下文关系等。
第二三个任务一般是句法分析的主要任务。
一般来说,构造一个句法分析器需要考虑两部分工作:一部分是语法的形式化表示和词条信息描述问题,形式化的语法规则构成了规则库,词条信息等由词典或同义词表等提供,规则库与词典或同义词表构成了句法分析的知识库;另一部分就是基于知识库的解析算法了。
语法形式化属于句法理论研究的范畴,目前在自然语言处理中广泛使用的是上下文无关文法(CFG)和基于约束的文法,后者又称合一文法。
简单的讲,句法结构分析方法可以分为基于规则的分析方法和基于统计的分析方法两大类。
基于规则的句法结构分析方法的基本思路是,由人工组织语法规则,建立语法知识库,通过条件约束和检查来实现句法结构歧义的消除。
根据句法分析树形成方向的区别,人们通常将这些方法划分为三种类型:自顶向下的分析方法,自底向上的分析方法和两者相结合的分析方法。自顶向下分析算法实现的是规则推导的过程,分析树从根结点开始不断生长,最后形成分析句子的叶结点。而自底向上分析算法的实现过程恰好想法,它是从句子符号串开始,执行不断规约的过程,最后形成根节点。
基于规则的语法结构分析可以利用手工编写的规则分析出输入句子所有可能的句法结构;对于特定领域和目的,利用有针对性的规则能够较好的处理句子中的部分歧义和一些超语法(extra-grammatical)现象。
但对于一个中等长度的输入句子来说,要利用大覆盖度的语法规则分析出所有可能的句子结构是非常困难的,而且就算分析出来了,也难以实现有效的消歧,并选择出最有可能的分析结果;手工编写的规则带有一定的主观性,还需要考虑到泛化,在面对复杂语境时正确率难以保证;手工编写规则本身就是一件大工作量的复杂劳动,而且编写的规则领域有密切的相关性,不利于句法分析系统向其他领域移植。
基于规则的句法分析算法能够成功的处理程序设计语言的编译,而对于自然语言的处理却始终难以摆脱困境,是因为程序设计语言中使用的知识严格限制的上下文无关文法的子类,但自然语言处理系统中所使用的形式化描述方法远远超过了上下文无关文法的表达能力;而且人们在使用程序设计语言的时候,一切表达方式都必须服从机器的要求,是一个人服从机器的过程,这个过程是从语言的无限集到有限集的映射过程,而在自然语言处理中则恰恰相反,自然语言处理实现的是机器追踪和服从人的语言,从语言的有限集到无限集推演的过程。
完全语法分析
基于PCFG的基本分析方法
基于概率上下文无关文法的短语结构分析方法,可以说是目前最成功的语法驱动的统计句法分析方法,可以认为是规则方法与统计方法的结合。
PCFG是CFG的扩展,举个例子:

当然,同一个符号不同生成式的概率之和为1。NP是名词短语、VP是动词短语、PP是介词短语。
基于PCFG的句法分析模型,满足以下三个条件:
- 位置不变性:子树的概率不依赖于该子树所管辖的单词在句子中的位置
- 上下文无关性:子树的概率不依赖于子树控制范围以外的单词
- 祖先无关性:子树的概率不依赖于推导出子树的祖先节点
根据上述文法,『He met Jenny with flowers』有两种可能的语法结构:

而且我们可以通过将树中的所有概率相乘,得到两棵子树的整体概率,从中选择概率更大的子树作为最佳结构。
与HMM类似,PCFG也有三个基本问题:
- 给定一个句子W=
w1w2…wn和文法G,如何快速计算概率P(W|G) - 给定一个句子W=
w1w2…wn和文法G,如何选择该句子的最佳结构?即选择句法结构树t使其具有最大概率 - 给定PCFG G和句子W=
w1w2…wn,如何调节G的概率参数,使句子的概率最大
首先是第一个问题,HMM中我们用的是前向算法和后向算法来计算观察序列O概率,相似的,这里我们用的是内向算法和外向算法来计算P(W|G) 。
首先我们定义内向变量αij(A),与前向变量相似但又有不同,αij(A)即非终结符A推导出W中字串wiw(i+1)…wj的概率。那P(W|G)自然就等于α1n(S)了,S是起始符号,计算的就是由起始符号S推导出整个句子W=w1w2…wn的概率。
所以只要有αij(A)的递归公式就能计算出P(W|G),递归公式如下:

根据定义,αii(A)自然就等同于符号A输出wi的概率;而αij(A)的计算思路是,这个子串wiw(i+1)…wj可以被切成两部分处理,前一部分wiw(i+1)…wk由非终结符号B生成,后一部分wkw(k+1)…wj由非终结符号C生成,而BC由A生成。这样将概率依次相乘,即可将一个大问题划分为两个小问题处理,两个小问题又可以进一步划分直到不能划分为止,然后递归回来得到结果。
这里给一张内向变量计算方法示意图:

这个问题也可以用外向算法来解决。
首先定义外向变量,βij(A)是,初始符号S在推导出语句W=w1w2…wn的过程中,产生符号串w1w2…w(i-1)Aw(j+1)…wn的概率(隐含着A会生成wiw(i+1)…wj)。也就是说βij(A)是S推导出除了以A节点为根节点的子树以外的其他部分的概率。
《统计自然语言处理(第二版)》这本书里讲错了,这里我给出我自己的理解,书里给的算法步骤如下:

很明显的错误,初始化都把结果初始化了,那这个算法还算什么,直接等于1就完了呗。
这是作者对外向变量定义理解模糊的问题,上面给了外向变量的定义,里面有一句话『隐含着A会生成wiw(i+1)…wj』,那问题在于,A会生成wiw(i+1)…wj,这到底算是条件还是推论。
看这个算法的初始化的意思,说β1n(A),在A=S的时候,为1,不等于S为0,意思是什么?意思就是『隐含着A会生成wiw(i+1)…wj』这句话是条件,β1n(S)已经隐含了S生成W=w1w2…wn了,所谓的w1w2…w(i-1)Aw(j+1)…wn也就不存在了,只剩下一个S->S了,所以概率自然为1。
但是在第三步这个地方,作者理解成什么意思了呢?作者又把『隐含着A会生成wiw(i+1)…wj』这句话当成推论了,认为在β1n(S),里S会生成W=w1w2…wn是推论,那真是就正好了,要求的结果就是S生成W=w1w2…wn,这不就结束了吗,结果就导致了这个算法第一步初始化都把结果初始化了。
那我的理解是什么呢,通过这个公式计算出来的β1n(S),确实是正确的,意义实际上也是包含了『隐含着A会生成wiw(i+1)…wj』这句话是推论,但是右侧式子里由于不断递归而产生的β1n(S),是把『隐含着A会生成wiw(i+1)…wj』这句话当条件的,所以计算上没有问题。
我倾向于为第三步中的β1n(S)加一个星号,以表明意义的不同。
书中还给了个外向变量的计算方法示意图,我觉得也是莫名其妙:

他说βij(A)是这两种情况的概率和,这我们知道j比i大,那这图里这个k既比i小又比j大,这不是搞笑吗。只能说图上这俩C就不是一个C,k也不是一个k。
那我为什么会理解成一个呢,除了字母相同,他前面还这么讲『必定运用了形如B->AC或者B->CA的规则』、『运用B->AC或者B->CA两种规则的情况』,这明显就是给人以顺序交换的误解。
另外,还在内向变量的使用上前后不一,可以说这本书里对外向算法的讲解是非常失败的。而且对外向算法的计算仍然需要用到内向算法的递归,那真的直接用内向算法就好了,外向算法还要多定义变量。
然后是第二个问题,选择句子的最佳结构,也即给定一个句子W=w1w2…wn和文法G,
选定拥有最大概率的语法结构树。这一问题与HMM中类似,仍然采用动态规划的思想去解决。最后利用CYK算法去生成拥有最大概率的语法结构树。
第三个问题是给定PCFG G和句子W=w1w2…wn,如何调节G的概率参数,使句子的概率最大,与HMM相对的,PCFG这里采用的算法名叫内外向算法。与前后向算法相同,也属于一种EM算法,其基本思想是,首先给G的产生式随机地赋予一个概率值(满足归一化条件),得到文法G0,然后根据G0和训练数据,可以计算出每条规则使用次数的期望值,用期望值进行最大似然估计,得到语法G的新参数值,新的语法记作G1,然后循环执行该过程,G的参数概率将收敛于最大似然估计值。
PCFG只是一种特殊的上下文无关文法模型,根据PCFG的模型和句子,具体去对句子做语法分析,生成语法结构树,靠的是还是CYK算法。CYK算法是一个用来判定任意给定的字符串W是否属于一个上下文无关文法的算法。
基于PCFG的句法分析模型存在有许多问题,比如因为PCFG没有对词汇进行建模,所以存在对词汇信息不敏感的问题。因此人们提出了词汇化的短语结构分析器,有效的提升了基于PCFG的句法分析器的能力。
而且,我们上面也提到了PCFG的三个独立性假设,这也导致了规则之间缺乏结构依赖关系(就像HMM的三个假设也不完全合理一样),而在自然语言中,生成每个非终结符的概率往往是与其上下文结构有关系的,所以有人提出了一种细化非终结符的方法,为每个非终结符标注上其父节点的句法标记信息。
D. Klein提出了带有隐含标记的上下文无关文法(PCFG with latent annotations,PCFG-LA),使得非终结符的细化过程可以自动进行,并且在使用EM算法优化时,为避免到达局部最优,对其进行了改进,提出了一种层次化的『分裂-合并』策略,以期获取一个准确并且紧凑的PCFG-LA模型。基于PCFG-LA的Berkeley Parser作为非词汇化句法分析器的代表,无论是性能表现还是运行速度,都是目前开源的短语结构分析器中最好的。其语法树如下图:

这个x就是隐含标记,xi的取值范围一般是人为设定的,一般取1~16之间的整数。而且PCFG-LA也类似于HMM模型,原始非终结符对应HMM模型中的观察输出,而隐含标记对应HMM模型中的隐含状态。
具体的PCFG-LA训练过程,这里不详述。
浅层语法分析(局部语法分析)
由于完全语法分析要确定句子所包含的全部句法信息,并确定句子中各成分之间的关系,这是一项十分苦难的任务。到目前为止,句法分析器的各方面都难以达到令人满意的程度,为了降低问题的复杂度,同时获得一定的句法结构信息,浅层句法分析应运而生。
浅层语法分析只要求识别句子中的某些结构相对简单的独立成为,例如非递归的名词短语、动词短语等,这些被识别出来的结构通常称为语块(chunk)。
浅层句法分析将句法分析分解为两个主要子任务,一个是语块的识别和分析,另一个是语块之间的依附关系分析。其中,语块的识别和分析是主要任务。在某种程度上说,浅层句法分析使句法分析的任务得到了简化,同时也有利于句法分析系统在大规模真实文本处理系统中迅速得到应用。
基本名词短语(base NP)是语块中的一个重要类别,它指的是简单的、非嵌套的名词短语,不含有其他子项短语,并且base NP之间结构上是独立的。示例如下:

base NP识别就是从句子中识别出所有的base NP,根据这种理解,一个句子中的成分和简单的分为baseNP和非base NP两类,那么base NP识别就成了一个分类问题。
base NP的表示方法有两种,一种是括号分隔法,一种是IOB标注法。括号分隔法就是将base NP用方括号界定边界,内部的是base NP,外部的不属于base NP。IOB标注法中,字母B表示base NP的开端,I表示当前词语在base NP内,O表示词语位于base NP之外。
基于SVM的base NP识别方法
由于base NP识别是多值分类问题,而基础SVM算法解决的是二值分类问题,所以一般可以采用配对策略(pairwise method)和一比其余策略(one vs. other method)。
SVM一般要从上下文的词、词性、base NP标志中提取特征来完成判断。一般使用的词语窗口的长度为5(当前词及其前后各两个词)时识别的效果最好。
基于WINNOW的base NP识别方法
WINNOW是解决二分问题的错误驱动的机器学习方法,该方法能从大量不相关的特征中快速学习。
WINNOW的稀疏网络(SNoW)学习结构是一种多类分类器,专门用于处理特征识别领域的大规模学习任务。WINNOW算法具有处理高维度独立特征空间的能力,而在自然语言处理中的特征向量恰好具有这种特点,因此WINNOW算法也常用于词性标注、拼写错误检查和文本分类等等。
简单WINNOW的基本思想是,已知特征向量和参数向量和实数阈值θ,先将参数向量均初始化为1,将训练样本代入,求特征向量和参数向量的内积,将其与θ比较,如果大于θ,则判定为正例,小于θ则判定为反例,将结果与正确答案作比较,依据结果来改变权值。
如果将正例估计成了反例,那么对于原来值为1的x,把它的权值扩大。如果将反例估计成了正例,那么对于原来值为1的x,把它的权值缩小。然后重新估计重新更改权重,直到训练完成。
这其实让我想到了LR算法,因为LR算法也是特征向量与参数向量的内积,最后将其送到Sigmoid函数中去拿到判定结果,然后大于0.5的为正例,小于0.5的为反例,实际上只要反过来,Sigmod函数输出0.5时候的输入就是WINNOW算法里的那个实数阈值θ。但是区别在于WINNOW算法只判定大小,不判定概率,而LR利用Sigmoid函数给出了概率。LR利用这给出的概率,通过使训练集的生成概率最大化来调整参数,而WINNOW则是直接朴素的错误情况来增大或缩小相关参数。目测LR因为使用了梯度下降,它的收敛速度要快于WINNOW,而WINNOW的优势则在于可以处理大量特征。
基于CRF的base NP识别方法
基于CRF的base NP识别方法拥有与SVM方法几乎一样的效果,优于基于WINNOW的识别方法、基于MEMM的识别方法和感知机方法,而且基于CRF的base NP识别方法在运行速度上较其他方法具有明显优势。
依存语法理论
在自然语言处理中,我们有时不需要或者不仅仅需要整个句子的短语结构树,而且要知道句子中词与词之间的依存关系。用词与词之间的依存关系来描述语言结构的框架成为依存语法,又称从属关系语法。利用依存语法进行句法分析也是自然语言理解的重要手段之一。
有人认为,一切结构语法现象可以概括为关联、组合和转位这三大核心。句法关联建立起词与词之间的从属关系,这种从属关系由支配词和从属词联结而成,谓语中的动词是句子的中心并支配别的成分,它本身不受其他任何成分支配。
依存语法的本质是一种结构语法,它主要研究以谓词为中心而构句时由深层语义结构映现为表层语法结构的状况及条件,谓词与体词之间的同现关系,并据此划分谓词的词类。
常用的依存于法结构图示有三种:

计算机语言学家J. Robinson提出了依存语法的四条公理:
- 一个句子只有一个独立的成分
- 句子的其他成分都从属于某一成分
- 任何一个成分都不能依存于两个或两个以上的成分
- 如果成分A直接从属于成分B,而成分C在句子中位于A和B之间,那么,成分C或者属于成分A,或者从属于B,或者从属于A和B之间的某一成分。
这四条公理相当于对依存图和依存树的形式约束:单一父节点、连通、无环和可投射,由此来保证句子的依存分析结果是一棵有根的树结构。
这里提一下可投射,如果单词之间的依存弧画出来没有任何的交叉,就是可投射的(参考上面的两个有向图)。
为了便于理解,我国学者提出了依存结构树应满足的5个条件:
- 单纯结点条件:只有终结点,没有非终结点
- 单一父结点条件:除根节点没有父结点外,所有的结点都只有一个父结点
- 独根结点条件:一个依存树只能有一个根结点,它支配其他结点
- 非交条件:依存树的树枝不能彼此相交
- 互斥条件:从上到下的支配关系和从左到右的前于关系之间是相互排斥的,如果两个结点之间存在着支配关系,它们就不能存在于前于关系
这五个条件是有交集的,但它们完全从依存表达的空间结构出发,比四条公理更直观更实用。
Gaifman 1965年给出了依存语法的形式化表示,证明了依存语法与上下文无关文法没有什么不同..
类似于上下文无关文法的语言形式对被分析的语言的投射性进行了限制,很难直接处理包含非投射现象的自由语序的语言。20世纪90年代发展起来了约束语法和相应的基于约束满足的依存分析方法,可以处理此类非投射性语言问题。
基于约束满足的分析方法建立在约束依存语法之上,将依存句法分析看做可以用约束满足问题来描述的有限构造问题。
约束依存语法用一系列形式化、描述性的约束将不符合约束的依存分析去掉,直到留下一棵合法的依存树。
生成式依存分析方法、判别式依存分析方法和确定性依存分析方法是数据驱动的统计依存分析中具有代表性的三种方法。
生成性依存分析方法
生成式依存分析方法采用联合概率模型生成一系列依存语法树并赋予其概率分值,然后采用相关算法找到概率打分最高的分析结果作为最后输出。
生成式依存分析模型使用起来比较方便,它的参数训练时只在训练集中寻找相关成分的计数,计算出先验概率。但是,生成式方法采用联合概率模型,再进行概率乘积分解时做了近似性假设和估计,而且,由于采用全局搜索,算法的复杂度较高,因此效率较低,但此类算法在准确率上有一定优势。但是类似于CYK算法的推理方法使得此类模型不易处理非投射性问题。
判别式依存分析方法
判别式依存分析方法采用条件概率模型,避开了联合概率模型所要求的独立性假设(考虑判别模型CRF舍弃了生成模型HMM的独立性假设),训练过程即寻找使目标函数(训练样本生成概率)最大的参数θ(类似Logistic回归和CRF)。
判别式方法不仅在推理时进行穷尽搜索,而且在训练算法上也具有全局最优性,需要在训练实例上重复句法分析过程来迭代参数,训练过程也是推理过程,训练和分析的时间复杂度一致。
确定性依存方法
确定性依存分析方法以特定的方向逐次取一个待分析的词,为每次输入的词产生一个单一的分析结果,直至序列的最后一个词。
这类算法在每一步的分析中都要根据当前分析状态做出决策(如判断其是否与前一个词发生依存关系),因此,这种方法又称决策式分析方法。
通过一个确定的分析动作序列来得到一个唯一的句法表达,即依存图(有时可能会有回溯和修补),这是确定性句法分析方法的基本思想。
短语结构与依存结构之间的关系
短语结构树可以被一一对应地转换成依存关系树,反之则不然。因为一棵依存关系树可能会对应多棵短语结构树。
语义分析
对于不同的语言单位,语义分析的任务各不相同。在词的层次上,语义分析的基本任务是进行词义消歧(WSD),在句子层面上是语义角色标注(SRL),在篇章层面上是指代消歧,也称共指消解。
词义消歧
由于词是能够独立运用的最小语言单位,句子中的每个词的含义及其在特定语境下的相互作用构成了整个句子的含义,因此,词义消歧是句子和篇章语义理解的基础,词义消歧有时也称为词义标注,其任务就是确定一个多义词在给定上下文语境中的具体含义。
词义消歧的方法也分为有监督的消歧方法和无监督的消歧方法,在有监督的消歧方法中,训练数据是已知的,即每个词的词义是被标注了的;而在无监督的消歧方法中,训练数据是未经标注的。
多义词的词义识别问题实际上就是该词的上下文分类问题,还记得词性一致性识别的过程吗,同样也是根据词的上下文来判断词的词性。
有监督词义消歧根据上下文和标注结果完成分类任务。而无监督词义消歧通常被称为聚类任务,使用聚类算法对同一个多义词的所有上下文进行等价类划分,在词义识别的时候,将该词的上下文与各个词义对应上下文的等价类进行比较,通过上下文对应的等价类来确定词的词义。此外,除了有监督和无监督的词义消歧,还有一种基于词典的消歧方法。
在词义消歧方法研究中,我们需要大量测试数据,为了避免手工标注的困难,我们通过人工制造数据的方法来获得大规模训练数据和测试数据。其基本思路是将两个自然词汇合并,创建一个伪词来替代所有出现在语料中的原词汇。带有伪词的文本作为歧义原文本,最初的文本作为消歧后的文本。
有监督的词义消歧方法
有监督的词义消歧方法通过建立分类器,用划分多义词上下文类别的方法来区分多义词的词义。
基于互信息的消歧方法
基于互信息的消歧方法基本思路是,对每个需要消歧的多义词寻找一个上下文特征,这个特征能够可靠地指示该多义词在特定上下文语境中使用的是哪种语义。
互信息是两个随机变量X和Y之间的相关性,X与Y关联越大,越相关,则互信息越大。
这里简单介绍用在机器翻译中的Flip-Flop算法,这种算法适用于这样的条件,A语言中有一个词,它本身有两种意思,到B语言之后,有两种以上的翻译。
我们现在有的,是B语言中该词的多种翻译,以及每种翻译所对应的上下文特征。
我们需要得到的,是B语言中的哪些翻译对应义项1,哪些对应义项2。
这个问题复杂的地方在于,对于普通的词义消歧,比如有两个义项的多义词,词都是同一个,上下文有很多,我们把这些上下文划分为两个等价类;而这种跨语言的,不仅要解决上下文的划分,在这之前还要解决两个义项多种词翻译的划分。
这里面最麻烦的就是要先找到两种义项分别对应的词翻译,和这两种义项分别对应的词翻译所对应的上下文特征,以及他们之间的对应关系。
想象一下,地上有两个圈,代表两个义项;这两个圈里,分别有若干个球,代表了每个义项对应的词翻译;然后这两个圈里还有若干个方块,代表了每个义项在该语言中对应的上下文。然后球和方块之间有线连着(球与球,方块与方块之间没有),随便连接,球可以连多个方块,方块也可以连多个球。然后,圈没了,两个圈里的球和方块都混在了一起,乱七八糟的,你该怎么把属于这两个圈的球和方块分开。
Flip-Flop算法给出的方法是,试试。把方块分成两个集合,球也分成两个集合,然后看看情况怎么样,如果情况不好就继续试,找到最好的划分。然后需要解决的问题就是,怎么判定分的好不好?用互信息。
如果两个上下文集(方块集)和两个词翻译集(球集)之间的互信息大,那我们就认为他们的之间相关关系大,也就与原来两个义项完美划分更接近。
实际上,基于互信息的这种方法直接把词翻译的义项划分也做好了。
基于贝叶斯分类器的消歧方法
基于贝叶斯分类器的消歧方法的思想与《浅谈机器学习基础》中讲的朴素贝叶斯分类算法相同,当时是用来判定垃圾邮件和正常邮件,这里则是用来判定不同义项(义项数可以大于2),我们只需要计算给定上下文语境下,概率最大的词义就好了。
根据贝叶斯公式,两种情况下,分母都可以忽略,所要计算的就是分子,找最大的分子,在垃圾邮件识别中,分子是P(当前邮件所出现的词语|垃圾邮件)P(垃圾邮件),那么乘起来就是垃圾邮件和当前邮件词语出现的联合分布概率,正常邮件同理;而在这里分子是P(当前词语所存在的上下文|某一义项)P(某一义项),这样计算出来的就是某一义项和上下文的联合分布概率,再除以分母P(当前词语所存在的上下文),计算出来的结果就是P(某一义项|当前词语所存在的上下文),就能根据上下文去求得概率最大的义项了。
基于最大熵的词义消歧方法
利用最大熵模型进行词义消歧的基本思想也是把词义消歧看做一个分类问题,即对于某个多义词根据其特定的上下文条件(用特征表示)确定该词的义项。
基于词典的词义消歧方法
基于词典语义定义的消歧方法
M. Lesk 认为词典中的词条本身的定义就可以作为判断其词义的一个很好的条件,就比如英文中的core,在词典中有两个定义,一个是『松树的球果』,另一个是指『用于盛放其它东西的锥形物,比如盛放冰激凌的锥形薄饼』。如果在文本中,出现了『树』、或者出现了『冰』,那么这个core的词义就可以确定了。
我们可以计算词典中不同义项的定义和词语在文本中上下文的相似度,就可以选择最相关的词义了。
基于义类词典的消歧方法
和前面基于词典语义的消歧方法相似,只是采用的不是词典里义项的定义文本,而是采用的整个义项所属的义类,比如ANMINAL、MACHINERY等,不同的上下文语义类有不同的共现词,依靠这个来对多义词的义项进行消歧。
无监督的词义消歧方法
严格地讲,利用完全无监督的消歧方法进行词义标注是不可能的,因为词义标注毕竟需要提供一些关于语义特征的描述信息,但是,词义辨识可以利用完全无监督的机器学习方法实现。
其关键思想在于上下文聚类,计算多义词所出现的语境向量的相似性就可以实现上下文聚类,从而实现词义区分。
语义角色标注概述
语义角色标注是一种浅层语义分析技术,它以句子为单位,不对句子所包含的予以信息进行深入分析,而只是分析句子的谓词-论元结构。具体一点讲,语义角色标注的任务就是以句子的谓词为中心,研究句子中各成分与谓词之间的关系,并且用语义角色来描述它们之间的关系。比如:
实际上就是填槽吧,找到句子中的时间、地点、施事者、受事者和核心谓词。
目前语义角色标注方法过于依赖句法分析的结果,而且领域适应性也太差。
自动语义角色标注是在句法分析的基础上进行的,而句法分析包括短语结构分析、浅层句法分析和依存关系分析,因此,语义角色标注方法也分为基于短语结构树的语义角色标注方法、基于浅层句法分析结果的语义角色标注方法和基于依存句法分析结果的语义角色标注方法三种。
它们的基本流程类似,在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元,也就是说任务是确定的,找出这个任务所需的各个槽位的值。其流程一般都由4个阶段组成:
候选论元剪除的目的就是要从大量的候选项中剪除掉那些不可能成为论元的项,从而减少候选项的数目。
论元辨识阶段的任务是从剪除后的候选项中识别出哪些是真正的论元。论元识别通常被作为一个二值分类问题来解决,即判断一个候选项是否是真正的论元。该阶段不需要对论元的语义角色进行标注。
论元标注阶段要为前一阶段识别出来的论元标注语义角色。论元标注通常被作为一个多值分类问题来解决,其类别集合就是所有的语义角色标签。
最终,后处理阶段的作用是对前面得到的语义角色标注结果进行处理,包括删除语义角色重复的论元等。
基于短语结构树的语义角色标注方法
首先是第一步,候选论元剪除,具体方法如下:
- 将谓词作为当前结点,依次考察它的兄弟结点:如果一个兄弟结点和当前结点在句法结构上不是并列的关系,则将它作为候选项。如果该兄弟结点的句法标签是介词短语,则将它的所有子节点都作为候选项。
- 将当前结点的父结点设为当前结点,重复上一个步骤,直至当前结点是句法树的根结点。
举个例子,候选论元就是图上画圈的:
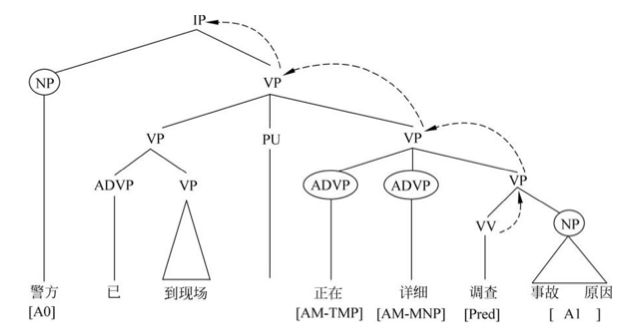
经过剪除得到候选论元之后,进入论元识别阶段,为分类器选择有效的特征。人们总结出了一些常见的有效特征,比如谓词本身、路径、短语类型、位置、语态、中心词、从属类别、论元的第一个词和最后一个词、组合特征等等。
然后进行论元标注,这里也需要找一些对应的特征。然后后处理并不是必须的。
基于依存关系树的语义角色标注方法
该语义角色标注方法是基于依存分析树进行的。由于短语结构树与依存结构树不同,所以基于二者的语义角色标注方法也有不同。
在基于短语结构树的语义角色标方法中,论元被表示为连续的几个词和一个语义角色标签,比如上面图给的『事故 原因』,这两个词一起作为论元A1;而在基于依存关系树的语义角色标注方法中,一个论元被表示为一个中心词和一个语义角色标签,就比如在依存关系树中,『原因』是『事故』的中心词,那只要标注出『原因』是A1论元就可以了,也即谓词-论元关系可以表示为谓词和论元中心词之间的关系。
下面给一个例子:
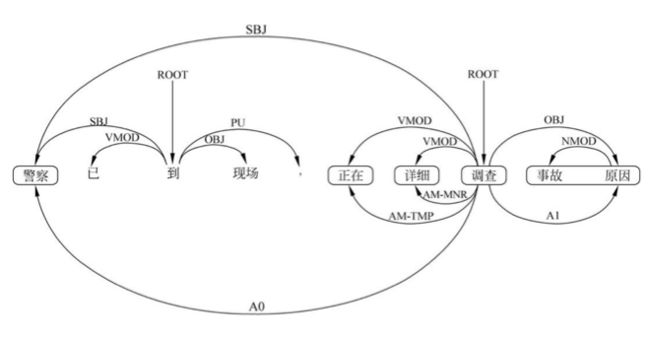
句子上方的是原来的依存关系树,句子下方的则是谓词『调查』和它的各个论元之间的关系。
第一步仍然是论元剪除,具体方法如下:
- 将谓词作为当前结点
- 将当前结点的所有子结点都作为候选项
- 将当前结点的父结点设为当前结点,如果新当前结点是依存句法树的根结点,剪除过程结束,如果不是,执行上一步
论元识别和论元标注仍然是基于特征的分类问题,也有一些人们总结出来的常见特征。这里不详述。
基于语块的语义角色标注方法
我们前面知道,浅层语法分析的结果是base NP标注序列,采用的方法之一是IOB表示法,I表示base NP词中,O表示词外,B表示词首。
基于语块的语义角色标注方法将语义角色标注作为一个序列标注问题来解决。
基于语块的语义角色标注方法一般没有论元剪除这个过程,因为O相当于已经剪除了大量非base NP,也即不可能为论元的内容。论元辨识通常也不需要了,base NP就可以认为是论元。
我们需要做的就是论元标注,为所有的base NP标注好语义角色。与基于短语结构树或依存关系树的语义角色标注方法相比,基于语块的语义角色标注是一个相对简单的过程。
当然,因为没有了树形结构,只是普通序列的话,与前两种结构相比,丢失掉了一部分信息,比如从属关系等。
语义角色标注的融合方法
由于语义角色标注对句法分析的结果有严重的依赖,句法分析产生的错误会直接影响语义角色标注的结果,而进行语义角色标注系统融合是减轻句法分析错误对语义角色标注影响的有效方法。
这里所说的系统融合是将多个语义角色标注系统的结果进行融合,利用不同语义角色标注结果之间的差异性和互补性,综合获得一个最好的结果。
在这种方法中,一般首先根据多个不同语义角色标注结果进行语义角色标注,得到多个语义角色标注结果,然后通过融合技术将每个语义角色标注结果中正确的部分组合起来,获得一个全部正确的语义角色标注结果。
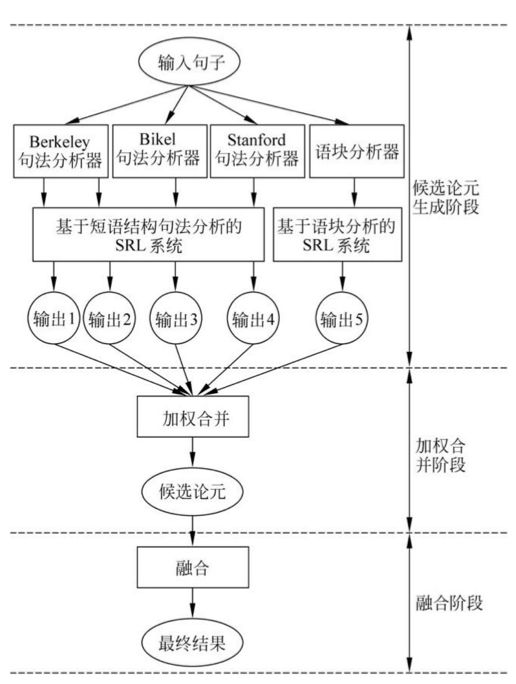
融合方法这里简单说一种基于整数线性规划模型的语义角色标注融合方法,该方法需要被融合的系统输出每个论元的概率,其基本思想是将融合过程作为一个推断问题处理,建立一个带约束的最优化模型,优化目标一般就是让最终语义角色标注结果中所有论元的概率之和最大了,而模型的约束条件则一般来源于人们根据语言学规律和知识所总结出来的经验。
除了基于整数线性规划模型的融合方法之外,人们还研究了若干种其他融合方法,比如最小错误加权的系统融合方法。其基本思想是认为,不应该对所有融合的标注结果都一视同仁,我们在进行融合时应当更多的信赖总体结果较好的系统。
示意图如下:
《浅谈自然语言处理基础》到此结束,四万两千多字,连读书加写文章花了一个月,每天8小时,终于整完了,累到不行。