欢迎关注哈希大数据微信公众号【哈希大数据】获取更多内容
机器学习中有一句名言:数据和特征决定了机器学习的上限,而模型和算法的应用只是让我们无限逼近这个上限。如果不能深刻了解数据特征,将无法建立更精准的机器学习模型或算法,也就不能帮助我们获取最优的学习结果。因此想要更好的了解数据特征,我们便需要在数据分析前期对数据进行大量的预处理和特征分析工作。本节我们将从数据预处理和可视化查看数据特性来重点介绍波士顿房价数据的特征,进而为接下来模型的设计建立基础。
1 房价数据的基本统计分析
从上一节使用Linear Regression方法对波士顿房价数据进行的预测,我们已经大概了解到房价数据的基本特征。
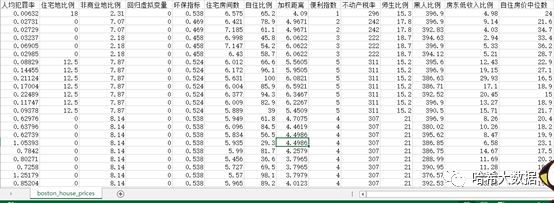
我们要直观了解该数集的规模和属性数目,需要借助.shape方式进行查看,将以元组形式直接返回数据集特征。并且查看其房价分布情况。(以美元为单位)
boston_house_price = datasets.load_boston()house_price_X = boston_house_price.datahouse_price_y = boston_house_price.targetprint('波士顿房价数据特征:',house_price_X.shape)print("最高房价值为:",np.max(boston_house_price_y))print("最低房价值为:",np.min(boston_house_price_y))print("房价的均值为:",np.mean(boston_house_price_y))
波士顿房价数据特征:(506, 13)最高房价值为: 50.0最低房价值为: 5.0房价的均值为: 22.5328063241
需要了解的是,在numpy中对于方差的计算公式如下是不同于数学中的计算方式。通过.var方式可以获得整个特征数据的方差矩阵,进而查看不同特征的分布情况。
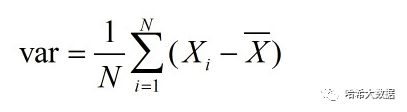
np.var(house_price_train_X, 0.5)np.power(house_price_train_X, 0.5)
2 房价数据的预处理(无量纲)
从上述对房价数据的基本数据分析结果来看,这13个属性特征取值显然不在同一个范围中,比如黑人比例和房屋不动产比例都在300左右,而城市犯罪率和环保比例却很小。当某些特征的样本取值相差甚大时,会导致预测效果变差。因此在分析过程中就需要将数据进行归一化或标准化处理。
在具体操作中,可以忽略特征数据的分布形状,移除每个特征均值,划分离散特征的标准差,从而等级化,进而实现数据中心化。这样更有利于进行进一步分析。
数据标准化(Standardization),或者去除均值和方差进行缩放
数学实现:
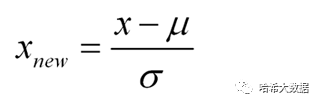
python实现:
from sklearn import preprocessinghouse_price_X_standard = preprocessing.scale(house_price_X)
数据归一化(Normalization),将数据特征的取值缩小到一个范围(常规用0到1)
数学实现:
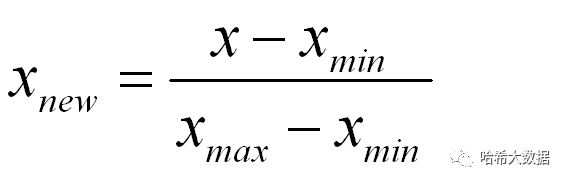
python实现:
house_price_X_norm = preprocessing.MinMaxScaler().fit_transform(house_price_X)
3 房价数据的可视化展示
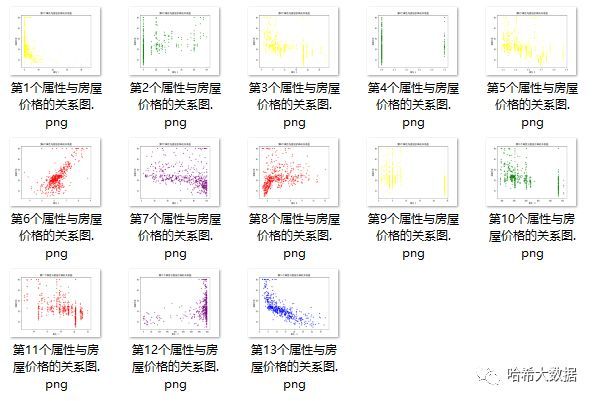
为了更直观的了解每个特征是否与房价有直接相关关系,我们将借助可视化技术进行属性与房价的直观展示。
从可视化结果可以看出,第6个和第8个等属性与房价有明显的正相关性,而第1个、第7个、第13个等属性与房价有明显的负相关性,因此在具体建模中,可以重点抽取这几个特征,将能提高预测结果。
明确数据特性后,我们将在下次分享中,通过机器学习对于不同的特征增加不同的权重,尽可能解决多属性线性相关问题,而且将介绍其他相关模型。以第一个属性实现为例:
colors = ['red','yellow','blue','green','purple','grey']plt.ion()plt.scatter(house_price_X[:, 0], house_price_y, c=random.choice(colors), alpha=1, marker='+')plt.title('第{}个属性与房屋价格的关系图'.format(0 + 1))plt.xlabel('属性 {}'.format(0 + 1))plt.ylabel('房屋价格')plt.savefig('../all_pictures/第1个属性与房屋价格的关系图')plt.pause(2)
房屋数据完整的可视化代码,请回复关键字:house