一 · 前因
具体细节项目相关不宜写出了~
总之吧啦吧啦一顿分析,就怀疑CPU降频了,但是ios却没有获取实时频率的接口。
于是就有了这篇文章了!
二 · 面对困难·解决困难
困难在于ios端没有实时获取CPU频率的接口;
困难如何解决?
查资料、做实验然后的结论呗!!!
查资料后得知:
通常在ios下获取CPU实时频率值是这样干的:
+ (NSUInteger)getSysInfo:(uint)typeSpecifier {
size_t size = sizeof(int);
int results;
int mib[2] = {CTL_HW, typeSpecifier};
sysctl(mib, 2, &results, &size, NULL, 0);
return (NSUInteger)results;
}
+ (NSUInteger)getCpuFrequency {
return [self getSysInfo:HW_CPU_FREQ];
}
但是在真机测试会发现上述方式并不能正确获取到设备的 CPU 频率,如果你在网上搜索会发现有很多代码都是使用这种方式,猜测应该是早期版本还是能够获取到的,只不过出于安全性的考虑,主频这个内核变量也被禁止访问了。
上述代码估计应该是遗留代码。
既然上述方式已经被 Apple 堵死了,我们还有其他的方法可以获取到 CPU 主频吗?
当然,其实我们还是可以通过一些变通的方式获取到的,主要有以下两种方式。
- 第一种方式是比较容易实现,我们通过硬编码的方式,建立一张机型和 CPU 主频的映射表,然后根据机型找到对应的 CPU 主频即可。
static const NSUInteger CPUFrequencyTable[] = {
[iPhone_1G] = 412,
[iPhone_3G] = 620,
[iPhone_3GS] = 600,
[iPhone_4] = 800,
[iPhone_4_Verizon] = 800,
[iPhone_4S] = 800,
[iPhone_5_GSM] = 1300,
[iPhone_5_CDMA] = 1300,
[iPhone_5C] = 1000,
[iPhone_5S] = 1300,
[iPhone_6] = 1400,
[iPhone_6_Plus] = 1400,
[iPhone_6S] = 1850,
[iPhone_6S_Plus] = 1850,
[iPod_Touch_1G] = 400,
[iPod_Touch_2G] = 533,
[iPod_Touch_3G] = 600,
[iPod_Touch_4G] = 800,
[iPod_Touch_5] = 1000,
[iPad_1] = 1000,
[iPad_2_CDMA] = 1000,
[iPad_2_GSM] = 1000,
[iPad_2_WiFi] = 1000,
[iPad_3_WiFi] = 1000,
[iPad_3_GSM] = 1000,
[iPad_3_CDMA] = 1000,
[iPad_4_WiFi] = 1400,
[iPad_4_GSM] = 1400,
[iPad_4_CDMA] = 1400,
[iPad_Air] = 1400,
[iPad_Air_Cellular] = 1400,
[iPad_Air_2] = 1500,
[iPad_Air_2_Cellular] = 1500,
[iPad_Pro] = 2260,
[iPad_Mini_WiFi] = 1000,
[iPad_Mini_GSM] = 1000,
[iPad_Mini_CDMA] = 1000,
[iPad_Mini_2] = 1300,
[iPad_Mini_2_Cellular] = 1300,
[iPad_Mini_3] = 1300,
[iPad_Mini_3_Cellular] = 1300,
[iUnknown] = 0
};
小结:上述实现的缺点是没有考虑到调频的问题啊,要是调频你给我个最高频有啥意义,因此这里只能在特定场合才有用。
- 第二种方式实现起来较上一种方式更为复杂,可以通过计算来得出 CPU 频率,具体的代码如下:
注意:看这里,这才是原作者!作者讲了实现没讲原理,且没兼容架构我这里补充下吧!
原作者是用单独汇编文件写的,这样要处理堆栈的哟~其次记得把_freqTest标记为globl哈~
- 原理:文件内是根据传进来的循环参数(默认传到r0),跑r0遍!
- 每一遍就是 130条add指令(什么?你问为什么不考虑双发射还有乱序执行这些因素的影响?别急稍后我会讲解的!)
.text
.text
.align 4
.globl _freqTest
_freqTest:
STP x4, x5, [sp, #16 * 0]
STP x6, x7, [sp, #16 * 1]
STP x8, x9, [sp, #16 * 2]
STP x10, x11, [sp, #16 * 3]
freqTest_LOOP:
// loop x 10
add r2, r2, r1
add r3, r3, r2
add r4, r4, r3
add r5, r5, r4
add r6, r6, r5
add r7, r7, r6
add r8, r8, r7
add r9, r9, r8
add r10, r10, r9
add r11, r11, r10
add r12, r12, r11
add r14, r14, r12
add r1, r1, r14
...
subs r0, r0, #1
bne freqTest_LOOP
然后在AppDelegate.m文件内加入如下内容:
- 把汇编文件cpuFreq.s内的freqTest函数给申明进来!
- 计算500次,然后取其中时间最少的一次,从而排除系统扰动干扰,得到最高频率值!
- 每一次调用都是传循环参数10000,也就是执行add指令130*10000次,因此最后算频率的时候是1300000/time,也就是单位时间(s)内执行cycles的数量!!!(注意:这里是假设每条add指令是刚好花1个cycle,真是这样嘛?为什么是这样呢?稍后分析!)
extern int freqTest(int cycles);
static double GetCPUFrequency(void)
{
volatile NSTimeInterval times[500];
int sum = 0;
for(int i = 0; i < 500; I++)
{
times[i] = [[NSProcessInfo processInfo] systemUptime];
sum += freqTest(10000);
times[i] = [[NSProcessInfo processInfo] systemUptime] - times[I];
}
NSTimeInterval time = times[0];
for(int i = 1; i < 500; I++)
{
if(time > times[I])
time = times[I];
}
double freq = 1300000.0 / time;
return freq;
}
因此为了方便我直接写的内嵌汇编版本,嗯~优点嘛~就是写起来方便啊!同时测试精度貌似高一丢丢,在iphone6s上测试内嵌汇编方式为1.847GHz,汇编文件方式为1.849GHz;
注意:android里面是用asm volatile(),而ios里面是用__asm volatile();
static double GetCPUFrequency(void)
{
volatile NSTimeInterval times[500] = {0.0};
int sum = 0;
for(int i = 0; i < 20; I++)
{
times[i] = [[NSProcessInfo processInfo] systemUptime];
#if 0
sum += freqTest(10000);
#else
int count = 10000;
asm volatile(
"0:"
//loop 1
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 2
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 3
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 4
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 5
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 6
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 7
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 8
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop 9
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
//loop q10
"add x2, x2, x1 \n"
"add x3, x3, x2 \n"
"add x4, x4, x3 \n"
"add x5, x5, x4 \n"
"add x6, x6, x5 \n"
"add x7, x7, x6 \n"
"add x8, x8, x7 \n"
"add x9, x9, x8 \n"
"add x10, x10, x9 \n"
"add x11, x11, x10 \n"
"add x12, x12, x11 \n"
"add x14, x14, x12 \n"
"add x1, x1, x14 \n"
"subs %x0, %x0, #1 \n"
"bne 0b \n"
:
"=r"(count)
:
"0"(count)
: "cc", "memory", "x1", "x2", "x3","x4", "x5", "x6", "x7", "x8","x9", "x10", "x11", "x12", "x13","x14"
);
#endif
times[i] = 1000.0*([[NSProcessInfo processInfo] systemUptime] - times[i]);//for ms
}
诺~一个函数就搞定了!之前还得单独加个文件,貌似有点麻烦~
注意:配合你的循环以及机器主频计算好总的时间,不要太长从而影响原工作流程啊!比如我这里是33ms的循环体,你就不要占用太长时间了,因此我这里改为测20次,大概十几ms的样子,还可以接受!
三 · 测试结果
可以看到实时主频的变换跟forward时间变换特点一致,因此可知是降频导致的该问题!

那么问题来了,是什么导致主频降低的呢?
首先从实验得知:加大计算量可以防止降频,不进行GPU渲染也不会降频!
那会不会是你这30ms里面大部分时间都在玩,因此把你主频给降下去?
这个说不通,因为我把帧率降到25FPS也不会降频了啊!
那我们先看下流程吧:
···待续
四 · 深入解释下汇编部分的原理
4.1 预备知识以及数据
什么?你问我深入解释到底有多深入?
嗯,这么跟你说吧!
“到底了!”
首先你得知道流水线里面的data hazard概念,其次就是流水线里面的多发射以及乱序发射的概念。
在我的其他篇幅里面有做分析讲解的,这里简要说下:
hazard就是流水线中有资源冲突时需要停下来等待资源的过程;
白话就是:银行大门口一条队伍排队去办理特殊业务,该业务只有一个窗口,同时前面有人正在办理,因此你就必须等待前面的人办理完你才能上。乱序就是在reording buffer里面寻思着在等待的时候找些无关的后续指令来提前执行;
白话就是:排队的人中有的是办理其他业务的所以让他先你而去办理其他业务多发射就是我在取指令、译码、reording buffer之后,我寻思着一次可以同时执行多少条指令的过程;
白话:银行支持同时开设各种窗口,因此配合乱序的特点,你就可以在同一时刻多个人办理资源不冲突的业务了。
这是苹果cyclone系列cpu的部分信息:
https://www.anandtech.com/show/7910/apples-cyclone-microarchitecture-detailed
苹果各系列的参数总结(by 韩哥):

下图是A6、A7的详细参数:可知由cpu代号由swift变为cyclone了,细节参数见图:

cyclone架构的信息如下:
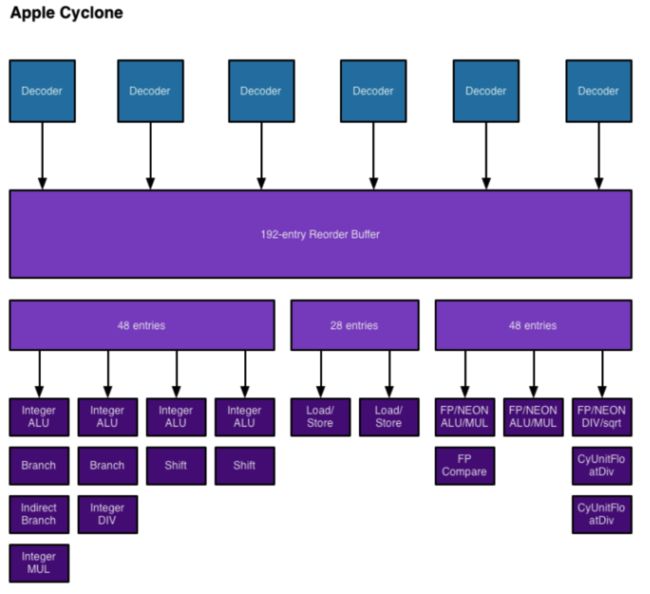
可以看到有6哥解码器,192个条目的reorder buffer,9路硬件单元支路(注意:只支持6发射哈~);
下面是网传的数据:

这些个参数是对64bit的cyclone芯片的;
我尤其关注加载延迟跟分支预测失败的penalty,居然差四倍之多,因此这个地方最好做个实验看看哈~
实测。。。然并暖~我们这种CNN式循环体貌似根本就不会有啥性能变化啊~
前面讲了一堆苹果cpu的参数,估计你也不感兴趣~
接下来讲为什么那段汇编代码能测主频,以及设计的原理是啥吧!
4.2 原理解释
你看我们有6个解码器对吧,那就是说解码速度贼快咯,而且带宽还大,因此我们就弄个缓冲区把你解的指令先缓冲起来,然后里面的指令哪些先满足条件就先执行,你看这是不是就跟乱序机制非常搭~
这个缓冲区的大小是192 entry,也就是说最多可以有192条解码后待执行的指令存储在里面;
现在我们设计的汇编block如图中所示,13条add指令,前一条指令的输出是下一条指令的输入,因此形成了RAW hazard,因此第二条指令必须等第一条指令写回才可继续执行,因此刚好要等一个cycles(由于是最简单的ALU,因此可以保证是一个cycle即可写回,这也是为什么选择add指令的原因),这样平均下来就是每个指令都需要配一个cycle。
4.3 灵魂三问?
细心的可能会问了:
问题1: 你图中明明画了有6发射,同时有4个ALU单元,也就是说同时可以执行4个add指令,那你为什么说平均一个cycle执行一条,不应该是一个cycle执行4条么?请被告方给出合理解释?!!
嗯~这个~
首先4个ALU并不一定都能执行add指令的,你往前翻翻,那个Apple cyclone架构图中就说了每个ALU都有自己特定任务的,平台不同任务不一定相同,最好做个实验就确定了!
其次,我们假设四条指令给四发射发出去了,但是由于hazard的存在,你ALU1也得等ALU0的数据处理完才能接着处理啊!同理ALU2、ALU3也是如此!因此多发射在这里就被卡的死死的~
有一定基础同学可能继续追问了:
问题2: 既然是链式互锁的RAW hazard那你为什么还要用14个寄存器啊,按照你的说法两个寄存器就行了啊!?
哈哈哈哈哈~
回答问题好累啊!特别是我这种自己想问题,自己演,最后还得自己答的这种~

你看哈,wiki里面介绍说了苹果的A9芯片是从ARM A57公版修改而来的,因此我们看下A57的资料嘛!
图片资料来源:《Cortex_A57_Software_Optimization_Guide_external》
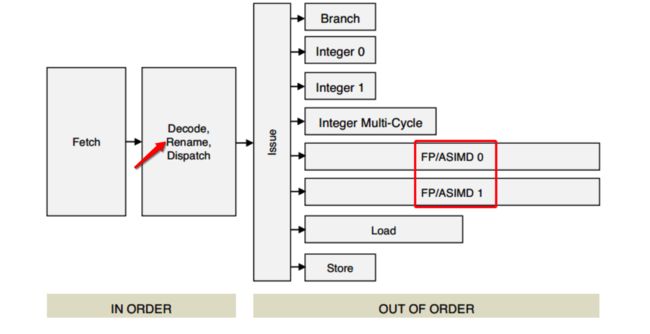
看到解码后面的Rename没?就是来破你这个问题的:假如你只用两个寄存器,那么我就在发射四条指令时把寄存器给重命名,从而就可以实现真正多发射从而并发执行了,不用谢,实验我都给你们做了:
asm volatile(
"0:"
//loop 1
"add x2, x2, x1 \n"
"add x3, x2, x3 \n"
"add x2, x2, x1 \n"
"add x3, x2, x3 \n"
"add x2, x2, x1 \n"
"add x3, x2, x3 \n"
"add x2, x2, x1 \n"
"add x3, x2, x3 \n"
"add x2, x2, x1 \n"
"add x3, x2, x3 \n"
"subs %x0, %x0, #1 \n"
"bne 0b \n"
:
"=r"(count)
:
"0"(count)
: "cc", "memory", "x1", "x2", "x3","x4", "x5", "x6", "x7", "x8","x9", "x10", "x11", "x12", "x13","x14"
);
测试设备:iphone6 pus 系统版本: ios11
正常测试结果是:the cpu frequency is 1391.9 MHz
这里测试结果是:the cpu frequency is 2783.7 MHz
可以看到测试值变高了,也就是执行add指令的时间变少了,那就是超标量执行了嘛~超标量就是多发射了嘛~多发射就是寄存器重命名搞的鬼嘛~(这里的值刚好是2.8G是两倍主频值,也就是说IPC=2,也就是说双发射了,也就是说4个ALU里面能执行add指令的只有两个,往回翻翻对应着看下那个图哈~)至此,破案~
结论是:寄存器重命名这个划重点啊!期末考试要考的!
问题3: 那个LOOP块为什么要重复10次啊,为什么是10呢?9不行嘛?20不行嘛?
这个问题就太简单了!你想啊,我们算的频率的时候是不是按照130条ADD指令来算的!其实在1000次循环中bne分支指令也是跑了的啊!也是耗时的啊!但是这个时间不大好计算,因此我们把add block搞大点循环次数减少点,让bne分支指令在其中占的比例降低点,从而使得整体的相对精读提高点!
这也就是为什么我们的测试值总是比主频低一点点的原因!
你看吧!处处是哲学,都来自于生活!