[toc]
手动实现一个单词统计MapReduce程序与过程原理分析
前言
我们知道,在搭建好hadoop环境后,可以运行wordcount程序来体验一下hadoop的功能,该程序在hadoop目录下的share/hadoop/mapreduce目录中,通过下面的命令:
yarn jar $HADOOP_HOME/share/hadoop/mapreducehadoop-mapreduce-examples-2.6.4.jar wordcount inputPath outPath即可对输入文件执行单词统计的计算。
那么下面就通过手动写一个wordcount的例子来加深对MapReduce的基本理解。
案例场景
假如有下面一个文本文件需要进行单词统计:
$ cat hello
hello you
hello he
hello meNote:该hello文件为李老师的经典文本文件。
下面就来演示MapReduce程序如何来对该文本文件进行计算,最后再依据此写一个wordcount程序。
MapReduce计算分析
我们先来简单分析一下MapReduce是如何处理上面的文本文件,然后才写一个程序。
对于上面的一个文本文件,MapReduce程序分三个步骤进行处理:Map阶段、Shuffle阶段和Reduce阶段。(三个阶段的分析在代码的注释中也是非常详细的解释)
Map阶段
上面的文本文件经过Map处理后会得到类似下面的结果:
shuffle阶段
对Map阶段的结果进行处理,会得到如下的结果:
Reduce阶段
经过reducer处理之后,结果如下:
关于上面的过程分析,可以参考下面的几张图示以帮助理解:
图示1:
图示2: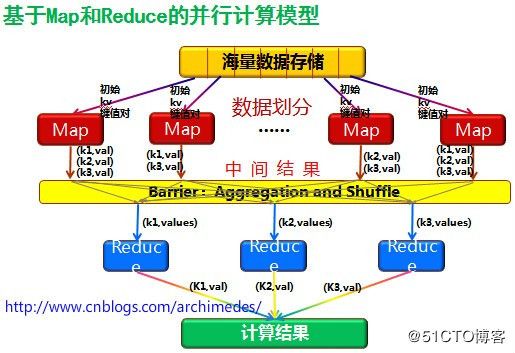
图示3: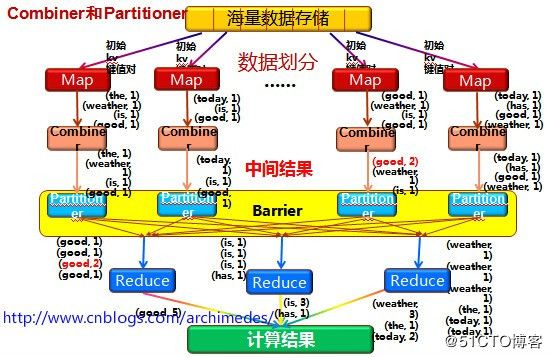
程序思路分析
* 整个的解题思路,使用map函数进行单词的拆分,使用reduce函数进行汇总,中间进行shuffle
* 要想让我们的map函数和reduce函数进行接替运行,需要一个驱动程序
* 代码的思路:
* 1、编写一个类继承Mapper,成为自定义的Mapper,主要业务逻辑就是复写其中的map函数
* map
* 首先要确定清楚Mapper类或者map函数的数据类型/类型参数--->泛型
* Mapper
* 2、编写一个类继承Reducer,成为自定义的Reducer,主要业务逻辑就是复写其中的reduce函数
* reduce
* 首先要确定清楚Reducer类或者reduce函数它的数据类型/类型参数--->泛型
* Reducer
*
* 需要我们用户自定义的类型就是K2, V2, K3, V3
* K1和V1一般情况下是固定的,只要数据格式确定,其类型就确定
* 比如我们操作的是普通的文本文件,那么K1=LongWritable,V1=Text
* K1--->代表的是这一行记录在整个文本中的偏移量,V1就是这一行文本的内容
* (也就是说,K1和V1取决于我们要处理的是什么文件)
* 注意:与Hadoop的程序需要使用Hadoop提供的数据类型,而不能使用java中提供的数据类型 wordcount程序
程序代码中有非常详细的注释,可以参考来进行理解。
WordCount.java
package com.uplooking.bigdata.mr.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 统计hdfs://uplooking01:9000/input/mr/hello的单词出现次数
*
* 整个的解题思路,使用map函数进行单词的拆分,使用reduce函数进行汇总,中间进行shuffle
* 要想让我们的map函数和reduce函数进行接替运行,需要一个驱动程序
* 代码的思路:
* 1、编写一个类继承Mapper,成为自定义的Mapper,主要业务逻辑就是复写其中的map函数
* map
* 首先要确定清楚Mapper类或者map函数的数据类型/类型参数--->泛型
* Mapper
* 2、编写一个类继承Reducer,成为自定义的Reducer,主要业务逻辑就是复写其中的reduce函数
* reduce
* 首先要确定清楚Reducer类或者reduce函数它的数据类型/类型参数--->泛型
* Reducer
*
* 需要我们用户自定义的类型就是K2, V2, K3, V3
* K1和V1一般情况下是固定的,只要数据格式确定,其类型就确定
* 比如我们操作的是普通的文本文件,那么K1=LongWritable,V1=Text
* K1--->代表的是这一行记录在整个文本中的偏移量,V1就是这一行文本的内容
* (也就是说,K1和V1取决于我们要处理的是什么文件)
* 注意:与Hadoop的程序需要使用Hadoop提供的数据类型,而不能使用java中提供的数据类型
*/
public class WordCount {
/**
* 这里的main函数就是用来组织map函数和reduce函数的
* 最终mr的运行会转变成一个个的Job
*
* @param args
*/
public static void main(String[] args) throws Exception {
// 构建Job所需的配置文件和jobName
Configuration configuration = new Configuration();
String jobName = "wordcount";
// 1.创建一个job
Job job = Job.getInstance(configuration, jobName);
// 添加mr要运行的主函数所在的类,就是WordCount这个类
job.setJarByClass(WordCount.class);
// 2.设置mr的输入参数
// 设置计算的文件
Path inputPath = new Path("hdfs://uplooking01:9000/input/mr/hello");
FileInputFormat.setInputPaths(job, inputPath);
// 指定解析数据源的Format类,即将输入的数据解析为的形式,然后再交由mapper函数处理
job.setInputFormatClass(TextInputFormat.class);
// 指定使用哪个mapper来进行计算
job.setMapperClass(WordCountMapper.class);
// 指定mapper结果的key的数据类型(即K2的数据类型),注意要与我们写的Mapper中定义的一致
job.setMapOutputKeyClass(Text.class);
// 指定mapper结果的value的数据类型(即V2的数据类型),注意要与我们写的Mapper中定义的一致
job.setMapOutputValueClass(IntWritable.class);
// 3.设置mr的输出参数
// 设置输出的目录
Path outputPath = new Path("hdfs://uplooking01:9000/output/mr/wc");
// 如果outputPath目录存在,会抛出目录存在异常,这里先删除,保证该目录不存在
outputPath.getFileSystem(configuration).delete(outputPath, true);
FileOutputFormat.setOutputPath(job, outputPath);
// 指定格式化数据结果的Format类
job.setOutputFormatClass(TextOutputFormat.class);
// 指定使用哪个reducer来进行汇总
job.setReducerClass(WordCountReducer.class);
// 指定reduce结果的key的数据类型(即K3的数据类型),注意要与我们写的Reducer中定义的一致
job.setOutputKeyClass(Text.class);
// 指定reduce结果的value的数据类型(即V3的数据类型),注意要与我们写的Reducer中定义的一致
job.setOutputValueClass(IntWritable.class);
// 设置有几个reducer来执行mr程序,默认为1个
job.setNumReduceTasks(1);
// 提交mapreduce job
job.waitForCompletion(true);
}
} WordCountMapper.java
package com.uplooking.bigdata.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 1、编写一个类继承Mapper,成为自定义的Mapper,主要业务逻辑就是复写其中的map函数
* map
* 首先要确定清楚Mapper类或者map函数的数据类型/类型参数--->泛型
* Mapper
* K1:行的偏移量,如第998行
* V1:行的内容,如 hello you
* K2:输出的数据的key值,如hello
* V2:输出的数据的value值,如1
* 注意,为了减少在网络中传输的数据,map之后得到的结果还需要进行shuffle,将相同key的value汇总起来:
* 如:
* map后的结果有:, , , , ,
* shuffle后的结果为:, , ,
* 这样相比原来map的结果,数据的量就少了许多
*/
public class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
// 先将每一行转换为java的String类型
String line = v1.toString();
// 将行中的单词以空格作为分隔符分离出来得到一个字符串数组
String[] words = line.split(" ");
// 定义输出数据的变量k2和v2,类型分别为Text和IntWritable
Text k2 = null;
IntWritable v2 = null;
// 统计单词并写入到上下文变量context中
for (String word : words) {
k2 = new Text(word);
v2 = new IntWritable(1);
context.write(k2, v2);
}
}
} WordCountReducer.java
package com.uplooking.bigdata.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 2、编写一个类继承Reducer,成为自定义的Reducer,主要业务逻辑就是复写其中的reduce函数
* reduce
* 首先要确定清楚Reducer类或者reduce函数它的数据类型/类型参数--->泛型
* Reducer
* K2:map输出中的key值
* V2s:map输出中根据本周key值shuffle后得到的可迭代列表
* 如:, , ,
* K3:reduce输出中的key值
* V3:reduce输出中的value值
*/
public class WordCountReducer extends Reducer {
@Override
protected void reduce(Text k2, Iterable v2s, Context context) throws IOException, InterruptedException {
// 定义某个key值k2出现次数的变量
int sum = 0;
// 统计k2孤个数
for (IntWritable item : v2s) {
sum += item.get();
}
// 构建reduce输出的k3和v3,类型分别为Text和IntWritable
Text k3 = k2;
IntWritable v3 = new IntWritable(sum);
// 结果reduce结果写入到上下文变量context中
context.write(k2, v3);
}
} 测试
将上面的程序打包成jar包,然后上传到我们的hadoop服务器上,执行下面的命令:
yarn jar wordcount.jar com.uplooking.bigdata.mr.wc.WordCount这样就可以使用在hadoop中使用我们自己写的wodcount程序来进行MapReduce的计算。
任务执行结束后,通过下面的命令查看结果:
$ hdfs dfs -cat /output/mr/wc/part-r-00000
18/03/03 13:59:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
he 1
hello 3
me 1
you 1这样就完成了从编写MR程序到测试的完整过程。