Professional CUDA C Programing
代码下载:http://www.wrox.com/WileyCDA/WroxTitle/Professional-CUDA-C-Programming.productCd-1118739329,descCd-DOWNLOAD.html
Dynamic Parallelism
到目前为止,所有kernel都是在host端调用,GPU的工作完全在CPU的控制下。CUDA Dynamic Parallelism允许GPU kernel在device端创建调用。Dynamic Parallelism使递归更容易实现和理解,由于启动的配置可以由device上的thread在运行时决定,这也减少了host和device之间传递数据和执行控制。通过动态并行性,可以直到程序运行时才推迟确定在GPU上创建有多少块和网格,利用GPU硬件调度器和负载平衡动态地适应数据驱动的决策或工作负载。
Nested Execution(嵌套执行)
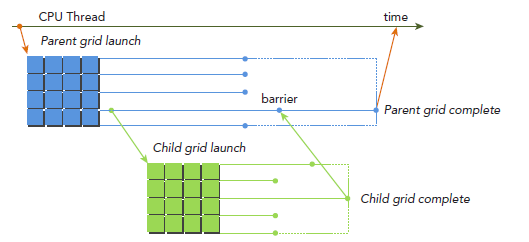
在host调用kernel和在device调用kernel的语法完全一样。kernel的执行则被分为两种类型:parent和child。一个parent thread,parent block或者parent grid可以启动一个新的grid,即child grid。child grid必须在parent 之前完成,也就是说,parent必须等待所有child完成。当parent启动一个child grid时,在parent显式调用synchronize之前,child不保证会开始执行。parent和child共享同一个global和constant memory,但是有不同的shared 和local memory。不难理解的是,只有两个时刻可以保证child和parent见到的global memory完全一致:child刚开始和child完成。所有parent对global memory的操作对child都是可见的,而child对global memory的操作只有在parent进行synchronize操作后对parent才是可见的。
Nested Hello World on the GPU
为了更好地理解dynamic parallelism,我们重新编写hello world算法。host主机调用了parent grid,该parent grid的single block只有8个thread。parent中的thread0调用了child grid_1,child grid_1只有parent grid 一半的thread(4 threads),接着child grid_1中的thread0又调用了child grid_2(2 threads),接着child grid_2 中的thread0又调用了一个child grid_3(1 thread)。
-
parent grid 只有1个block
 Screenshot from 2017-05-03 14:43:17.png
Screenshot from 2017-05-03 14:43:17.png
__global__ void nestedHelloWorld(int const iSize, int iDepth)
{
int tid = threadIdx.x;
printf("Recursion=%d: Hello World from thread %d block %d\n", iDepth, tid,
blockIdx.x);
// condition to stop recursive execution
if (iSize == 1) return;
// reduce block size to half
int nthreads = iSize >> 1;
// thread 0 launches child grid recursively
if(tid == 0 && nthreads > 0)
{
nestedHelloWorld<<<1, nthreads>>>(nthreads, ++iDepth);
printf("-------> nested execution depth: %d\n", iDepth);
}
}
编译
$ nvcc -arch=sm_35 -rdc=true nestedHelloWorld.cu -o nestedHelloWorld -lcudadevrt
-lcudadevrt是用来连接runtime库的,rdc=true使device代码可重入,这是DynamicParallelism所必须的。
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ nvcc -arch=sm_35 -rdc=true nestedHelloWorld.cu -o nestedHelloWorld -lcudadevrt
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ ./nestedHelloWorld
./nestedHelloWorld Execution Configuration: grid 1 block 8
Recursion=0: Hello World from thread 0 block 0
Recursion=0: Hello World from thread 1 block 0
Recursion=0: Hello World from thread 2 block 0
Recursion=0: Hello World from thread 3 block 0
Recursion=0: Hello World from thread 4 block 0
Recursion=0: Hello World from thread 5 block 0
Recursion=0: Hello World from thread 6 block 0
Recursion=0: Hello World from thread 7 block 0
-------> nested execution depth: 1
Recursion=1: Hello World from thread 0 block 0
Recursion=1: Hello World from thread 1 block 0
Recursion=1: Hello World from thread 2 block 0
Recursion=1: Hello World from thread 3 block 0
-------> nested execution depth: 2
Recursion=2: Hello World from thread 0 block 0
Recursion=2: Hello World from thread 1 block 0
-------> nested execution depth: 3
Recursion=3: Hello World from thread 0 block 0
可以用nvvp观察parent和child的执行情况:
nvvp ./nestedHelloWorld
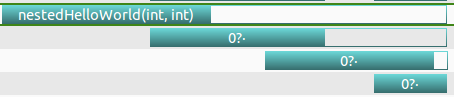
注意:蓝色的表示执行,空白部分表示等待,parent grid nestedHelloWorld执行了一次,调用了3次nestedHelloWorld。从最后一行往上看,最后一行表示depth=3调用,当该调用完成时,depth=2的调用才可以结束,当depth=2的调用结束后depth=1的才可以结束,最后parent grid才能结束。
- parent grid 有2个block
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ ./nestedHelloWorld 2
./nestedHelloWorld Execution Configuration: grid 2 block 8
Recursion=0: Hello World from thread 0 block 0
Recursion=0: Hello World from thread 1 block 0
Recursion=0: Hello World from thread 2 block 0
Recursion=0: Hello World from thread 3 block 0
Recursion=0: Hello World from thread 4 block 0
Recursion=0: Hello World from thread 5 block 0
Recursion=0: Hello World from thread 6 block 0
Recursion=0: Hello World from thread 7 block 0
Recursion=0: Hello World from thread 0 block 1
Recursion=0: Hello World from thread 1 block 1
Recursion=0: Hello World from thread 2 block 1
Recursion=0: Hello World from thread 3 block 1
Recursion=0: Hello World from thread 4 block 1
Recursion=0: Hello World from thread 5 block 1
Recursion=0: Hello World from thread 6 block 1
Recursion=0: Hello World from thread 7 block 1
-------> nested execution depth: 1
-------> nested execution depth: 1
Recursion=1: Hello World from thread 0 block 0
Recursion=1: Hello World from thread 1 block 0
Recursion=1: Hello World from thread 2 block 0
Recursion=1: Hello World from thread 3 block 0
Recursion=1: Hello World from thread 0 block 0
Recursion=1: Hello World from thread 1 block 0
Recursion=1: Hello World from thread 2 block 0
Recursion=1: Hello World from thread 3 block 0
-------> nested execution depth: 2
-------> nested execution depth: 2
Recursion=2: Hello World from thread 0 block 0
Recursion=2: Hello World from thread 1 block 0
Recursion=2: Hello World from thread 0 block 0
Recursion=2: Hello World from thread 1 block 0
-------> nested execution depth: 3
-------> nested execution depth: 3
Recursion=3: Hello World from thread 0 block 0
Recursion=3: Hello World from thread 0 block 0
从上面结果来看,首先应该注意到,所有child的block的id都是0。下图是调用过程,parent有两个block了,但是所有child都只有一个blcok:
nestedHelloWorld<<<1, nthreads>>>(nthreads, ++iDepth);

注意:Dynamic Parallelism只有在计算能力3.5以上才被支持。通过Dynamic Parallelism调用的kernel不能执行于不同的device(物理上实际存在的)上。调用的最大深度是24,但实际情况是,kernel要受限于memory资源,其中包括为了同步parent和child而需要的额外的memory资源。
Nested Reduction
Reduction可以很自然地描述成一个递归的过程。
// Recursive Implementation of Interleaved Pair Approach
int cpuRecursiveReduce(int *data, int const size)
{
// stop condition
if (size == 1) return data[0];
// renew the stride
int const stride = size / 2;
// in-place reduction
for (int i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
// call recursively
return cpuRecursiveReduce(data, stride);
}
Dynamic parallelism:parent grid 有很多个blocks,但是所有的child grid都被parent的thread0调用,并且child grid只有一个block。第一步还是将global memory的地址g_idata转化为每个block本地地址。然后,if判断是否该退出,退出的话,就将结果拷贝回global memory。如果不该退出,就进行本地reduction,一般的线程执行in-place(就地)reduction,然后,同步block来保证所有部分和的计算。thread0再次产生一个只有一个block和当前一半数量thread的child grid。
__global__ void gpuRecursiveReduce (int *g_idata, int *g_odata,
unsigned int isize)
{
// set thread ID
unsigned int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = &g_odata[blockIdx.x];
// stop condition
if (isize == 2 && tid == 0)
{
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// nested invocation
int istride = isize >> 1;
if(istride > 1 && tid < istride)
{
// in place reduction
idata[tid] += idata[tid + istride];
}
// sync at block level
__syncthreads();
// nested invocation to generate child grids
if(tid == 0)
{
gpuRecursiveReduce<<<1, istride>>>(idata, odata, istride);
// sync all child grids launched in this block
cudaDeviceSynchronize();
}
// sync at block level again
__syncthreads();
}
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ nvcc -arch=sm_35 -rdc=true nestedReduce.cu -o nestedReduce
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ ./nestedReduce
./nestedReduce starting reduction at device 0: GeForce GT 740M array 1048576 grid 2048 block 512
cpu reduce elapsed 0.002892 sec cpu_sum: 1048576
gpu Neighbored elapsed 0.002178 sec gpu_sum: 1048576 <<>>
gpu nested elapsed 0.733954 sec gpu_sum: 1048576 <<>>
从上面结果看,2048个block被初始化了。每个block执行了8个递归,2048*8=16384个child block被创建,__syncthreads 也被调用了16384次,这都是导致效率很低的原因。
当一个child grid被调用后,他看到的memory是和parent完全一样的,因为child只需要parent的一部分数据,block在每个child grid的启动前的同步操作是不必要的,修改后:
__global__ void gpuRecursiveReduceNosync (int *g_idata, int *g_odata,
unsigned int isize)
{
// set thread ID
unsigned int tid = threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
int *odata = &g_odata[blockIdx.x];
// stop condition
if (isize == 2 && tid == 0)
{
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// nested invoke
int istride = isize >> 1;
if(istride > 1 && tid < istride)
{
idata[tid] += idata[tid + istride];
if(tid == 0)
{
gpuRecursiveReduceNosync<<<1, istride>>>(idata, odata, istride);
}
}
}
实验结果:
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ nvcc -arch=sm_35 -rdc=true nestedReduceNosync.cu -o nestedReduceNosync
hym@hym-ThinkPad-Edge-E440:~/CodeSamples/chapter03$ ./nestedReduceNosync
./nestedReduceNosync starting reduction at device 0: GeForce GT 740M array 1048576 grid 2048 block 512
cpu reduce elapsed 0.002918 sec cpu_sum: 1048576
gpu Neighbored elapsed 0.002182 sec gpu_sum: 1048576 <<>>
gpu nested elapsed 0.733726 sec gpu_sum: 1048576 <<>>
gpu nestedNosyn elapsed 0.030162 sec gpu_sum: 1048576 <<>>
从以上试验结果发现gpu nestedNosyn 提升了很多,但是性能还是比neighbour-paired要慢。接下来在做点改动,主要想法如下图所示,kernel的调用增加了一个参数iDim,这是因为每次递归调用,child block的大小就减半,parent 的blockDim必须传递给child grid,从而使每个thread都能计算正确的global memory偏移地址。注意,所有空闲的thread都被移除了。相较于之前的实现,每次都会有一半的thread空闲下来而被移除,也就释放了一半的计算资源。
__global__ void gpuRecursiveReduce2(int *g_idata, int *g_odata, int iStride,
int const iDim)
{
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * iDim;
// stop condition
if (iStride == 1 && threadIdx.x == 0)
{
g_odata[blockIdx.x] = idata[0] + idata[1];
return;
}
// in place reduction
idata[threadIdx.x] += idata[threadIdx.x + iStride];
// nested invocation to generate child grids
if(threadIdx.x == 0 && blockIdx.x == 0)
{
gpuRecursiveReduce2<<>>(g_idata, g_odata,
iStride / 2, iDim);
}
}
main 函数中调用:
gpuRecursiveReduce2<<>>(d_idata, d_odata, block.x / 2,block.x);
ccit@ccit:~/hym/CodeSamples/chapter03$ ./nestedReduce2
./nestedReduce2 starting reduction at device 0: Tesla K80 array 1048576 grid 2048 block 512
cpu reduce elapsed 0.002539 sec cpu_sum: 1048576
gpu Neighbored elapsed 0.001015 sec gpu_sum: 1048576 <<>>
gpu nested elapsed 0.250117 sec gpu_sum: 1048576 <<>>
gpu nestedNosyn elapsed 0.024537 sec gpu_sum: 1048576 <<>>
gpu nested2 elapsed 0.001025 sec gpu_sum: 1048576 <<>>```
==25190== Profiling application: ./nestedReduce2
==25190== Profiling result:
Time(%) Time Calls (host) Calls (device) Avg Min Max Name
92.61% 11.9872s 1 16384 731.60us 3.3280us 285.05ms gpuRecursiveReduce(int, int, unsigned int)
7.34% 950.18ms 1 16384 57.990us 2.8480us 40.780ms gpuRecursiveReduceNosync(int, int, unsigned int)
0.04% 5.6049ms 4 - 1.4012ms 1.3760ms 1.4362ms [CUDA memcpy HtoD]
0.01% 723.10us 1 8 80.343us 31.839us 143.71us gpuRecursiveReduce2(int, int, int, int)
0.00% 538.30us 1 0 538.30us 538.30us 538.30us reduceNeighbored(int, int, unsigned int)
0.00% 18.271us 4 - 4.5670us 4.1920us 5.2150us [CUDA memcpy DtoH]
分析:gpu nested2 实际上是<<<2048,256>>>,修改后的程序只需要产生8个child,和之前的16384个child比起来,减少了很多资源的开销。但是我在实验过程中发现了一个很奇怪的结果Tesla k80可以正确运行,但是我的gt740m上无法正确运行,计算的结果不正确,我暂时还没有找到错误的原因。