介绍
Low bits压缩再用于CNN推理当属该下的推理优化技术主流。
将本是Float32类型的乘法或乘加计算使用INT8类型来做可一次批量(SIMD指令集)执行更多的计算,从而有效提升CNN推理的计算性能。它也是当下CPU能够在性能与成本上战胜GPU并牢牢占据
深度学习模型推理市场90%以上份额的主要原因所在。
最近Facebook推出并开源了fbgemm,它即主要使用INT8计算来代替本来Float32做的事情,在牺牲小部分模型精度的情况下(做得好可控制在1%以内,亦取决于用户自身对性能与速率之间的取舍),可
达到相对于FP32模型近1~2x的提升。模型权重所占size也是大大降低。
推本溯源,fbgemm里所用的low-bits压缩技术本质上与18年年初Google tensorflow-tflite所用的方法并无二致。而这一方法则在此篇blog要讲的paper中曾一一揭示。
典型的Quantization技术
Quantization技术用于深度学习模型推理优化早已有之,并非此paper先创。
但早先的Quantization技术用于推理多是在取得fp32计算训练好的模型参数权重之后,再对权重进行quantization,然后即使用scale过后的int8(or uint8)权重与op输入feature maps(亦经scale后变
为了low-bits的表示)进行原本由fp32类型进行的乘法或乘加计算,如此执行所用的ops以完成整个模型推理过程。
而这一inference过程本质上与fp32 train时进行的forward的计算有较大区别的,毕竟在使用fp32类型进行forward/backward计算是并无引入任何scale之类的东西。这样train出来的weights经由quantized
inference显然会有较大的精度损失风险。为了避免较大精度损失,成功地在fp32 train时考虑进入scaling的影响,作者们设计了一种与quantization inference相辅相成的带有simulated quantization的
训练机制。在我看来它显然是本篇与之前的quantization方法有最大不同的地方。
下图a为正式部署时的INT8 quantization计算示例;而图b则为使用引入了simulation quantization的op训练时的计算机制;图c则为与fp32相比,此方法在近乎同等精度下所或得的模型性能提升。
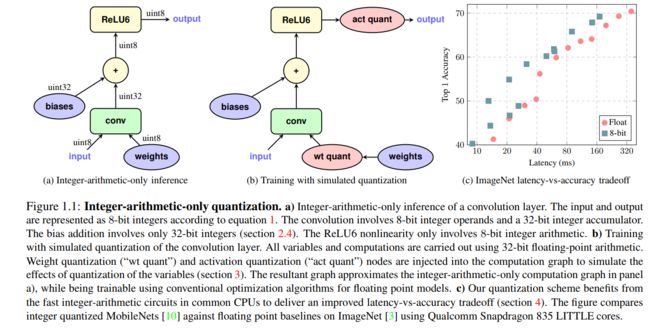
下面我们将分别讲述用于部署时的Quantized inference计算过程及方法和引入了simulated quantization的training的计算机制。
Quantized Inference
数学上的等价low-bits表示
经典CNN中,无论GEMM的矩阵乘法运算还是Convolution的乘加计算都是使用fp32进行的。如若我们要使用INT8类型来几乎无损地模型此以过程(只是INT8与FP32位数表示上的损失我们肯接受,其它则试图避免),
那么首先就要在数学上力图走通。
如下为数学上使用low-bits(int8)来代替FP32的计算过程。
首先,我们想在分别使用low-bits(int8)与FP32表示的模型权重及feature map特征之间建立一个简单的单对单映射,如下公式一所示。
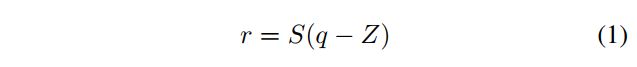
其中r表示fp32表示;q则是low-bit(如int8)表示;S则是自low-bit(int8)到fp32的scale变换,它是个常数,跟具体所变换的tensor相关;Z为零点shift,用于使q的某数值对应于r中的0.0。
由上面公式我们可知,每个fp32类型的tensor可由如下的一个low-bit类型的quantization tensor所表示。

int类型的矩阵乘法计算
下面,我们将看下如何使用int类型来等价表示本由fp32类型完成的矩阵乘法计算。准备好了,大波公式来袭!!!

上述公式2,3,4,5的推理一目了然,我们有了上小节中公式1中表示过的fp32与int类型之间的映射关系后,这些都是顺理成章的事。有个初中数学的基本就差不多明白如何自公式2至公式4,5的了。
在最终的公式4计算中,可以看出除了与M的乘法计算需要使用浮点数计算外,其它已经都可以使用int类型计算来搞定了。那么如何将它也搞成更高效率的int计算呢?于是大招来了,下面的近似变换
还是有点trick的,想搞懂的话可能还是要多读上几遍。
首先来自Googlers们的强大经验(我们自己大致亦可感觉出),M一般会是个介于0-1的浮点小数。于是自然是就可将它表示为如下公式6的形式。

公式6是如何来的呢?如果读者诸君曾在课程中做过十进制与二进制之间表示变换的练习题的话,显然会更容易理解它。如若没有做过,呃,那么好好思索一番吧,你会有顿悟的那一刻的:)。
在公式6中,2-n这一部分计算可简单用int类型的右移指令来搞定。那么其值在0.5-1之间的M0怎么办呢?
我们可以使用一个32位的INT类型来表示此一值在0.5-1之间的M0。试想将M0乘以232则是一个至少为231的整数,如此它就至少可拥有31位的表示精度,因此使用一个INT32类型来表示M0还是
很能保证精度的。(当然理解此一近似同样要求读者对类型表示等基础计算机知识有些了解。。)
int类型矩阵乘法中零点的高效表示
由上节中的讨论,我们已经可以完全使用INT类型计算来完成矩阵乘法了,它在上节中的最终形式为公式4。
而在矩阵乘法中如果一直按照公式4那样,我们要完成2N3减法,同时要使用INT16来表示每对INT8的乘积。
而如果对它进行如下一系列合理、等价的数学变形,我们可得到公式7,并发现其中真正computing intensive的即是公式9表示的INT8乘法计算。

典型Fusion layer的计算实现
一般Conv或GEMM计算后我们会有bias加或ReLu等activation函数计算。
在经典的fp32前向推理优化中,我们都会考虑将这些memory-intensive的计算与前面compute-intensive的计算fusion起来一块进行,以减少对memory-bandwidth的需求。
在int类型计算中显然也要考虑进去此种fusion layer的影响。
首先,对于bias加,我们可以使用如下的公式10与公式11即使用INT32表示int8乘积之后的加和,然后同时使用INT32来表示bias。在与float32 bias计算映射时,它使用的sclae为
weights tensor scale (S1) 与input feature map tensor scale(S2)之间的乘积。
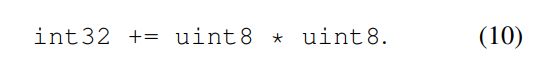
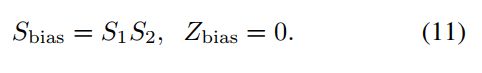
对于像ReLu这样的Activation,我们可考虑直接在INT输出的feature map上针对某一INT threshold值进行。在此不细表,不是很难,详情可见论文。
引入了simulated quantization的training
在training的时候引入了scale的机制,即将原来fp32表示的权重与feature map同样scale到与INT同样的range里面(进行一种近似的前向forward计算)。
如下为training时前向计算的scaling机制。

其它本质上在Quantization inference时,我们也是如此获得S与Z的,只是在这里一切皆是用FP32来表示。
即拿到一tensor(weight可feature map),先将其参数限定在某一固有范围内(a,b),即quantization range,对weights而言,a为min(W),b为max(w),对input而言,因为
变动范围较大,所以使用一种smooth average 的机制来计算相应的a与b;然后使用quantization level来对其进行scale factor计算。
一般在INT中我们使用INT8的话quantization level就是256。
在最终的q计算中貌似是没干啥,其实我们在浮点运算中,这样除了一下,进行了data rounding to integer,然后再乘回去一切其它已经不同了,那样特别小的位数显然已经被清了零。
ok,到了可以进一步总结的时候了。下面的算法过程基本理清了此一quantization机制的整体操作步骤。

熟悉tensorflow API的可以看下如下用于构建traing graph及inference graph的过程表示。

本来还有点BN fusion的东西,可以一说,可老婆在喊饿唉,所以只能结束掉先闪人了。。读者君有兴趣自己去翻吧,如果真有兴趣要使用此技术的话,毕竟都读到这了。
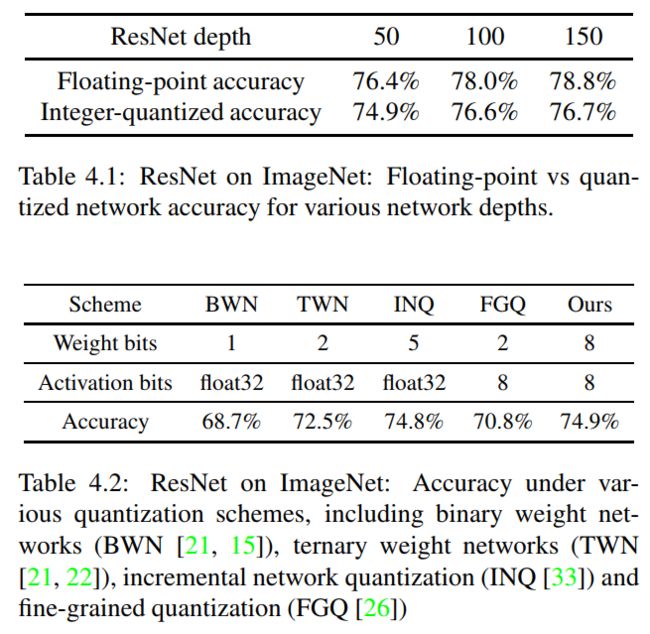
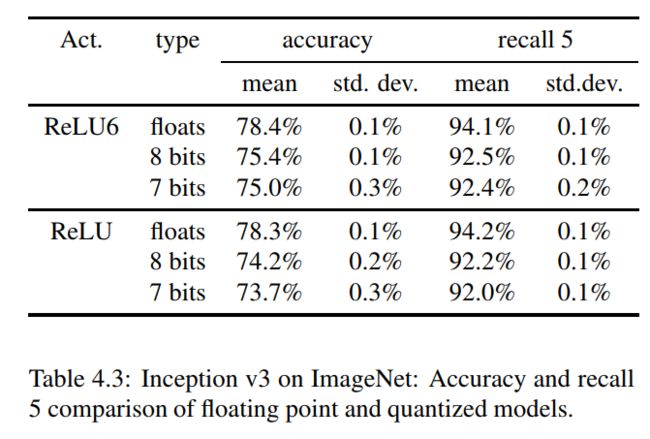
实验结果
参考文献
- Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference, Benoit-Jacob, 2017
- https://code.fb.com/ml-applications/fbgemm/