参数说明:
a) 引用名称:下一个请求要引用的参数名称,如填写token,则可用${token}引用它。
b) 正则表达式:
():括起来的部分就是要提取的
.:匹配任何字符串
+:一次或多次
?:在找到第一个匹配项后停止
c) 模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给token。如:$1$表示解析到的第1个值
d) 匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
缺省值:如果参数没有取得到值,那默认给一个值让它取。
四、插件管理
Jmeter插件管理plugins-manager.jar 它管理插件包括 jmeter-plugins.org 上面常用的插件和各种第三方插件甚至核心JMeter插件
下载地址:https://jmeter-plugins.org/downloads/all/
安装:下载后文件为plugins-manager.jar格式,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter

jmeter插件
【Jmeter】 性能监控(插件)
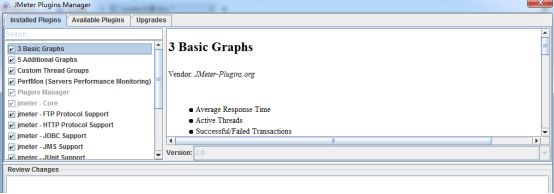
1、3 Basic Graphs ---基本图表
包含:
⑴ jp@gc - Transactions per Second
每秒处理事物数即TPS(x轴是测试执行持续时间,y轴是当前时刻事务数)
⑵ jp@gc - Response Times Over Time
事务响应时间(响应时间过程图,x轴是测试执行持续时间,y轴是事务响应时间)
⑶ jp@gc - Active Threads Over Time
随时间变化的活动线程
2、5 Additional Graphs ---附加图表
包含:
⑴ jp@gc - Bytes Throughput Over Time
不同时间吞吐量展示(字节Bytes)
聚合报告里,Throughput是按请求个数来展示的,比如说1.9/sec,就是每秒发送1.9个请求;而这里的展示是按字节
Bytes来展示的图表,表示每秒发送多少字节
⑵jp@gc - Connect Times Over Time
随着时间推移的连接时间
⑶ jp@gc - Hits per Second
每秒点击量
每秒web服务器接收到的请求数
⑷ jp@gc - Response Codes per Second
测试期间返回的每秒响应代码
⑸ jp@gc - Response Latencies Over Time
记录客户端发送请求完成后,服务器端返回请求之前这段时间
3、 PerfMon(Servers Performance Monitoring )---服务器性能监控
(安装后在Jmeter-监听器中显示为"jp@gc - PerfMon Metrics Collector";可添加CPU、Memory、TCP、Disks I/O、network I/O)
(注意:jmeter只能监控tomcat的主机;需要在服务器上启动StartAgent,即把插件解压到服务器上,运行StartAgent。)
4、 Custom Threads Groups --- 自定义线程组
包含:
(1).jp@gc - Stepping Thread Group(在Threads(users)) -步进线程组(以下类似LR中的场景设置)逐步加压
a)This group will star 100 threads -本次设置线程组启动的线程总数为 *个
b) First,wait for N seconds -启动第一个线程之前,需要等待N秒。设置为0s说明不等待,直接启线程
c) Then start N thread -设置最开始时启动 N个线程。可以默认为0
d) Next,add 10 threads every 30 seconds,using ramp-up 5 seconds -每隔30秒,启动10个线程,10个线程在5秒内启动完成
e)Then hold load for 30 seconds -启动的线程总数达到最大值之后,再持续运行30秒
f) Finally,stop 10 threads every 1 seconds -最后停止线程,每1秒停止10个线程;
(2).jp@gc - Ultimate Thread Group(在Threads(users)) -终极线程组
该插件跟Stepping Thread Group线程组有些类似,不过这个是多个线程组设置的结合。执行的时候,每个线程组是同时按照自己的规则开始执行的,每一时刻,得到的结果都是两个线程组的叠加
a) Start Threads Count:当前行启动的线程总数
b) Initial Delay/sec:延时启动当前行的线程,单位秒
c) Startup Time/sec:启动当前行所有线程达峰值所需时间,单位秒
d) Hold Load For/sec:当前行线程达到峰值后的稳定加载时间,单位秒
e) Shutdown Time:停止当前行所有线程所需时间,单位秒
(3).bzm - Arrivals Thread Group(在Threads(users)) -到达线程组
a)Target Rate(arrivals/sec):每分钟到达的数量
b) Ramp Up Time:加速时间
c) Ramp-Up Steps Count:加速步骤计数
d) Hold Target Rate Time:保持目标速率时间
e) Time Unit:时间单位(分钟或者秒)
f) Thread Iterations Limit:线程迭代次数限制(循环次数)
g)Log Threads Status into File:将线程状态记录到文件中(将线程启动和线程停止事件保存为日志文件)
h) Concurrency Limit:虚拟用户的最大数量
(4). bzm - Concurrency Thread Group(在Threads(users)) -并发线程组
a)Target Concurrency:目标并发(线程数)
b) Ramp Up Time:加速时间
c) Ramp-Up Steps Count:加速步骤计数
d)Hold Target Rate Time:保持目标速率时间
e) Time Unit:时间单位(分钟或者秒)
f) Thread Iterations Limit:线程迭代次数限制(循环次数)
g) Log Threads Status into File:将线程状态记录到文件中(将 线程启动和线程停止事件保存为日志文件)
场景举例:
100个线程、3分钟的加速时间、5个加速步骤、持有目标速率6分钟;
解释场景举例:
3分钟除以5步,每步0.6分钟;100个用户除以5步,每步20个用户;每0.6分钟将添加20个用户,直到达到100个用户;达到100个线程后,所有这些线程将继续运行,并一起打到服务器6分钟;
(5). bzm - Free-Form Arrivals Thread Group
(在Threads(users)) -自由形式到达线程组与 Arrivals Thread Group.相同,它只是提供了自由格式的时间表功能)
5、监控内存及CPU等(jconsole)
方法:比较好的监控内存CPU等的小工具
如果已配置Jmeter则不需要配置其他即可打开此小工具;开始——>运行——>输入cmd——> 进入命令界面直接输入:jconsole ——>回车,即可弹出java监视和管理控制台
选择本地进程,并点击一下sun.tools.jconsole.JConsole,就可以查看本地内存、CPU的使用情况(如果该项不能连接,则选择"ApachJMeter.jar",多链接几次可连接成功)
选择远程进程,需要输入被测服务器的IP、端口->输入用户名、密码点击连接即可查看服务器内存、CPU等使用情况
6、生成html测试报告
jmeter -n -t
命令参数解析:
-n :以非GUI形式运行Jmeter
-t :source.jmx 脚本路径
-l :运行结果保存路径,此文件必须不存在
-e :在脚本运行结束后生成html报告
-o :用于存放html报告的目录
例如:D:\BaiduNetdiskDownload\apache-jmeter-4.0\bin
Jmeter -n -t D:\Jmeter-script\招聘登录+查询.jmx -l D:\JmeterTest\resport\result.csv -e -0 D:\JmeterTest\resport\html
五、Jmeter之参数化
1. 前置处理器-用户参数



1. 配置元件-CSV数据文件设置

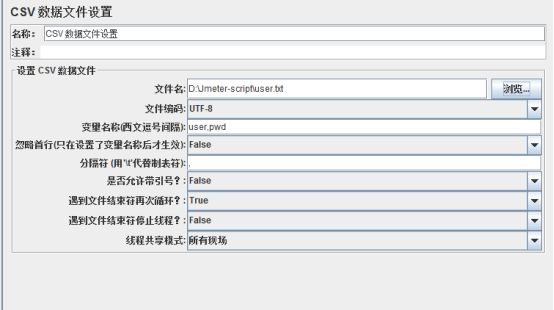
文件名:保存信息的文件目录,可以相对或者绝对路径
文件编码:默认为ANSI
变量名称:给csv文件中各列起个名字(有多列时,用英文逗号隔开列名)便于后面引用
分隔符:与csv文件的分隔符保持一致。如文件中使用的是逗号分隔,则填写逗号;如使用的是TAB,则填写\t
遇到文件结束符再次循环:到了文件尾是否循环,True—继续从文件第一行开始读取,False—不再循环
晕倒文件结束符停止线程:到了文件尾是否停止线程,True—停止,False—不停止,注:当Recycle on EOF设置为True时,此项设置无效

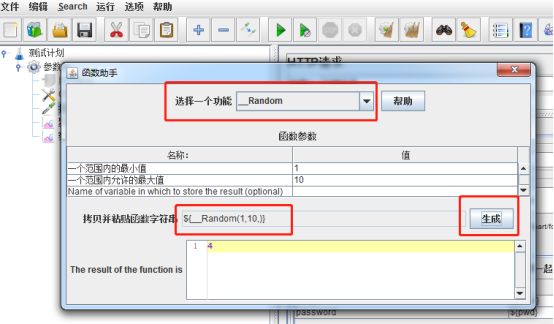
1随机参数化,选项-函数助手 —Random
六、Jmeter之检查点

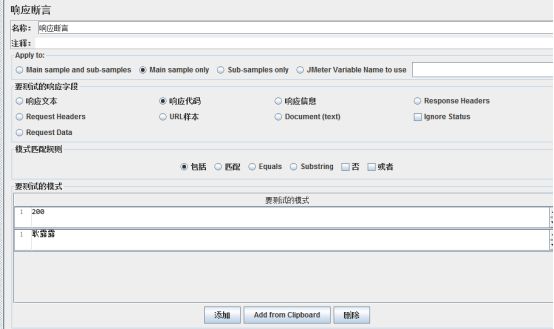
要测试的响应字段: 响应文本、Document(text)、URL样本、响应信息、Response Headers、Lgnore Staus 等选项。虽然接口返回的是HTML页面,但对于JMeter来说返回数据为文本,所以,这里可以勾选“响应文本”。
模式匹配规则: 包括、 匹配、 Equals、 Substring。这里只需要验证返回数据中是否包含主要的关键字,所 以, 这里勾选“包括” 。
要测试的模式: 断言的数据。 点击“添加” 按钮, 输入要断言的数据
七、Jmeter之集合点
简单来理解一下,虽然我们的“性能测试”理解为“多用户并发测试”,但真正的并发是不存在的,为了更真实的实现并发的操作,我们可以在需要压力的地方设置集合点

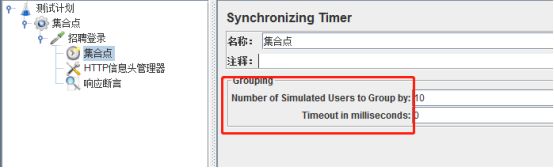
Number of Simulated Users to Group by: 每次释放的线程数量。如果设置为0,等同于线程组中设置的线程数量。
Timeout in milliseconds: 如果设置为0,Timer将会等待线程数达到了”Number of Simultaneous Users to Group”中设置的值才释放。如果大于0,那么超过Timeout in milliseconds中设置的最大等待时间(毫秒为单位)后还没达到”Number of Simultaneous Users to Group”中设置的值,Timer将不再等待,释放已到达的线程。
注意:
Synchronizing timer 仅作用于同一个JVM中的线程,所以,如果使用并发测试,确保”Number of Simultaneous Users to Group by”中设置的值不大于它所在线程组包含的用户数
如果设置Timeout in milliseconds为0且线程数量无法达到"Number of Simultaneous Users toGroup by"中设置的值,那么Test将无限等待,除非手动终止
Synchronizing Timer是在每个sampler(采样器)之前执行的,而不是之后,不管这个定时器的位置放在sampler之后,还是之前
作用域:当执行一个sampler之前时,和sampler处于相同作用域的定时器都会被执行
八、Jmeter之关联
关联是一种动态行为,用以后续的请求(比如HTTP请求)从之前的请求(比如JDBC Request)的响应数据(服务器返回的数据)中直接使用指定的数据
比如:
(1)、用户登录后,session信息都不同,有些操作要使用session,就需要将这个动态的信息保存下来。
(2)、第二个请求提交的参数要从第一个请求的返回数据中获取(用户登录token)
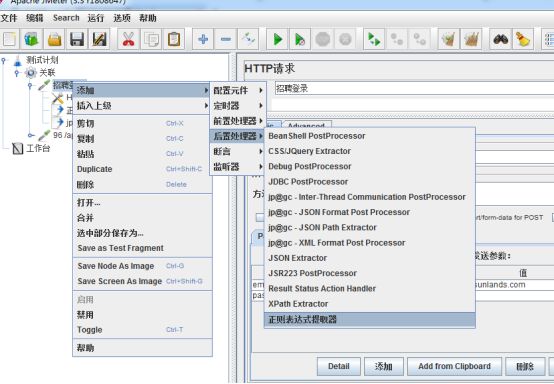
Jmeter中,关联是通过之前请求的后置处理器实现的,具体有XPath Extractor和正则表达式提取器两种方式:
如果需要提取的文本是页面上某个元素的属性值,建议使用XPath;
如果需要提取的文本在页面上的位置不固定,或者不是元素的属性值,建议使用正则
对于大部分请求返回的结果,都是json格式,还可以使用JSON Extractor插件提取数据
常用场景:
1. HTTP请求-》HTTP请求

参数说明:
a) 引用名称:下一个请求要引用的参数名称,如填写token,则可用${token}引用它。
b)正则表达式:
():括起来的部分就是要提取的
.:匹配任何字符串
+:一次或多次
?:在找到第一个匹配项后停止
c) 模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给token。如:$1$表示解析到的第1个值
d) 匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
缺省值:如果参数没有取得到值,那默认给一个值让它取。

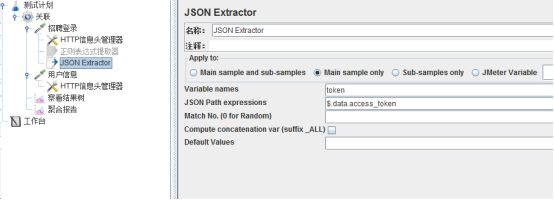
Variable names : 下一个请求要引用的参数名称 JSONPath Expression:JSON表达式 Match Numbers:匹配哪个,可为空即默认第一个 Default Value:未取到值的时候默认值
1.JDBC Request -》HTTP请求
1) 下载mysql jar包
2) 为Jmeter添加jar文件
下载后解压.zip文件,把mysql-connector-java-x.x.x-bin.jar放到Jmeter安装目录下的lib目录下

或者在测试计划中添加驱动包
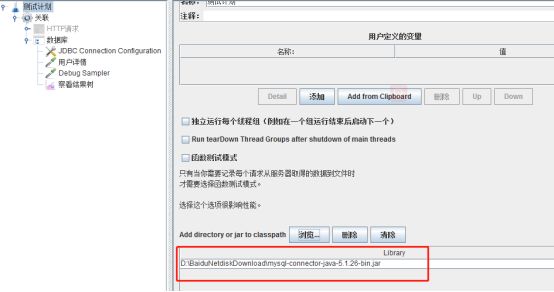
1) 启动Jmeter
添加JDBC Connection Configuration
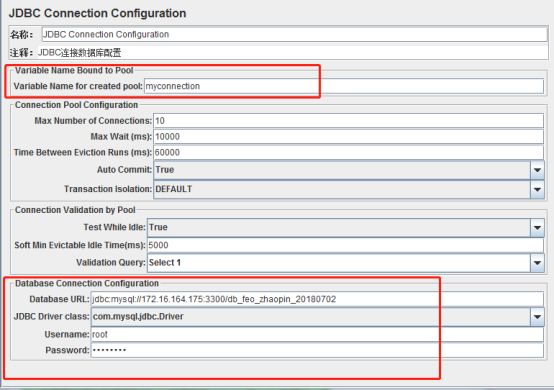
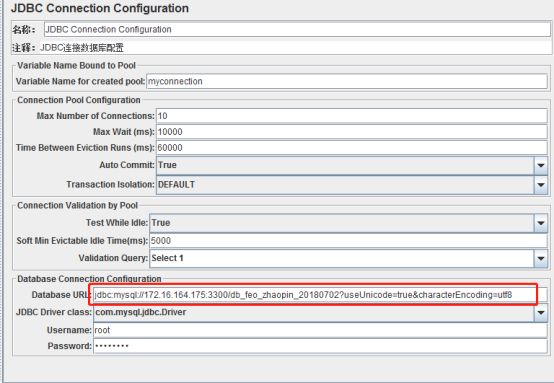
重要参数说明:
a) Variable Name:数据库连接池的名称
b) Database URL:数据库url,jdbc:mysql://主机ip或者机器名称:mysql监听的端口号/数据库名称, 如招聘数据库:jdbc:mysql://172.16.164.175:3300/db_feo_zhaopin_20180702
c) JDBC Driver class:数据库驱动
d) username:数据库登陆的用户名
e) passwrod:数据库登陆的密码
不同数据库具体的填写方式,可以参考下面的表格:
1) 设置好JDBC连接配置后,添加JDBC请求
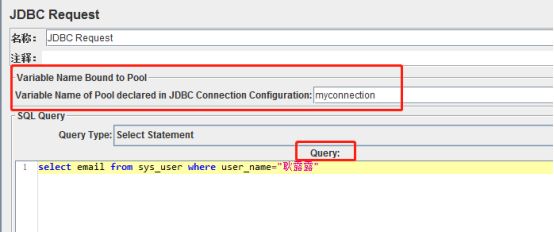
a) Variable Name Bound to Pool :数据库连接池的名字,需要与JDBC Connection Configuration的Variable Name Bound Pool名字保持一致
b) Query:填写的sql语句未尾不要加“;”
c) Parameter valus:数据的参数值
d) Parameter types:数据的参数类型,可参考:Javadoc for java.sql.Types
e) Variable names:保存sql语句返回结果的变量名
f) Result variable name:创建一个对象变量,保存所有返回的结果
a) Query timeout:查询超时时间
b) Handle result set:定义如何处理由callable statements语句返回的结果
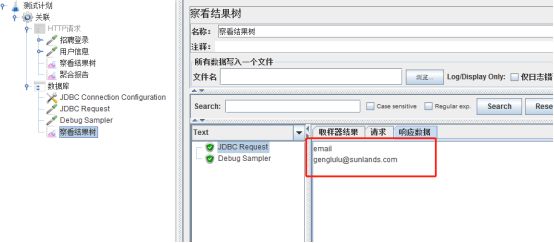
注意:SQL语句输入有中文时,可能查不到数据,需要指定字符的编码、解码格式

jdbc:mysql://172.16.164.175:3300/db_feo_zhaopin_20180702?useUnicode=true&characterEncoding=utf8
作用:
a) 存数据时:
数据库在存放项目数据的时候会先用UTF-8格式将数据解码成字节码,然后再将解码后的字节码重新使用GBK编码存放到数据库中。
b)取数据时:
在从数据库中取数据的时候,数据库会先将数据库中的数据按GBK格式解码成字节码,然后再将解码后的字节码重新按UTF-8格式编码数据,最后再将数据返回给客户端。
1) 将JDBC Request查询结果作为下一个接口参数


注意:当使用jdbc request的结果作为参数时,需要写成${email_1},1代表查出来数据第一行
九、分布式
在使用Jmeter进行性能测试时,如果并发数比较大(比如项目需要支持1000并发),单台电脑的配置(CPU和内存)可能无法支持,这时可以使用Jmeter提供的分布式测试的功能
一、Jmeter分布式执行原理:
1、Jmeter分布式测试时,选择其中一台作为调度机(master),其它机器做为执行机(slave)。
2、执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI,应该是通过命令行模式执行的。
3、执行完成后,slave会把结果回传给master,master会收集所有slave的信息并汇总。
参考:https://www.cnblogs.com/puresoul/p/4844539.html