本人新手,所以采取移动端登录,
首先打开m.weibo.com
接下来输入账户密码登录,进行抓包,这里可以看到登录的url是https://passport.weibo.cn/sso/login
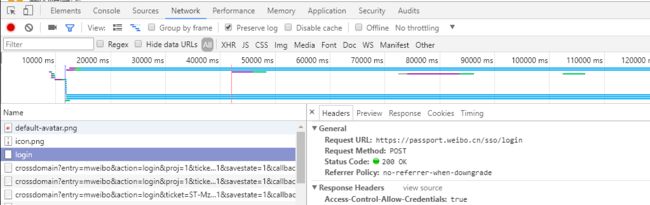
image.png
然后看参数内容,可以看到有username,password
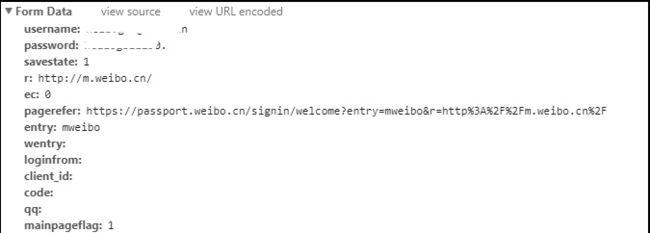
image.png
接下来开始码
param = {
'username': 'username',
'password': 'password',
'savestate': 1,
'r': 'http://m.weibo.cn/'
}
url = 'https://passport.weibo.cn/sso/login'
url_list = [('https://m.weibo.cn/api/container/getSecond?containerid=1005053295408160_'
'-_FOLLOWERS&page={}'.format(index)) for index in range(1, 9, 1)]
伪装成浏览器,设置请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
设置cookie
cookie = {
'SUB': '_2A257ojDeRhGeVM4lcV8CbNzTyIHXVUc8ZrrDV6PbkdBeLRfdkW0BL90qwu2eRETLthwusaALWYW0Mg..',
'Path': '\/',
'Domain': '.weibo.cn',
'Expires': 'Fri, 10 Aug 2018 02:52:35 GMT',
'_T_WM': '45539fc43e99e886ce17e795d0b88',
'SCF': 'Aij4zi-OmgzuJPRpOQqpZ-ASMB3LshtNNn-DL4wO0DwTnXeihX4F2uo4youXrual-w4UuBxGTR8UKP4Qq9SLA.',
'SUHB': '0P1M9JSHSW7ZoW',
'SSOLoginState': '15023355'
}
# 设置一个会话
s = requests.Session()
# 发送post请求
s.post(url, param, headers)
登录成功后我们看一下我的关注列表~

image.png
可以看到关注列表请求的url是文章上面的url2
for url_concern in url_list:
res = requests.get(url=url_concern, cookies=cookie, headers=headers)
可以看到请求结果返回的json对象

image.png
我们只要取到结果中的cards对象就可以了,再对结果进行一下遍历
users = res.json()['cards']
for user in users:
name = user.get('user').get('screen_name')
print(name)
得到以下信息,就是我们的关注列表啦

image.png
如果还需要其他信息,看一下json中返回了哪些,然后自己处理就可以啦
最后贴上完整代码
#!/usr/bin/env python3
# -*-coding:utf-8-*-
import requests
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
cookie = {
'SUB': '_2A250j7ojDeRhGeVM4lcV8CbNzTyIHXVUc8ZrrDV6PUJbkdBeLRfdkW0BL90qwu2eRETLthwusaALWYW0M..',
'Path': '\/',
'Domain': '.weibo.cn',
'Expires': 'Fri, 10 Aug 2018 02:52:35 GMT',
'_T_WM': '455639fc43e99e886ce1d07e795d0b88',
'SCF': 'Aij4zi-OmgzuJPRpOQ3dqpZ-ASMB3LshtNNn-DL4wO0DwTnXeihX4F2uo4youXrual-w4UuBxGTR8UKP4Qq9SL.',
'SUHB': '0P1M9JSHSW7Zo',
'SSOLoginState': '150233355'
}
url = 'https://passport.weibo.cn/sso/login'
url_list = [('https://m.weibo.cn/api/container/getSecond?containerid=1005053295408160_'
'-_FOLLOWERS&page={}'.format(index)) for index in range(1, 9, 1)]
param = {
'username': 'your username',
'password': 'your password',
'savestate': 1,
'r': 'http://m.weibo.cn/'
}
s = requests.Session()
s.post(url, param, headers)
for url_concern in url_list:
res = requests.get(url=url_concern, cookies=cookie, headers=headers)
users = res.json()['cards']
for user in users:
name = user.get('user').get('screen_name')
print(name)