1. 模块开发之数据仓库设计
a. 维度建模的基本概念(如何来构建数仓中的表)
维度建模是专门应用于分析型数据库,数据仓库,数据集市建模的方法。(不能用于关系型数据库)。
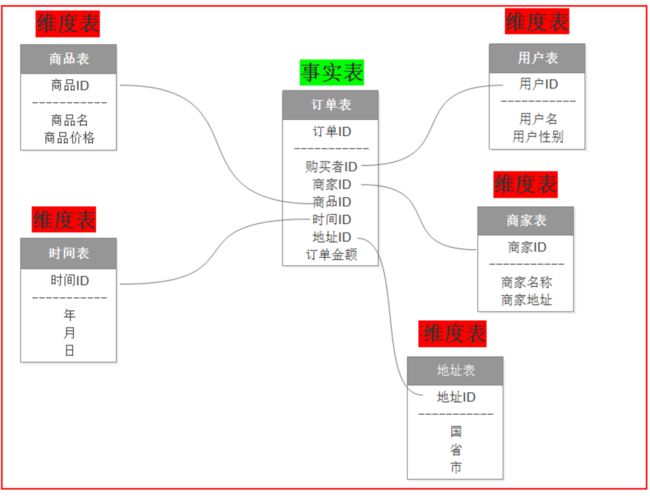
- 事实表:一般和分析的主题有关
需求:分析最近一年的订单销售情况
主题:订单
事实表:分析主题的度量(订单详细数据)
特点:一堆主键的聚集
- 维度表:描述分析问题的角度
包含单一主键的列
b. 维度建模的三种模式
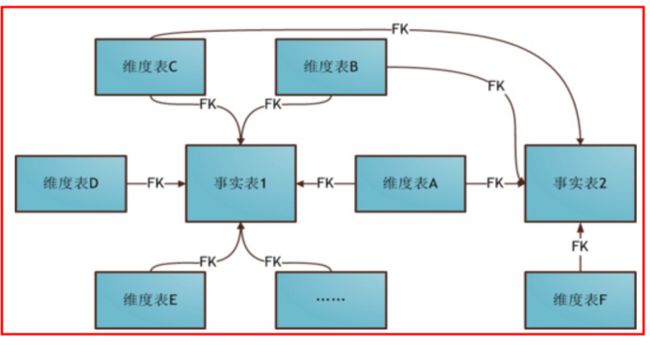
- 星型模式:一个事实表,多个维度表,维度表之间是没有关联的
- 雪花模式:一个事实表,多个维度表,维度表之间有关联的(维护成本比较高,避免设计成这种模式)

- 星座模式:多个事实表,多个维度表,维度表在某种情况下可以共用,维度表关联多个事实表。(中后期常见的模型)
2. 数据仓库设计
hive的三层架构,ods(源数据),dw(数据仓库层),DA(数据应用仓库),三层都是逻辑分层,我们可以用不同的表名,数据库名来识别。
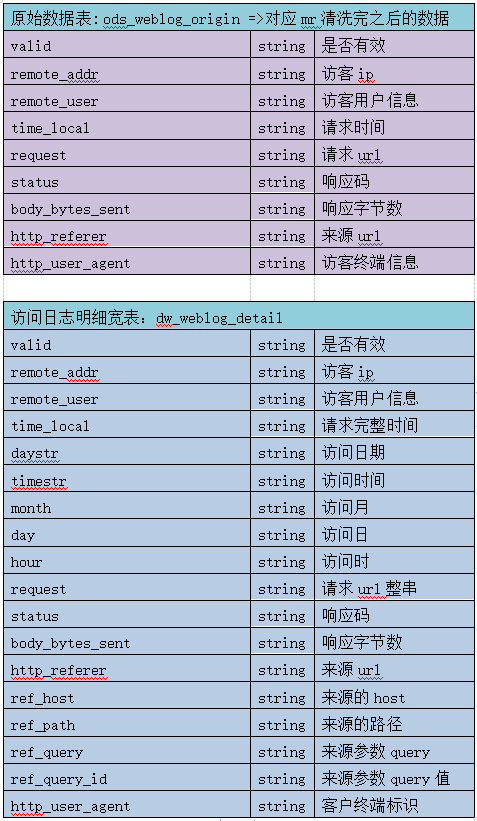
事实表:
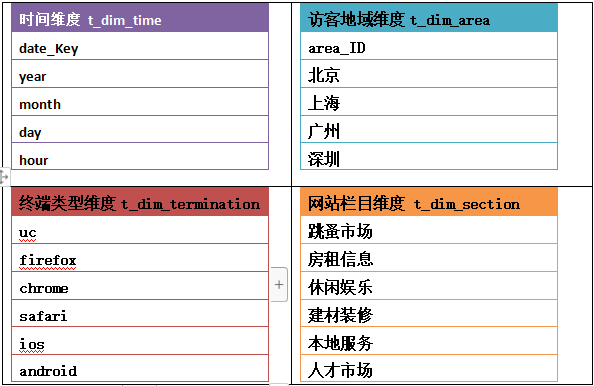
维度表:
a. 创建数据库
create database itheima_weblog;
b. 创建原始表数据和加载数据
create table ods_weblog_origin( valid string, remote_addr string, remote_user string, time_local string, request string, status string, body_bytes_sent string, http_referer string, http_user_agent string) partitioned by (datestr string) row format delimited fields terminated by '\001'; drop table if exists ods_click_pageviews; create table ods_click_pageviews( session string, remote_addr string, remote_user string, time_local string, request string, visit_step string, page_staylong string, http_referer string, http_user_agent string, body_bytes_sent string, status string) partitioned by (datestr string) row format delimited fields terminated by '\001'; drop table if exist ods_click_stream_visit; create table ods_click_stream_visit( session string, remote_addr string, inTime string, outTime string, inPage string, outPage string, referal string, pageVisits int) partitioned by (datestr string) row format delimited fields terminated by '\001'; load data inpath '/weblog/preprocessed/' overwrite into table ods_weblog_origin partition(datestr='20181101');--数据导入 show partitions ods_weblog_origin;---查看分区 select count(*) from ods_weblog_origin; --统计导入的数据总数 点击流模型的两张表数据导入操作同上。
d. 宽表的引入
- 需求:统计网站每小时的访问的次数
- 原有时间数据:2018-11-01 06:49:18 不满足需求,无法分组
- 解决方案:substring(字段,start,nums)
- 弊端:会对每一行数据都要进行截取
- 原因:在一个字段中糅杂了太多字段的组合,导致分析的时候,无法处理
- 如何实现的这个宽表
- 窄表:ods_web_origin
- 宽表:dw_weblog_detail
- 时间需要拓宽
- 来源字段需要拓宽http——referer
- 构建宽表
create table dw_weblog_detail( valid string, --有效标识 remote_addr string, --来源IP remote_user string, --用户标识 time_local string, --访问完整时间 daystr string, --访问日期 timestr string, --访问时间 month string, --访问月 day string, --访问日 hour string, --访问时 request string, --请求的url status string, --响应码 body_bytes_sent string, --传输字节数 http_referer string, --来源url ref_host string, --来源的host ref_path string, --来源的路径 ref_query string, --来源参数query ref_query_id string, --来源参数query的值 http_user_agent string --客户终端标识 ) partitioned by(datestr string);
- 导入数据
insert into table dw_weblog_detail partition(datestr='20181101') select c.valid,c.remote_addr,c.remote_user,c.time_local, substring(c.time_local,0,10) as daystr, substring(c.time_local,12) as tmstr, substring(c.time_local,6,2) as month, substring(c.time_local,9,2) as day, substring(c.time_local,12,2) as hour, c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent from (SELECT a.valid,a.remote_addr,a.remote_user,a.time_local, a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as ref_host, ref_path, ref_query, ref_query_id) c; show partitions dw_weblog_detail;
3. 流量分析常见分类
a. 基础性指标
- PV(PageView)浏览次数:每打开一个page就记录一次pv。用户多次打开同一页面pv累计计数
- UV(Visit):访问网站不重复用户数,一般以cookie为依据,这个项目我们就用ip来作为依据。
- VV访问次数:一天内不同的session有多少个。
- ip:访问网站不重复ip数
b. 复合级指标
- 平均访问频度:平均每一个独立的访客一天内访问网站的次数。(每一个访客,一天内产生了多少个session)平均访问频度=访问次数(VV)/独立访客数(UV)
- 人均浏览页数(平均访问深度):平均每个独立访客产生的浏览次数。人均浏览页数=浏览次数(PV)/独立访客数(UV)
- 平均访问的时长:平均每次访问(会话)在网站上停留的时间(每一个用户一次会话的停留时间,求平均停留时间)平均访问时长=访问总时长/访问次数(VV)
- 跳出率:一天之内,用户只访问了一个页面就跳出了,和我们总的访问网站页面的次数,求百分比。
4. 如何写SQL:大数据离线分析的执行流程
- 分析业务需求
- 明确数据在哪个表中:表中有数据,表中没有数据(嵌套子查询)
- 明确以哪个字段进行分组(以哪个维度来分析,就用哪个字段分组)
- 明确度量值
多维分析:将多个维度组合在一起,计算出你的某种度量值
常见度量值:count max min sum avg topn
需求:分析每个小时网站的访问次数
- 明确表:dw_weblog_detail
select day,hour,count(*) from dw_weblog_detail where datestr="20181101" group by day,hour;
5. 基础性指标
a. 统计网站某一天的pv量
select count(*) from dw_weblog_detail where datestr="20181101";
b. 统计网站某一天的UV量
select count(distinct remote_addr) from dw_weblog_detail where datestr="20181101";
c. 统计网站某一天的VV量
select count(*) from ods_click_stream_visit where datestr="20181101" ;
d. 统计网站某一天的ip量
select count(distinct remote_addr) from dw_weblog_detail where datestr="20181101" ;
6. 复合型指标
a. 人均浏览页数(平均访问深度) : 今日所有来访者平均请求浏览的页面数
select pv/uv from dw_webflow_basic_info where datestr="20181101";
b. 平均访问频度 : 一天之内人均页面浏览数(产生的session个数)
select count(session)/ count(distinct remote_addr) from ods_click_stream_visit where datestr ="20181101";
c. 平均访问时长 : 平均每次会话停留的时间总会话时长 / vv
select count(page_staylong)/count(distinct session) from ods_click_pageviews where datestr="20181101";
d. 页面跳出率:求 /hadoop-mahout-roadmap/ 页面的跳出率 : 用户在一次会话中只访问一个页面的次数占总的会话访问次数的百分比求出只访问一个页面的数量 / 总访问的数量 * 100
select (t1.overpage /t2.totalpage)* 100 from ( select count(*) overpage from ods_click_stream_visit where datestr="20181101" and inpage = "/hadoop-mahout-roadmap/" and pagevisits = 1 ) t1 join ( select count(*) totalpage from ods_click_stream_visit where datestr="20181101" and inpage = "/hadoop-mahout-roadmap/" ) t2;
7. 多维度指标
a. 计算某一天的各小时 pvs的信息:从时间的维度
select hour count(*) from dw_weblog_detail where datestr="20181101" group by hour;
b. 利用和维表join的方式计算每天的pv -- 和维度表组合使用
select t1.year,d1.month,d1.day,count(*) pvs from dw_weblog_detail d1 join(select distinct year,month,day from t_dim_time) t1 on d1.day=t1.day and d1.month=t1.month group by d1.day ,d1.month,t1.year;
c. 统计每小时各来访url产生的pv量,并按照时间正序和pv量倒序排列 --- 维度 时间 来源
select hour ,count(*) pvs ,http_referer from dw_weblog_detail where http_referer !="\"-\"" group by hour,http_referer order by hour,pvs desc limit 10;
d. 统计每小时各来访host的产生的pv数并排序,并按照时间正序和pv量倒序排列
select hour,count(*) pvs,ref_host from dw_weblog_detail where ref_host is not null group by hour,ref_host order by hour,pvs desc limit 10;