国产阿里OCEANBAS勇夺TPC-C冠军,200行代码解读它的速度源头
我国高科技基础平台又有重大突破,继阿里和腾讯以及众多国内老牌嵌入式厂商相继宣传开源lot操作系统之后(详见国产开源lot操作系统大阅兵)今天据权威机构国际事务处理性能委员会(Transaction Processing Performance Council)官网披露,由阿里自主研发的关系数据库OceanBase,在TPC-C基准测试中,打破了由美国公司Oracle(甲骨文)保持了9年之久的世界记录,成为首个登顶该榜单的中国数据库产品。
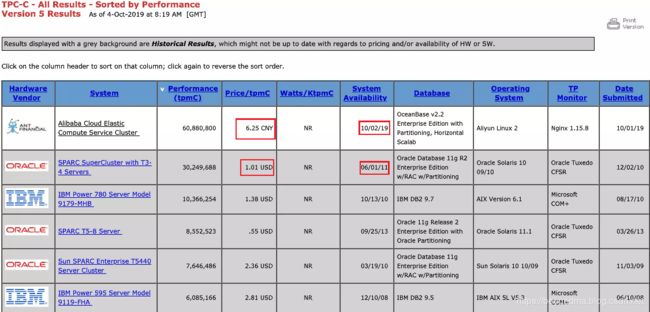
不过经笔者刚刚多次尝试,目前TPC的官网(www.tpc.org)并无法在国内访问,所以全部的信息只能出自这个截图,我们可以看到如下两个信息,一是这个排行榜是以tpmC为基准进行排名的,这里解释一下 tpmC其实是TPC-C三标准的一种度量方式,tpmC中的tpm是transactions per minute的简写即每分钟的交易量,C代表C基准程序。它的定义是每分钟内系统处理的新订单个数。在这方面阿里的OCEANBASE的确是遥遥领先。
TPC-C还经常以系统性能价格比的方式体现,单位是$/tpmC,即以系统的总价格(单位是美元)/tpmC数值得出。这个笔者也已经在上图中标红,可见这个参数按现行汇率来说阿里的优势不明显。而且考虑到甲骨文的测试提交时间是2011年,而阿里的测试时间则是今年的10月2日。所以由于笔者也没拿到测试报告的原文,所以甲骨文是否还是以11年的硬件价格来做为分母计算性价比指标也尚不得而知。
因而综上所述阿里在性能指标上的确是做到了遥遥领先,但是可能在硬件价格以及测试时间的方面占了一些先机。
OCEANBASE哪些方面对了
根据OCEANBASE的官网(https://oceanbase.alipay.com/product/oceanbase)介绍的其总体物理架构如下:
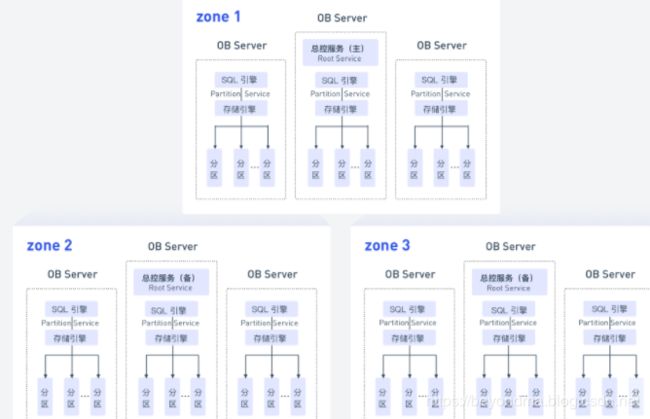
根据其官网的信息,其在金融行业的应用案例为南京银行,因此我第一时间翻了一下南京银行的朋友的票圈:)了解了一下相关信息,目前南京分行在OCEANBASE上线的系统以互联网应用为主,而且根据其分享OCEANBASE在Github对自己的0.4版本进行了开源(https://github.com/alibaba/oceanbase),目前虽然版本有更新,但是其基础设计没有根本改变,根据Github上的资源显示,其数据及控制流程总体如下:

OceanBase将表的数据动态切分为tablet,tablet的数据分为动态和静态两部分。静态的数据存放在chunkserver上,所有对数据的修改都存储在updateserver中。updateserver的修改定期同步到chunkserver,chunkserver将updateserver的更新和本地的静态数据合并,生成合并后的新数据。
tablet的信息由rootserver维护,客户端在初始化时会请求rootserver,获取updateserver的地址信息。客户端的更新请求(包括新增,修改和删除)都直接访问updateserver。查询请求时客户端根据相应的rowkey向rootserver查询其对应的tablet信息,rootserver返回相应的mergeserver地址,客户端根据返回的信息请求相应的mergeserver获取数据。
Mergeserver收到请求时,根据rowkey从rootserver获取相应的tablet信息,该信息中包括负责该tablet的chunkserver列表,mergeserver请求相应的chunkserver,获取静态数据(如果有的话),然后根据返回的数据,请求updateserver获取相应的更新数据,将更新数据和静态的数据合并,将合并后的结果返回给客户端。
为了提高读取的性能,chunkserver对部分数据结构进行了缓存。一个SSTable由多个block组成,为了加快定位需要请求的数据位于SSTable的哪个block中,chunkserver包含一个block index的功能,block index由该block负责的数据的最后一个key和该block在SSTable文件中的位置组成。为了提高block的读取性能,chunkserver还将block缓存在内存中。Block index和block的cache都采用LRU的策略淘汰。
在我之前的博文中也介绍过,想提高效率必须做做减法,针对专门的场景做特定的优化(详见 这位创造Github冠军项目的老男人,堪称10倍程序员本尊),在笔者看到OCEANBASE的设计时,最令我印象深刻的是其chunkserver自带的缓存功能,而且根据之前的最佳实践分享,与甲骨文等传统数据库不同,OCEANBASE与应用之间是不需要加redius缓存的,所以这点应该是阿里做的比传统数据库厂商厉害的地方。阿里的数据库之所以快基本上可以归功于这个chunkserver的功劳,下面我们就来进行一下代码解读。
chunkserver的设计与相关代码
其chunkserver的基础流程图如下:
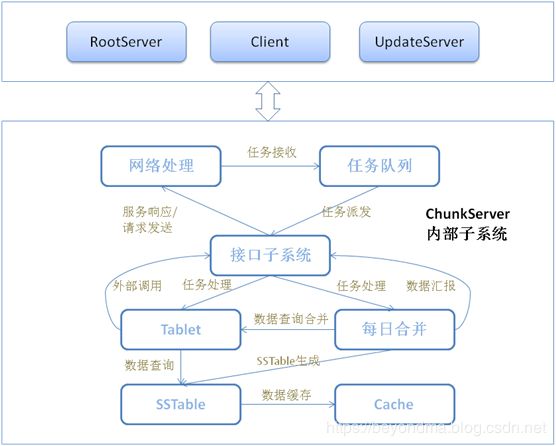
可以看到负责数据查找和读取的部分是SSTable所以下面我们再对这部分做一下详细的代码解读,为便于查找,SSTable会建立一些信息来索引数据,比如相关key在SSTable中的偏移,IndexBuilder即用来建立这些信息。这部分的相关代码在https://github.com/alibaba/oceanbase/tree/master/oceanbase_0.4/src/sstable/ob_sstable_block_index_builder.cpp
其中重点函数是这个生成入口的函数add_entry,这些都写的比较清楚,大家可以看一下。
int ObSSTableBlockIndexBuilder::add_entry(const uint64_t table_id,
const uint64_t column_group_id,
const ObRowkey &key,
const int32_t record_size)
{
int ret = OB_SUCCESS;
ObSSTableBlockIndexItem index_item;
//合法性校验
if (record_size < 0 || key.get_obj_cnt() <= 0 || NULL == key.get_obj_ptr()
|| table_id == OB_INVALID_ID || table_id == 0 || OB_INVALID_ID == column_group_id)
{
TBSYS_LOG(WARN, "invalid param, table_id=%lu, key_len=%ld,"
"key_ptr=%p, record_size=%d, column_group_id=%lu",
table_id, key.get_obj_cnt(), key.get_obj_ptr(), record_size, column_group_id);
ret = OB_ERROR;
}
if (OB_SUCCESS == ret)
{
//初始化,后面也是用以下的参数进行序列化的
index_item.rowkey_column_count_ = static_cast(key.get_obj_cnt());
index_item.column_group_id_ = static_cast(column_group_id);
index_item.table_id_ = static_cast(table_id);
index_item.block_record_size_ = record_size;
index_item.block_end_key_size_ = static_cast(key.get_serialize_objs_size());
index_item.reserved_ = 0;
ret = index_items_buf_.add_index_item(index_item);
if (OB_SUCCESS == ret)
{
ret = end_keys_buf_.add_key(key);
if (OB_ERROR == ret)
{
TBSYS_LOG(WARN, "failed to add end key");
}
else
{
index_block_header_.sstable_block_count_++;
}
}
else
{
TBSYS_LOG(WARN, "failed to add index item");
ret = OB_ERROR;
}
}
return ret;
} 和这个函数生成index的函数
int ObSSTableBlockIndexBuilder::build_block_index(const bool use_binary_rowkey,
char* index_block, const int64_t buffer_size, int64_t& index_size)
{
int ret = OB_SUCCESS;
int64_t index_block_size = get_index_block_size();
int64_t index_items_size = get_index_items_size();
int64_t header_size = index_block_header_.get_serialize_size();
int64_t pos = 0;
if (NULL == index_block)
{
TBSYS_LOG(WARN, "invalid param, index_block=%p", index_block);
ret = OB_ERROR;
}
else if (index_block_size == header_size)
{
//no data in index block
ret = OB_ERROR;
}
if (OB_SUCCESS == ret)
{
index_block_header_.end_key_char_stream_offset_
= static_cast(header_size + index_items_size);
// new rowkey obj array format, force set to 1.
index_block_header_.rowkey_flag_ = use_binary_rowkey ? 0 : 1;
if (OB_SUCCESS == index_block_header_.serialize(index_block,
header_size, pos))
{
char* ptr = index_block + pos;
ret = index_items_buf_.get_data(ptr, buffer_size - header_size);
if (OB_SUCCESS == ret)
{
ptr += index_items_size;
ret = end_keys_buf_.get_data(ptr, buffer_size - header_size - index_items_size);
if (OB_SUCCESS == ret)
{
index_size = index_block_size;
}
}
}
else
{
TBSYS_LOG(WARN, "failed to serialize index block header");
ret = OB_ERROR;
}
}
return ret;
} 而且除了索引以外oceanbase还在读取之前添加了一个布隆过滤器,这个设计也比较有意思,Bloom Filter(布隆过滤器)用来判定某一个key是否属于某个集合,他有一定误判概率,如果判定在集合内,不一定在;但是如果判定不在集合内,那么一定不在,这样的操作可以优化很多not in的查询时间。这部分的代码在https://github.com/alibaba/oceanbase/tree/master/oceanbase_0.4/src/common/bloom_filter.h以及
https://github.com/alibaba/oceanbase/tree/master/oceanbase_0.4/src/common/bloom_filter.cpp
这里就不再贴代码了,大家有兴趣可以去上面的链接去读一下相关代码。
后记
随着美国在高科技领域的不断施压,反而倒逼我国之前相对冷清的操作系统、数据库等基础平台领域重新热闹起来,笔者这个C语言的IT老兵感觉目前又焕发第二春,所以我还会继续关注相关领域的进展,后续继续带来代码级的解读。