因未测试其他作者的算法时间和效率,本文不敢自称是最快的,但是速度也可以肯定说是相当快的,在一台I5机器上占用单核的资源处理 3000 * 2000的灰度数据用时约 20ms,并且算法和核心的大小是无关的,即所谓的o(1)算法。
在实现本算法之前,也曾经参考何凯明在暗通道去雾时提出的一篇参考论文中的算法: STREAMING MAXIMUM-MINIMUM FILTER USING NO MORE THAN THREE COMPARISONS PER ELEMENT ,这篇文章所描述的过程也是o(1)的,速度也相当快,不过还是不够快。
我曾经自己构思了一个想法,也是基于行列分离的,在速度上比上文的代码又要快,并且也是o(1)算法,但是算法速度和图片的内容有关,比如对一个图进行了一次算法后,再次对结果执行相同的算法,可能后一次就要慢很多,这和我改进的算法本身有关系,但是这种情况是很少见的。
本文所要介绍的算法也是在很久以前就看到过的,但是一直没有引起我的重视,其对应的参考论文是 A fast algorithm for local minimum and maximum filters on rectangular and octagonal kernels ,当时觉得论文的实现起来可能没有我自己构思的快,也就没有去深究。
论文的实现步骤也是基于行列分离的,即先进行行方向的一维运算,然后再对结果进行列方向的一维计算,具体的理论描述大家去研究论文吧。
那其实论文的核心就是下面这个图。

In表示一维行方向的输入数据,g/h分别运算过程中的两个中间数据,和输入数据大小一样。
如上图所示,我们假定需要进行计算的核大小为R,那么将一行分为多个大小为 D =(2R+1) 的分段,例如图中R=2, D=5 ,对每一个分段进行预处理,其中 x 号位置存放的是箭头所在直线段上的点中的最大值(最小值),如此处理得到 g 和 h 两个数组,那么对于某个点(索引为I),其半径R内的最大(小)值为:Max/ Min(g(I+R),h(I-R))。
过程好简单。
我们拿一组数据来说明上述过程,假如一行数据如下,我们要进行膨胀操作(最大值),核半径为2:
In: 20 12 35 9 10 7 32 15 20 45 28
对应的g/h为:
g: 20 20 35 35 35 7 32 32 32 45 45
h: 35 35 35 10 9 45 45 45 45 45 28
如果我们要计算第4个点的半径为2的最大值,则对应 g(I+R) = g(4+2) = 7, h(I-R)=h(4-2)=35, 得到结果为max(7,35) = 35;
如果我们要计算第6个点的半径为2的最大值,则对应 g(I+R) = g(6+2) = 32, h(I-R)=h(6-2)=10, 得到结果为max(32,10) = 32;
注意上面索引是以1位小标计数起点的。
边缘处理:
注意到在边缘处,比如左侧边缘,当要计算的点的索引小于R时,这时h值是无效的,而在右侧边缘,g值是无法取到的,但是仔细观察,问题很简单,还拿上述数据为例,如果要计算索引为2处半径为2的最值,由于h(2-2)是超出索引的(前面说了本例以1为下标起点),因此不能用前述的方式,那我们回归到问题的本质,计算2处半径为2的最值,就是计算max(In(1), In(2), In(3), In(4)), 而这个值不就是g数据中索引为2+2处的数据吗,在这之前就已经帮我们算法,直接取值就可以了。
在数据尾部(右侧),情况有所不同,我们应该从H中取值。
从上述的分析可知,这个算法有个特性,就是半径越大,算法的耗时会越小,因为对边缘的处理只需要拷贝数据,而没有了更多的计算,可能很多人不信吧。
算法实现:
有了上面的描述,要实现一个快速的腐蚀或膨胀算法相信对部分来说应该是一件非常容易的事情,先行方向处理,在列方向,好简单。
最近我是迷上了SSE算法优化,于是就思考了这个算法的SSE优化,以前在看SSE的函数时,就一直在想_mm_max_epi8/_mm_min_epi8这种一次性能获取16个字节数据的最值的函数是否能用在腐蚀和膨胀上,不过由于他们是对两个连续数据的比较,在行方向上是难以运用的,但是如果数据比较是列方向上,那不就可以使用了吗。
我们上述算法就有列方向的比较,不就有了用武之地了。
首先,我们给出在列方向更新g值/h值在每个分段范围内的C语言实现代码,比如获取g值大概的代码如下:
memcpy(G + StartY * ValidDataLength, Src + StartY * Stride, ValidDataLength); for (int Y = StartY + 1; Y < EndY; Y++) { unsigned char *LinePS = Src + Y * Stride; unsigned char *LinePD = G + Y * ValidDataLength; unsigned char *LinePD = G + (Y - 1) * ValidDataLength; for (int X = 0; X < ValidDataLength; X++) { LinePD[X] = IM_Max(LinePS[X], LinePL[X]); } }
StartY为计算好的分段范围的起点,EndY为分段范围的终点,我们观察g数据的规律,知道在分段范围内第一行的最大值就是数据本身,而后面的则是和前一行比较得到结果。
很明显:
for (int X = 0; X < Width * Channel; X++) { LinePD[X] = IM_Max(LinePS[X], LinePL[X]); }
这个代码很容易向量化,如果这里是浮点运算,编译器会直接帮我们向量处理的,但是对于字节,似乎编译器还没有那么智能,我们自己手动来向量化,代码如下:
memcpy(G + StartY * ValidDataLength, Dest + StartY * ValidDataLength, ValidDataLength); // 每段G数据第一行就是原始的数据 for (int Y = StartY + 1; Y < EndY; Y++) { unsigned char *LinePS = Dest + Y * ValidDataLength; unsigned char *LinePD = G + Y * ValidDataLength; unsigned char *LinePL = G + (Y - 1) * ValidDataLength; for (int X = 0; X < Block * BlockSize; X += BlockSize) { _mm_storeu_si128((__m128i *)(LinePD + X), _mm_max_epu8(_mm_loadu_si128((__m128i *)(LinePS + X)), _mm_loadu_si128((__m128i *)(LinePL + X)))); } for (int X = Block * BlockSize; X < ValidDataLength; X++) { LinePD[X] = IM_Max(LinePS[X], LinePL[X]); } }
其中BlockSize = 16, Block = ValidDataLength / BlockSize;
这段代码很简单,对于h的处理也是类似的道理。
当我们获得了g,h的数据后,后面的处理过程的C代码也很简单:
for (int Y = Radius; Y < IM_Min(BlockV * Size - Radius, Width); Y++) // 这些位于中间的数据是符合 G+Radius 和 R - Radius 取大的要求的 { unsigned char *LinePG = G + IM_Min(Y + Radius, Width - 1) * Width; unsigned char *LinePH = H + (Y - Radius) * ValidDataLength; unsigned char *LinePD = T + Y * ValidDataLength;for (int X = 0; X < ValidDataLength; X++) { LinePD[X] = IM_Max(LinePG[X], LinePH[X]); } }
又是同样的道理,内部的for循环可直接用SSE代替。
但是这里只是对列方向进行处理,行方向有没有可能用SSE做处理呢,可以肯定的说,绝对可以,但是除非你非常有耐心,以为其中各种pack和unpack或者shuffle会让你疯掉,而且最后的效率也许还不如直接使用普通的C语言。
那么如何处理呢,我想大家肯定能想到转置,确实,对数据进行转置后再进行列方向的处理,然后再转置回来就相当于对原数据的行方向处理。
关于转置,一直也是个耗时的过程,但是我在图像转置的SSE优化(支持8位、24位、32位),提速4-6倍 一文中提到了利用SSE实现高速的转置操作,利用它去实现本文的流程则非常靠谱。
那么我们贴出整体的大部分处理代码:
垂直方向的核心:
int IM_Vert_MaxFilter(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Radius) { int Channel = Stride / Width; if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_INVALIDPARAMETER; // 从节省内存的角度考虑,可以只需要两倍额外的内存 unsigned char *G = (unsigned char *)malloc(Height * Width * Channel * sizeof(unsigned char)); unsigned char *H = (unsigned char *)malloc(Height * Width * Channel * sizeof(unsigned char)); if ((G == NULL) || (H == NULL)) { if (G != NULL) free(G); if (H != NULL) free(H); return IM_STATUS_OUTOFMEMORY; } // 垂直方向处理 int Size = Radius * 2 + 1, ValidDataLength = Width * Channel; int BlockSize = 16, Block = ValidDataLength / BlockSize; int BlockV = ((Height % Size) == 0 ? Height / Size : (Height / Size) + 1); for (int Index = 0; Index < BlockV; Index++) { int StartY = Index * Size, EndY = IM_Min(Index * Size + Size, Height); memcpy(G + StartY * ValidDataLength, Src + StartY * Stride, ValidDataLength); // 每段G数据第一行就是原始的数据 for (int Y = StartY + 1; Y < EndY; Y++) { unsigned char *LinePS = Src + Y * Stride; unsigned char *LinePD = G + Y * ValidDataLength; unsigned char *LinePL = G + (Y - 1) * ValidDataLength; for (int X = 0; X < Block * BlockSize; X += BlockSize) { _mm_storeu_si128((__m128i *)(LinePD + X), _mm_max_epu8(_mm_loadu_si128((__m128i *)(LinePS + X)), _mm_loadu_si128((__m128i *)(LinePL + X)))); } for (int X = Block * BlockSize; X < ValidDataLength; X++) { LinePD[X] = IM_Max(LinePS[X], LinePL[X]); } } memcpy(H + StartY * ValidDataLength, G + (EndY - 1) * ValidDataLength, ValidDataLength); // 每段H数据的第一行就是对应G数据的最后一行 memcpy(H + (EndY - 1) * ValidDataLength, Src + (EndY - 1) * Stride, ValidDataLength); // 每段H数据的最后一行就是原始的数据 for (int Y = EndY - 2; Y > StartY; Y--) // 注意循环次数的改变 { unsigned char *LinePS = Src + Y * Stride; unsigned char *LinePD = H + Y * ValidDataLength; unsigned char *LinePL = H + (Y + 1) * ValidDataLength; for (int X = 0; X < Block * BlockSize; X += BlockSize) { _mm_storeu_si128((__m128i *)(LinePD + X), _mm_max_epu8(_mm_loadu_si128((__m128i *)(LinePS + X)), _mm_loadu_si128((__m128i *)(LinePL + X)))); } for (int X = Block * BlockSize; X < ValidDataLength; X++) { LinePD[X] = IM_Max(LinePS[X], LinePL[X]); } } // 针对最值算法,在列方向最后一块不是Size大小时,后面的数据只能是重复边缘像素,这样后面跟的G/H值和Height - 1大小是相同的 } // 整个的数据分为三个部分,[0, Radius]为第一组,[Radius, BlockV * Size - Radius]为第二组,[BlockV * Size - Radius, BlockV * Size]为第三组, // 第一组数据的结果取G中[Radius, 2 * Radius]的值,第二组数据取G + Radius和H - Radius中的小值,第三组取H - Radius的值。 // 最顶部的一半数据,此时的H数据无效 // // 此处删除若干代码 // for (int Y = Radius; Y < IM_Min(BlockV * Size - Radius, Height); Y++) // 这些位于中间的数据是符合 G + Radius 和 R - Radius 取大的要求的 { unsigned char *LinePG = G + IM_Min(Y + Radius, Height - 1) * ValidDataLength; // 有可能超出范围的 unsigned char *LinePH = H + (Y - Radius) * ValidDataLength; unsigned char *LinePD = Dest + Y * Stride; for (int X = 0; X < Block * BlockSize; X += BlockSize) { _mm_storeu_si128((__m128i *)(LinePD + X), _mm_max_epu8(_mm_loadu_si128((__m128i *)(LinePG + X)), _mm_loadu_si128((__m128i *)(LinePH + X)))); } for (int X = Block * BlockSize; X < ValidDataLength; X++) { LinePD[X] = IM_Max(LinePG[X], LinePH[X]); } } // 最底部的一半数据,此时的G数据无用 // // 此处删除若干代码 // free(G); free(H); return IM_STATUS_OK; }
综合的调用:
int IM_MaxFilter(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Radius) { int Channel = Stride / Width; if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER; if ((Channel != 1) && (Channel != 3) && (Channel != 4)) return IM_STATUS_INVALIDPARAMETER; int Status = IM_STATUS_OK; unsigned char *T = (unsigned char *)malloc(Height * Stride * sizeof(unsigned char)); if (T == NULL) return IM_STATUS_OUTOFMEMORY; Status = IM_Vert_MaxFilter(Src, T, Width, Height, Stride, Radius); if (Status != IM_STATUS_OK) goto FreeMemory; Status = IM_Transpose(T, Dest, Width, Height, Stride, Height, Width, Height * Channel); // 转置,注意Dest我只用了Height * Channel的数据 if (Status != IM_STATUS_OK) goto FreeMemory; Status = IM_Vert_MaxFilter(Dest, T, Height, Width, Height * Channel, Radius); if (Status != IM_STATUS_OK) goto FreeMemory; Status = IM_Transpose(T, Dest, Height, Width, Height * Channel, Width, Height, Stride); FreeMemory: free(T); return Status; }
上面代码中还有很多细节,包括分块尾部不完整数据的处理,大家可以自己理解。
有两处删除了部分代码,删除的代码是很容易补上去的,因为我不喜欢我的代码被别人直接复制黏贴。
进一步的分析:
由上面的代码可以看到,要实现整个的过程,我们需要原图3倍大小的额外内存,那么是否有降低这个的可能性呢,是有的,在处理列方向时,我们可以一次性只处理16列或32列,这样g/h数据只各需要Height * 16(32) * sizeof(unsigned char)大小的内存,而且这样做还有一个优势就是在每个分段内部比较时,由于更新的内容较少,可以用一个xmm寄存器保存最值得临时结果,这样就不用去加载上一行的内存数据,少了很多次内存读写的过程,一个简单的示例代码如下所示:
unsigned char *LinePS = Src + StartY * Stride + X; unsigned char *LinePD = G + StartY * 32; __m128i Max1 = _mm_setzero_si128(), Max2 = _mm_setzero_si128(); // 这样写能减少一次内存加载 for (int Y = StartY; Y < EndY; Y++) { Max1 = _mm_max_epu8(_mm_loadu_si128((__m128i *)(LinePS + 0)), Max1); // 或者使用一条AVX指令 Max2 = _mm_max_epu8(_mm_loadu_si128((__m128i *)(LinePS + 16)), Max2); _mm_store_si128((__m128i *)(LinePD + 0), Max1); _mm_store_si128((__m128i *)(LinePD + 16), Max2); LinePS += Stride; LinePD += 32; }
在我的笔记本中测试,这个的速度要比上面的版本还快一点,并且有占用了更少的内存,一举两得啊。
欢迎大家能提供更快速的算法的实现思路。
本文Demo下载地址: http://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar,里面的所有算法都是基于SSE实现的。
如果觉得本文对你有帮助,请为本文点个赞。
2019.4.26日更新:
在本文的评论里有网友提出该文的速度还是不够快,比起商业软件还有很大的差距,一直未找到良方,最近有网友说他做的比我这个速度要快,其提到了不需要完全转置。虽未提到代码层面的东西,但是这种事情是一点就通的,要实现起来还是很容易的。
比起全局转置,局部转置可以只需要分配很少的内存,从速度方面考虑,我们在进行了垂直方向的优化后,就要进行水平方向处理,此时,我每次转置32行(或其他16的倍数),然后利用垂直方向的处理技巧处理转置后数据的垂直方向最值,处理完成后在转置到水平方向对应的32行数据中,至于不能被32行整除的那一部分,就用普通的方式处理了。
此种优化后,我们惊喜的发现,速度较之前有2到3倍的提高,如下图所示:
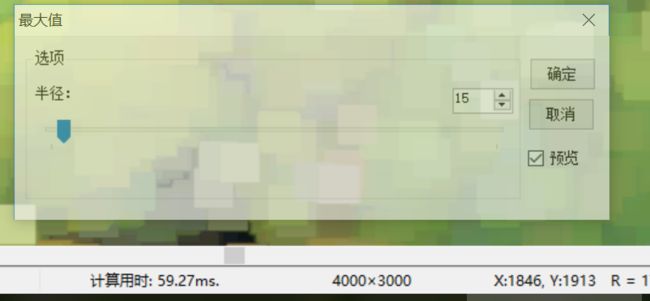
其实,整体来看,修改后的代码计算量上并没有什么减少,那主要耗时降低了,其核心在于减少了内存的Cache Miss,这种技巧在很多算法中也可以加以推广。
最后,我们还注意到一个问题,表面上看垂直方向的代码更为简介,流程也少那些转置的过程,但是最后实测垂直处理的时间和水平处理的时间的占比约为内存·6:4,分析认为这个的主要原因是在垂直方向处理时图比较大,连续访问垂直方向的内存,Cache miss比较多,而水平方向因为是分块处理的,中间用到的临时内存访问时基本无啥Cache miss(宽度为32的临时区都是连续访问的)。
修改后的算法对于评论区里博友提到的4096X8192大小的的灰度图,其耗时大概在70ms,比其说的商业软件的速度还是要慢一倍的。在Opencv中,使用cvErode函数,发现他也非常非常的快,和我这里的速度旗鼓相当,有的时候还快点,查看其代码,发现他核心的地方是调用hal:morph实现的,但是HAL硬件加速层到底是个啥家伙,实在是搞不清楚。
