一、前言
Hashgraph 算法最早是在 2016 年由 Leemon Baird 博士发表的一篇论文“
The Swirlds Hashgraph Consensus Algorithm: Fair, Fast, Byzantine Fault Tolerance”(https://swirlds.com/downloads/SWIRLDS-TR-2016-01.pdf)”中公开,
根据其介绍,Hashgraph 算法实现了异步拜占庭容错(ABFT),因而能容纳非常高的吞吐量并能非常快速的处理交易(官网提供的数据显示,在真实环境下可以达到惊人的 250k TPS)。
二、简介
Hashgraph 是一种异步拜占庭容错算法(ABFT),它跟我们目前常见的 PBFT 算法最大的不同就是它是完全异步的。我们知道 PBFT 算法能支撑的网络规模是非常有限的最大原因就 PBFT 模型的通信复杂度是 O(N^2),随着节点数量的增加,需要通信的消息数量呈指数级别的上升。而 Hashgraph 突破性的抛弃 PBFT 中使用的消息同步机制,使用异步 BFT,通过保证最终确定性来确保算法的高效和安全。
Hashgraph 采用的是 DAG 数据结构,这跟当前的很多开源链(比如 Iota,byteball, nano 等)是类似的,因为它们都采用 DAG 作为底层数据结构模型。但是 Hashgraph 最特别的一点是,它无需中心权威节点,而是依靠独特的 Gossip about Gossip 和 Virtual Vote 两大机制来保证了算法可以在纯异步的环境中高效运行,并且通过绝对多数(超过 2/3 节点)强可见(强引用)机制来保证了共识结果的正确性(安全)。
Hashgraph 算法是一种拜占庭容错算法,它要求节点数量是相对固定的(总量为 N 需要预先设定),这样的话,它就可以通过大于 2/3 忠诚节点的比例原则来达到拜占庭容错。这跟当前公链模型下(比如 DAG 主链,POW,POS 等)这些算法在达到共识的条件上有一些区别,所以更适用于私链(或联盟链)。但是,由于其独特的性质(在保证去中心化的同时不需要繁重的工作量证明),Hashgraph 在未来的公链也有相当潜在的使用价值。
最后,再介绍一下 Hashgraph 跟其他开源项目在运作模式上的区别。
根据原作者发布的白皮书介绍,Hashgraph 仅是一个算法的名字,它既不是区块链项目(比如比特币,以太坊这种完整的可运行的系统),也不是开源的。它是由发明它的 Leemon Baird 博士所创建的 Swirlds, Inc 公司负责掌控,并运营在 Hedera 项目(https://www.hedera.com)之下。Swirlds 公司对该算法申请了专利并进行了很强的技术保护,它致力于在企业之间以合作的方式来运作和使用基于 Hashgraph 开发的应用。
从这里我们可以大致看到,Hashgraph 是按照一个相对传统的方式在运作。虽然其核心算法的源代码并不公开,它还是做出了一定程度的开放来使得整个区块链社区和开发者受益,比如对外提供 SDK(https://dev.hashgraph.com/)。由于 Hashgraph 算法是用 Java 和 LISP 实现的,因此很多基于 JVM 的语言都可以在其之上构建应用程序。当然,社区的开发者也基于 Hashgraph 公开的算法(论文)实现了许多其他语言的版本(比如 Go,Python, Javascript 等),由于算法的简洁和优雅,已经有越来越多的开发者被吸引。
三、算法原理
介绍完了 Hashgraph 的相关背景,我们接下来进入主题,也即算法原理。
实际上,算法的大部分内容在论文中都有介绍,不过,毕竟论文发表的时间早,其中难免缺失许多细节。因此,Leemon 博士在其发表之后的数年时间内又不断对该算法做了更多更细致的描述和改进。在 Youtube 上也有它对该算法的一个长篇介绍,不过很多人看完仍然表示似懂非懂,不好理解。因此,这篇文章致力于把算法用更易懂的方式解释清楚。
在介绍算法之前,先了解论文中所提出的几个基本概念,比如绝对多数(Super majority)和事件(Event)
绝对多数
Super majority 很好理解,就是指超过三分之二的节点数量。事件
Event 是 Hashgraph 中最基本的元素和概念,它跟我们常见的区块链(比如比特币)中的 Block 概念是类似的。Event 由每个节点自行创建,它主要包含四类元素:交易集合,时间戳,以及对两个 Parent Events 的引用哈希。

在传统的区块链中,新产生的区块只能是只能有一个先导区块的,而在 Hashgraph 中,每个 Event 必须要链接两个 parent Events,其中一个必须是自己,而另一个则是收到的其他任意节点发来最新的 Event。
我们来对比一下传统区块链的结构和 Hashgraph 的结构之间的区别,如下:
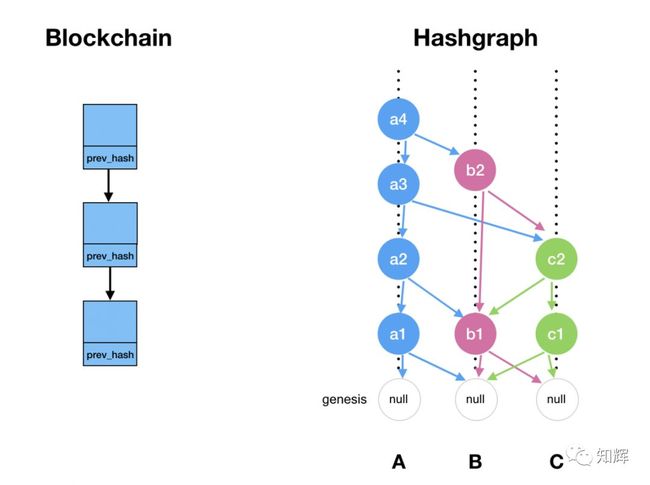
Hashgraph 算法的核心技术点是两个部分:谣言算法(Gossip about Gossip)和 虚拟投票(Virtual Voting)。
接下来,我会一步一步详细介绍!
Gossip About Gossip
Hashgraph 共识的机制和 hashgraph 结构的构建是通过 Gossip 过程来完成的(更多关于 Gossip 机制的介绍,可以参考我这篇文章:“P2P 网络核心技术:Gossip 协议”)。
Gossip 简单来说就是,节点随机选择一个可以连接的邻节点,向其发送一条信息(Event)。而 Gossip about Gossip 则是,收到 gossip 信息的节点,对该 gossip 信息进行签名,并且再把该签名打包进一个新的信息中,并随机发送给网络中的任一节点。这样,每个节点发出的 Gossip 信息都包含了对其收到的前一个 Gossip 信息的签名验证,实际上就是做了一个见证(Witness)工作。
注意这里的 Gossip 过程是非常简单的,收到 Event 信息的节点可以向任意一个或多个节点继续 Gossip 新的 Event。每一次 Gossip 都是对前一次信息的背书和见证。
Local hashgraph copy
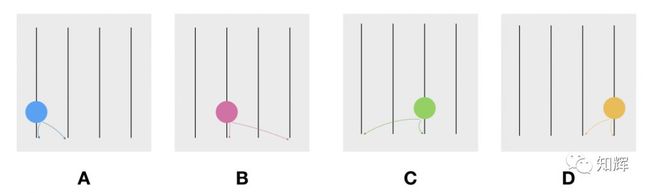
我们用小写的 hashgraph 表示该算法底层使用的数据结构,参与共识的每个节点都会保存一份完整的 hashgraph 副本图,初始时(genesis),每个节点上的这个副本图都是空的,当开始有节点产生 Event 之后,就会在自己的 hashgraph 副本图上进行记录。
比如,每个节点都创建第一个 Event 时,他们各自的副本图如下:
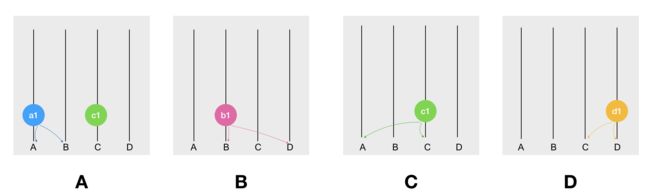
当 A 收到 C 发来的 Event 时,A 就会更新本地的 hashgraph 副本,如下:
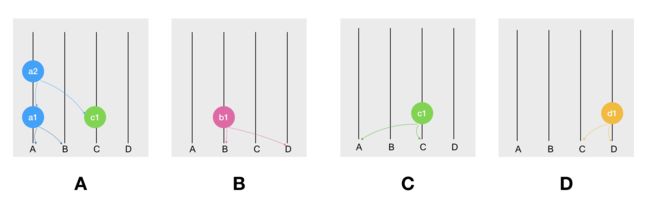
同时,A 还会基于 a1 和 c1 创建一个新的 Event,并 Gossip 出去,如下:
假设刚才在 A 收到 C 的 Event 时,C 也收到了 D 的 Event,那么各个节点的 hashgraph 副本图则会显示如下:
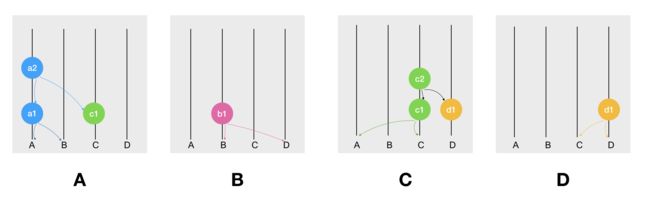
某个时间点之后,大家都收到了彼此发给对方的消息
可见,在节点相互 Gossip 通信的过程中,它们各自 hashgraph 副本的内容都不尽相同,但是有一点非常重要的就是,每个节点都会忠实的记录自己所创建的所有 Events。
比如上图中的节点 A 和 B,A 记录了自己所创建的所有 Events,即 a1 和 a2,而 B 同样记录了自己所有的 Events,b1 和 b2。但是 A 缺少 B 的所有 Events,而 B 则缺少 A 的最新 Event a2。
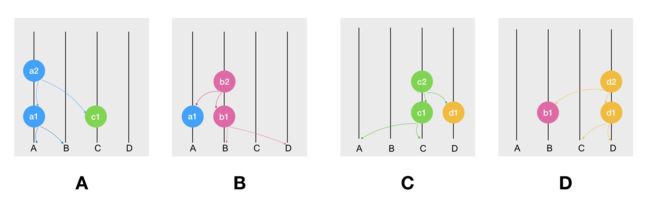
当 A 准备把 a2 发给(gossip)给 B ,如下:
并且,A 准备更新自己副本上 B 这部分的数据时,发现自己缺少 B 这部分前序的数据,因此,B 会把它的历史数据同步(Sync)给 A。而 B 的副本上由于已经有 a1 了,因此在收到 a2 之后无需再同步。
最终,hashgraph 就会更新成如下状态:
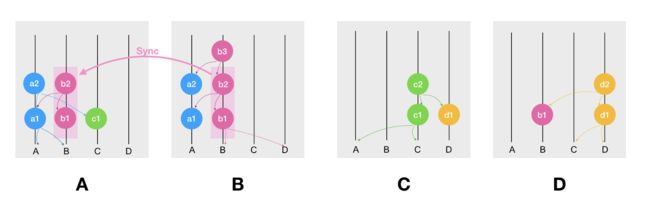
现在,我们对于 Gossip 过程和副本结构有了一个初步的认识,接下来,我们来了解 Hashgraph 算法中定义了哪些状态
可见
由于 hashgraph 中,所有 events 都会引用两个 parent events,因此,如果一个 child event y 可以回溯到某个 ancestor event x,那么就说 y 可见 x。
而且,同一个节点产生的事件,后续事件总是可见先前所有事件。
如下:
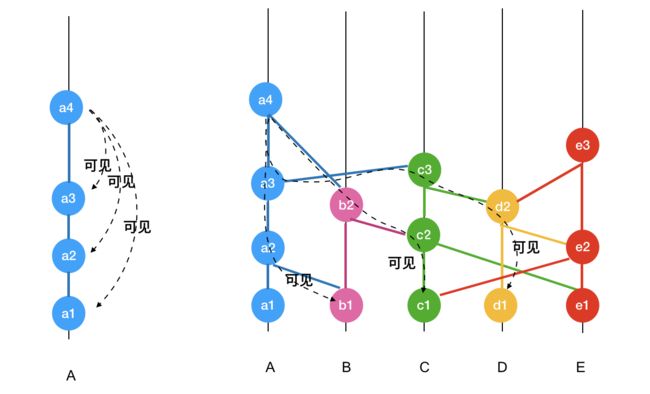
强可见
当事件 Y 能找到事件 X 的所有路径中跨越了绝对多数的节点,那么事件 Y 强可见事件 X。白皮书中提到经过数学论证可以保证两个强可见的节点在虚拟投票时能获得一致的结果
比如下图,想要判断 b5 是否强可见 c1,
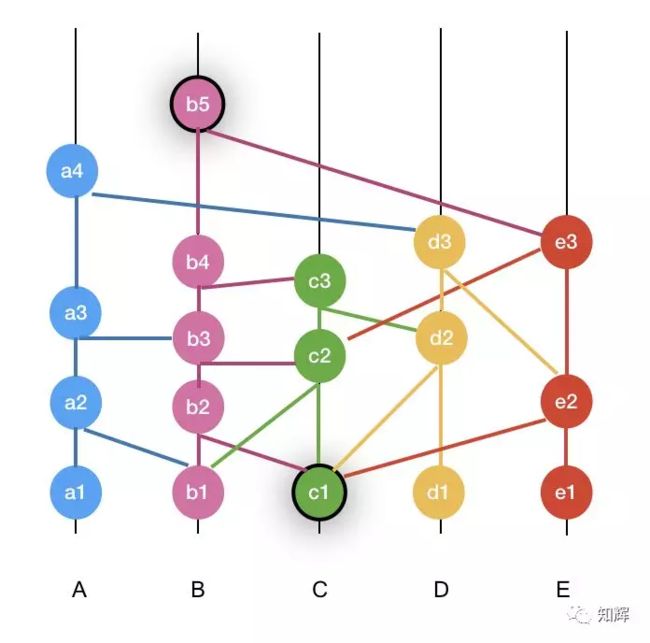
我们需要做的就是,把所有从 b5 能可见 c1 的路径都找出来,如果这些路径集合中,能够包含超过 2/3 的节点(也就是要包含至少 4 个节点),那么就说 b5 强可见 c1。
如下:
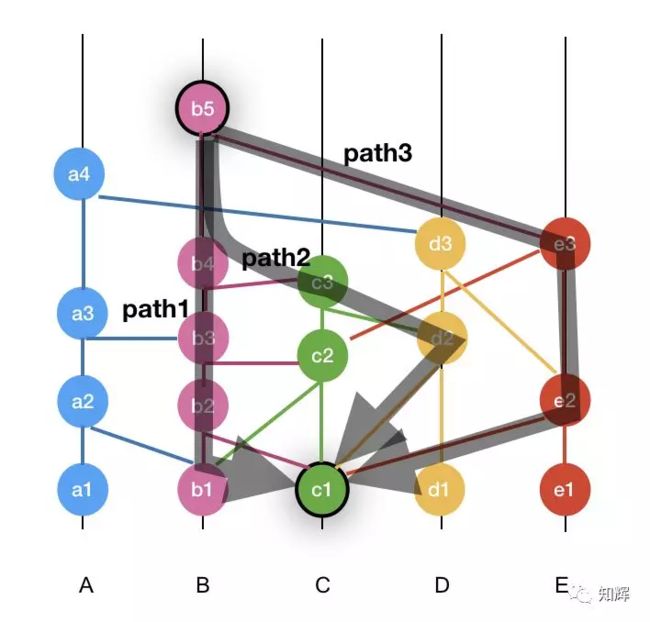
可以看到,b5 有 3 条路径都能可见 c1,这 3 天路径经过的节点分别是,path1: (B, C),path2:(B, D, C), path3(B, E, C),
三天路径一共经过了 B, C, D, E 4 个节点,满足超过 2/3 节点的要求,因此,可以确认事件 b5 强可见事件 c1。
轮次 Round
在 Hashgraph 中,根据事件所处的可见状态,把他们分为不同的轮次(Round)。
当一个事件强可见绝对多数节点上的先前事件时,我们就说该事件在一个新的轮次上,记为 R。
我们通过一个示意图来理解轮次的概念
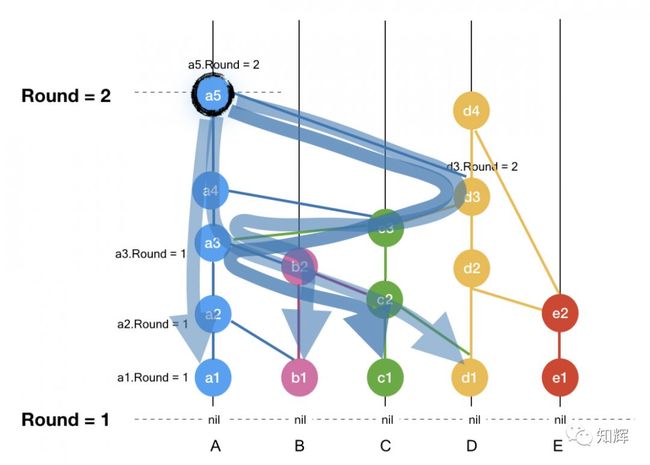
上图中,事件 a5 强可见了 R 轮的 a1, b1, c1, d1 共 4 个事件,也就是说强可见了绝对多数节点的第 R 轮的事件,因此,a5 就在一个新的轮次 R + 1 上。
创建轮
所谓的创建轮(Creation Round),就是当一个事件被创建时,它所在的轮次。通常,一个事件被创建时,它会被立即赋予一个轮次号,跟其父事件是在同一个轮次一样。也就是说,如果同节点的父事件是 R 轮,那该事件被创建时也是在第 R 轮,它的创建轮就是 R 轮。
比如,上图中,初始(Genisis)情况下,所有节点的状态都是相同的,把当前状态定义为第 R 轮,并且 R = 1。后续创建的事件都是在第 R 轮的。
接收轮(Receive Round)很好理解,就是当某个事件强可见超过 2/3 节点的本轮或者上一轮的事件时,这个事件就达到了一个新的轮次,这个轮次就是他的接收轮。如下图:
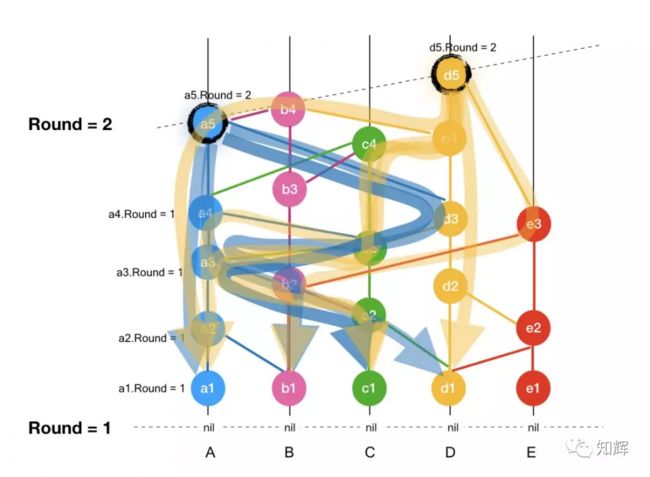
从上图中,我们可以看到,当 a5 和 d5 被创建时,它们的创建轮是第 R 轮,而当它们能够强可见绝对多数节点的第 R 轮的见证人事件(即 a1, b1, c1, d1)时,它的接收轮就变为 R + 1 轮,也就是说,a5 和 d5 都变成 R + 1 轮的事件了,并且,在它们之后创建的子孙事件都在 R + 1 轮。
这里需要注意的是:如果事件 a5 只能强可见 R 轮某节点的见证人时,a5 的轮次是不会增加的,依然为此在 R 轮。只有当其强可见绝对多数节点的第 R 轮的见证人,它的轮次才变为 R + 1 轮。
见证人和知名见证人
见证人(Witness),就是第 R 轮所创建的第一个事件。比如上图的 a1,b1,c1, d1 和 e1,它们都是各自节点的见证人事件。
知名见证人(Famous Witness),当 R 轮的见证人事件被 R + 1 轮的多数(超过 2/3)见证人强可见时,它就是知名见证人事件。
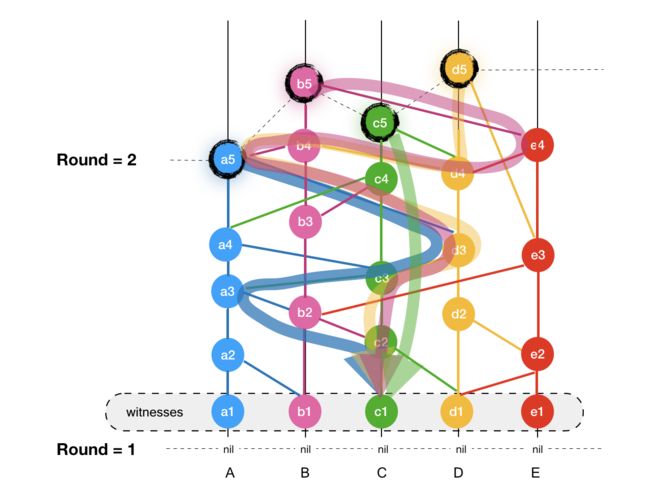
由上图我们可以看到,c1 被 R +1 轮的大部分见证人事件强可见,因此 c1 就是知名见证人。
我们注意到这里暗含了一个强约束条件,就是 R + 1 轮的见证人事件,这意味着 [a5, b5, c5, d5] 这几个事件必然是强可见大部分节点的第 R 轮见证人事件的,但不必然强可见 c1(比如他们都强可见 [a1, b1, d1, e1] 这 4 个见证人事件。所以,要判断 c1 是否是知名见证人,就必须要求 R + 1 轮的大部分事件都强可见 c1,一旦满足,说明 c1 就是知名见证人了,知名见证人意味着不可更改,这时候系统就可以对该事件进行 commit。
虚拟投票(Virtual Vote)
上述 Event 状态变迁和系统状态变迁的过程其实也包含了投票的过程,投票是在上述状态变迁过程中完成的。
根据上述的算法介绍,我们知道一个 Event 的状态变迁过程是这样的:
可见 -> 强可见某祖先 Event -> 强可见绝对多数节点的祖先 Events -> 轮次增加(即 Round + 1) -> 大多数 R+1 轮 Witness 强可见 R 轮某个 witness -> R 轮该 Witness 成为 famous witness -> commit。
如图:
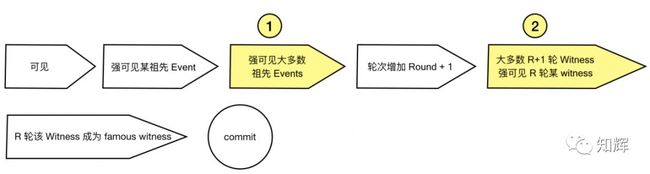
虚拟投票实际上就是指上述两个黄色部分。它主要是分为两个步骤来进行的,① 处相当于 Pre-Vote 过程,这里其实是确定投票委员会成员,如果一个事件强可见大多数 witness,那么它对某 witness 的票就有效。而 ② 处则是 Pre-Commit 过程,收集投票委员会对某个祖先 Event 所投的票,如果票数超过 2/3,那么就可以把该 Event 标记为 Famous,也就是不可更改了。接下来只需要 commit 就行了。
注:R + 1 轮的 Witness 只会对 R 轮的 Witness 投票,R 轮 Witness 后续的 Events 不会收到投票。 Witness 是指 R 轮创建的第一个 Event,如下:
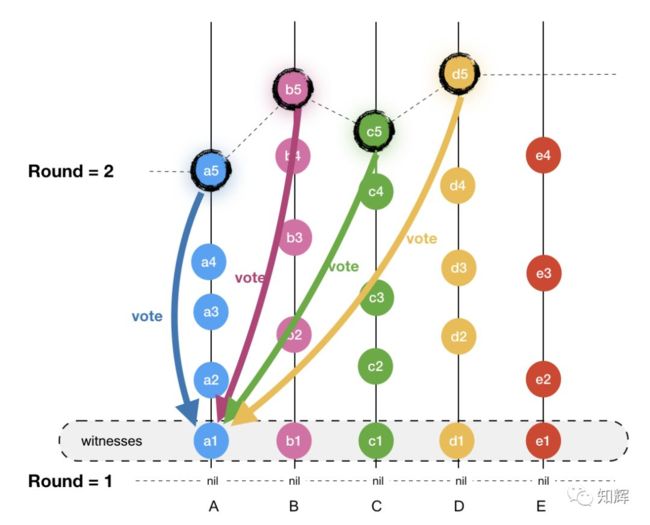
我们来看一下想要把 R 轮的 c1 标记为 Famous 需要经过哪些步骤:
- 1)找出每个节点所有满足 R + 1 轮的 Events
这是一个对每个节点的各 Event 进行不断回溯验证的过程。 - 2)判断每个节点中,R + 1 的 Event 是否强可见 c1,如果强可见,那就相当于投了一票赞成票(Yes)。
- 3)计算 Vote 数量,如果超过 2/3 的 Event 都投票 Yes。就把 c1 标记为 famous。
实际上,计票过程是在 R + 2 轮进行的。因为即使 R + 1 轮所有 Event 都强可见 c1,它们彼此之间也互相不知道对方的投票情况。因此,必须由下一轮的 Event 来收集大家的投票结果。
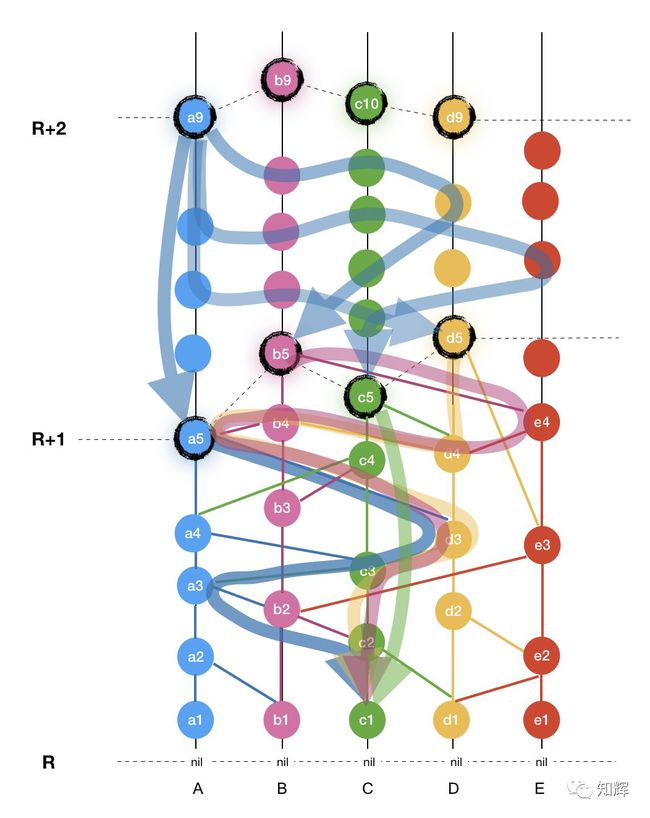
由上图可见,R + 1 轮的 [a5, b5, c5, d5] 以绝对多数的比例对 c1 形成了强可见状态,使得 c1 满足知名见证人条件。R+2 轮上的每个见证人则对 R+1 轮进行收集投票。如图,a9 强可见了 R+1 轮的这 4 个强可见 c1 的事件,因为已经超过绝对多数,因此 a9 可以立即确认 c1 事件,也就是 c1 已经达到全网共识而且不可更改。
提示:Hashgraph 根据数学理论证明,任何一个 R+2 轮见证人如果对投票结果做出了决定,那么这个结果就是全网的结论,如果这轮见证人无法做出决定,就由下一轮见证人计票决定,直到得出确切结论。
事实上,R + 2 轮这个收集投票的过程只是一个学习共识结果并进行提交的过程,因为一旦知名见证人被确定,剩下的过程就只是各个节点把这个结果进行提交了。
接收轮次和共识时间戳
一旦某个轮次确定了所有的(or 绝对多数)知名见证人,就可以为这一轮次中的其他普通事件(non-witness)确定接收轮次和共识时间戳(Consensus timestamp)。
如果一个事件被某轮的所有知名见证人(知名见证人数量必须超过 2/3)都可见,就说它的接收轮为这些知名见证人所在的轮次。
比如,第 R + 1 轮的所有知名见证人都已经得到确认,如果这些知名见证人都可见某个祖先事件,那么就说这个祖先事件的接收轮为 R + 1。
比如下图,假定 a5, b5, c5, d5 都是 R = 2 轮的知名见证人,它们都可见 a3 事件,我们就说 a3 在 R = 2 轮被接受。而对于 b4 来说,只有 b5 可见它,其他见证人并不可见它,因此,它的接收轮还不确定,只能等待后续轮次的见证人满足可见的条件,才能确定它的接收轮。
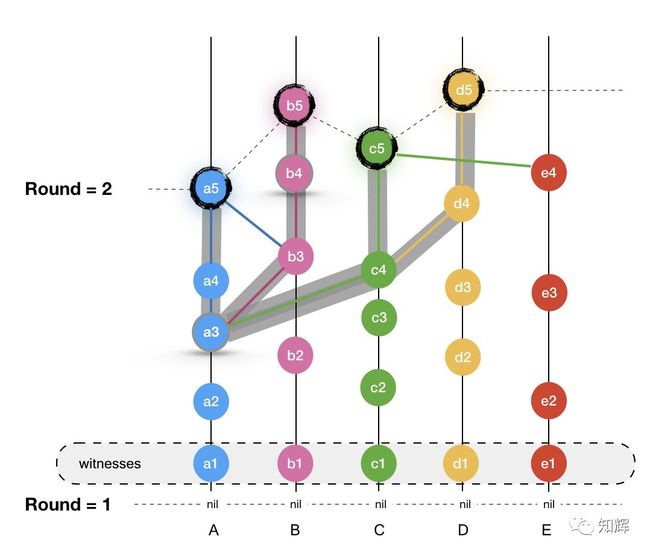
现在假定我们有一个 Event x,其接收轮为 R + 1,我们想要确定其在所有 event 中的 timestamp。
Hashgraph 采用的方法是,先找出各个节点中的可见 Event x 的最早 Events,然后把它们的 timestamps 集合取中位数作为 x 最终的 timestamp。比如,找到节点 A 中最早可见 x 的 Event,样,找到节点 B,C, D 中最早可见 x 的 Event 。对于 A 来说,最早可见 x 的就是 x 自己,而对 B, C, D 来说,最早可见可以是任意 Event。
为了便于理解,我画了一个示意图来描述,如下:
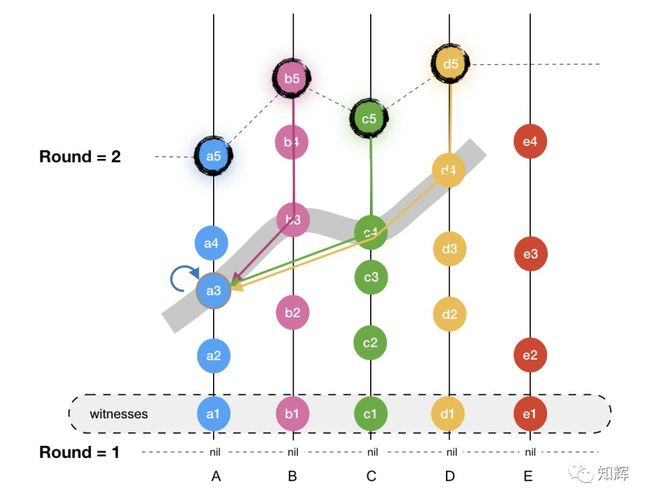
想要确定 a3 的 timestamp,我们从各个可见它的见证人节点中,查找最早可见 a3 的 events。
如上图,A 节点最早可见 a3 的时间就是 a3 自己,而 B 节点最早可见 a3 的则是 b3,同理得到 c4 和 d4。
这样,我们就得到一个 timestamp 集合:[a3, b3, c4, d4],取它们的中位数,就得到一个基准 timestamp,把它作为 a3 的真实 timestamp。
根据相同的做法,我们可以得到其他所有 Events 的 timestamp,也就是说我们可以得到一个 Total order。
Tie breaker
当然,仅有 timestamp 可能还无法确定 Event 的先后顺序,因为很有可能两个 events 会有相同的 timestamp。所以还需要一些其他条件和规则来约定顺序。
在 Hashgraph 中,是按照如下规则来排序的
Round received
Median timestamp
Extended median timestamp
whitened signature
全文完!
本文欢迎转载,请务必注明出处。
相关阅读:
P2P 网络核心技术:Gossip 协议
欢迎关注微信公众号“知辉”,
搜索“deliverit”或
扫描二维码
